深入理解浏览器的渲染原理
前言
页面内容快速加载和流畅的交互是用户希望得到的Web体验,因此,我们前端开发者应力争实现这两个目标。了解浏览器的工作原理有助于我们更好的优化网页性能。本文会深入讲解关于浏览器渲染网页中的各个步骤和细节。
1、浏览器环境中的JS引擎
我们拿Chrome举例子,Chrome浏览器内置了解析JavaScript代码的V8引擎,我们每打开一个网页,就是打开了一个浏览器进程,进程内部就可以有很多的线程,JS解析引擎就是其中一个,这也正是众所周知的JavaScript的解析器特点——单线程。也就是说同一时间它只能做一件事,如果当前做的这件事被堵住了,后面的事情就做不了了。
2、阻塞与异步任务
在浏览器里面,我们的JS代码的顺利执行非常重要,单线程的JS代码一旦被花费很长时间的任务阻塞,网页就会出大问题,所以在JavaScript中有着异步任务的设计,当你需要完成一些过一会儿才需要结果的任务时,你可以将它添加到异步队列中去,这样它就不会阻塞你的JavaScript代码的后续执行,有关于JavaScript的运行机制,可以看我的JS事件循环机制这篇文章。
3、浏览器解析网页的相关进程
我们知道浏览器作为一个进程,其中运行着很多线程,什么管插件的啊,管UI的啊,管用户数据、书签的等等,我们不需要考虑那么多其它额外的线程,在渲染网页的过程中,比较核心的是以下几个:
-
浏览器GUI渲染线程
这个线程的主要功能是解析HTML文档,解析CSS文档,构建DOM树和CSSOM树,也负责调用它们两个合成的Render Tree去渲染内容。它还负责页面的回流(Layout)与重绘(Painting),使像素真正渲染在页面上。
-
JS解析线程
主要负责解析JavaScript脚本,它会一直不断的等待就绪任务队列里新任务的到来;一个浏览器进程里只有一个Js解析线程。
-
网络线程
负责去网络上请求需要的资源,比如外链的JS,CSS文件,还有图片字体资源等。每一个新开的网络请求都会打开一个网络线程。
我们都知道JS的运行是可以改变DOM结构和样式的,为了避免刚渲染完DOM就被JS修改了又要重新渲染这种浪费性能的情况发生,GUI渲染进程在JS解析器执行JavaScript脚本的时候,会被阻塞,直到JS引擎任务队列空闲才会继续解析渲染工作。也就是说GUI渲染线程和JS解析线程是互斥的。
4、关键渲染路径
现在我们来看一下,当浏览器拿到HTML,CSS,JavaScript之后,需要经过哪些步骤,把代码渲染成页面,整个渲染流程如下图:
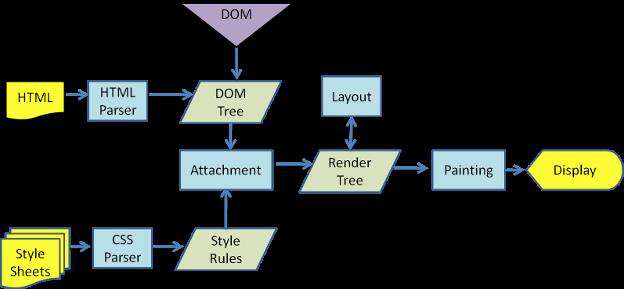
4.1、构建DOM树
从服务器拿到返回的HTML文件,浏览器就开始解析HTML代码,并将其转化成DOM树,DOM树上的每一个节点都保存着我们需要的信息。
4.2、构建CSSOM树
解析CSS样式文件,构建生成CSSOM树,这上面的节点里保存了对应节点解析CSS规则后最后计算出来的最终样式信息,也就是Computed Style。
4.3、Render Tree合成
当我们得到DOM树和CSSOM树之后,把他们结合就能得到渲染树。
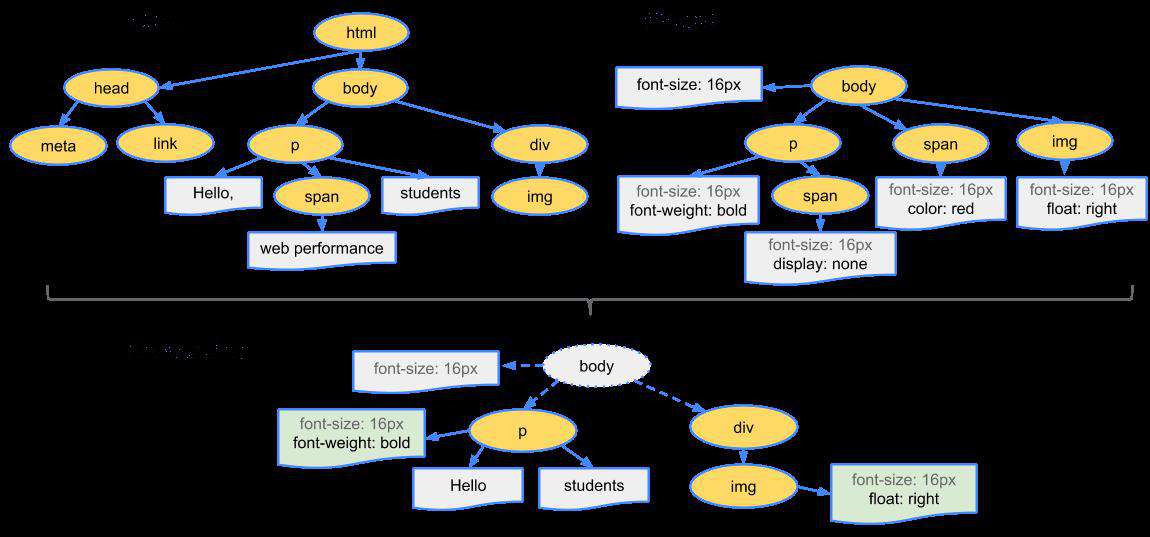
4.4、回流(layout)
一旦渲染树被构建,布局变成了可能。布局取决于屏幕的尺寸。布局这个步骤决定了在哪里和如何在页面上放置元素,决定了每个元素的宽和高,以及他们之间的相关性,于是根据渲染树,进行回流(layout),得到节点在屏幕上的几何信息。
4.5、重绘(painting)
最后一步是将像素绘制在屏幕上。一旦渲染树创建并且布局完成,像素就可以被绘制在屏幕上。
5、解析渲染中的阻塞
在正常的网页中,上面的关键渲染路径一般不太可能直接顺利的一次执行完毕,因为在上面的过程中,我们还有JS没有考虑进去,前面说了,JS解析线程会与GUI渲染线程互斥,当解析JS的时候,关键渲染路径就会被停下。所以,接下来我就讲解关于渲染中的阻塞问题。
5.1、JS执行阻塞DOM构建渲染
由于浏览器会对JS的执行做最坏的打算,于是当我们JS解析线程工作时,GUI渲染线程就会被阻塞,等待JS执行完毕再继续进行;前面说到了HTLM的解析也是GUI渲染线程的工作,这就意味着当JS执行的时候,浏览器将暂停HTML的解析与DOM树的构建。
这也是为什么我们常常建议把JS放在body底部,其中一个原因就是为了不阻塞DOM树的构建,这也是为什么放在body上面的JS常常取不到想要的DOM节点,因为这个时候DOM树的构建还没有完成就被阻塞了。
但是把JS直接放在底部也是会有一些问题的,放在底部也就表明最后被解析到,最后被加载,如果你的页面依赖JS来渲染一些内容,会导致页面的完整渲染被延后,我后面preload那里会讲到如何解决这个问题。
5.2、JS加载阻塞全部
不同于加载外部的CSS文件,加载外部的CSS文件并不会阻塞HTML的解析和DOM树的构建(加载文件交给网络线程),顶多延缓首次渲染(拿不到CSS就不会进行渲染),但是加载外部的JS文件不一样,浏览器不清楚这里面的代码是否会修改已经构建的DOM节点,于是会做出最坏的打算,等待JS文件加载完毕->运行完毕,才会继续解析HTML。
5.3、CSS阻塞DOM树渲染
在4中我们学习到关键渲染路径中CSSOM的构建是非常关键的一步,也就是说当CSSOM构建没有完成的时候,即使DOM树已经构建完毕,浏览器也不会进行DOM树的渲染,但是从4中的图可以看出,CSS和HTML的解析构建是可以并行的,所以CSS的解析构建不会阻塞DOM树的构建,只是如5.2中所说的那样,会延缓DOM树的首次渲染。
所以为了尽可能快点让页面进行渲染,我们应该尽快提供所需要的CSS。
5.4、CSS解析构建阻塞JS执行
我们都知道JavaScript是非常强大的,它们不仅可以读取和修改 DOM 属性,还可以读取和修改 CSSOM 属性。那么当CSS构建CSSOM的同时又出现了JS去修改CSSOM的情况呢?显然,我们现在遇到了竞态问题。
如果浏览器尚未完成 CSSOM 的下载和构建,而我们却想在此时运行脚本,会怎样?答案很简单,对性能不利:浏览器将延迟脚本执行,直至其完成 CSSOM 的下载和构建。
我举一个简单的例子,看下面这段代码:
<!DOCTYPE html>
<html>
<head>
<title>test</title>
<script>
let startDate = new Date()
document.addEventListener('DOMContentLoaded', function() {
console.log('DOMContentLoaded');
})
</script>
<link href="https://cdn.bootcss.com/bootstrap/4.0.0-alpha.6/css/bootstrap.css" rel="stylesheet">
<script>
let endDate = new Date()
console.log('run time:' + (endDate -startDate) + 'ms')
</script>
</head>
<body>
<h1>test</h1>
</body>
</html>
我在这里补充一个知识,在浏览器渲染页面的过程中,会触发两个个事件,DOMContentLoaded,它代表着DOM树已经构建完成,另一个是,onLoad,它代表页面已经全部加载完毕,包括css,js,图片等。
我们在浏览器上运行这个网页,结果如下:

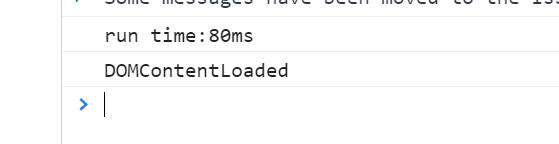
可以看到,位于css资源其后的JS脚本,等到css资源加载完毕之后JS才恢复执行,JS的执行又会阻塞DOM树的构建,所以等到JS执行完毕之后,DOM树才构建完成,触发DOMContentLoaded事件。
6、preload 预加载
在上面我介绍了页面加载资源的时候,关于浏览器出于性能考虑作出的一些顺序的调整(利用阻塞,来达到一定顺序执行的目的)。但是有些时候,有些资源就是我们网页即刻需要的,考虑下面这个例子:
<!DOCTYPE html>
<html>
<head>
<script src="/js/index.js"></script>
<script src="/js/menu.js"></script>
<script src="/js/main.js"></script>
</head>
<body>
<div id=app></div>
</body>
</html>
当我们解析到 index.js d的时候,我们会去加载它,这是5.2的情况,JS的加载会停止HTML的解析和DOM的构建,于是这个时候浏览器需要等待index.js 加载执行完毕之后,才能继续往后面解析。我们现在来分析一下,当JS加载完毕开始执行后,三个主要线程的情况:
- GUI:被阻塞
- JS解析线程:刚刚加载过来的代码正在被执行
- 网络线程:空闲
很明显在解析执行JS的时候,网络是空闲的,这就有了发挥的空间:我们能不能一边解析执行 js/css,一边去请求下一个(或下一批)资源呢?
对于这种情况,浏览器提供了一个预加载的机制,preload,引用MDN的解释:
我们把上面的代码改成这样:
<!DOCTYPE html>
<html>
<head>
<script src="/js/index.js"></script>
<link src="/js/menu.js" rel=preload as=script></link>
<link src="/js/main.js" rel=preload as=script></link>
</head>
<body>
<div id=app></div>
</body>
</html>
现在页面就可以在解析index.js的同时,继续加载后面两个JS资源,而且这种途径加载JS是不会执行的,也就是说不会阻塞HTML的解析和DOM树的构建,它会把加载的资源放到内存中,然后我们配合5.1中提到的方法,把JS执行放在body底部:
<!DOCTYPE html>
<html>
<head>
<script src="/js/index.js"></script>
<link src="/js/menu.js" rel=preload as=script></link>
<link src="/js/main.js" rel=preload as=script></link>
</head>
<body>
<div id=app></div>
<script src="/js/menu.js"></script>
<script src="/js/main.js"></script>
</body>
</html>
这样当DOM树构建完成,解析到底部的JS时,命中早已经加载好的缓存内容,直接就可以开始执行,不用等待JS的加载,这样就可以有效解决在5.1中提到的把JS放在body底部的问题。
7、prefetch 资源预取
浏览器中还为link标签的rel属性提供了一个值,叫做prefetch。还是取来自MDN上的解释:
我举一个简单的实际场景作为例子来说明——图片懒加载。
当我们浏览网页的时候,没有进入我们视窗的图片往往会做懒加载,以减小首次加载的压力。当我们的页面加载完成之后,还未向下滚动,这个时候其实浏览器就已经是空闲了。正常来说,我们需要等到下面的图片进入我们的视野才开始加载,但是其实我们可以等到页面加载完空闲的时候,就去加载下面的图片。这样当用户滚动下来的时候,懒加载的图片很快就可以从缓存中读出来,大大提高体验。
这就是资源预取,它并不会占用首次加载时的网络资源,也就是如MDN中所说,在浏览器空闲的时候用来加载一些用户将来可能会用到的资源。所以资源预取不会影响首屏渲染,它触发的时机是在onLoad事件触发前一点。
8、预加载扫描器
大家看了上面的所有流程之后,会不会对preload产生一些疑问,preload的提前加载条件是建立在浏览器知道这个link资源是有preload属性的,也就是说,这一行被解析过了。
但是我们在5.2中提到,js的加载会阻塞HTML的解析。让我们回到preload那一节中的例子:
<!DOCTYPE html>
<html>
<head>
<script src="/js/index.js"></script>
<link src="/js/menu.js" rel=preload as=script></link>
<link src="/js/main.js" rel=preload as=script></link>
</head>
<body>
<div id=app></div>
</body>
</html>
我在preload那一节说在解析index.js的时候,后面的preload资源可以被加载,但是考虑到JS解析阻塞HTML解析,浏览器应该不知道后面的link标签是什么情况才对。
在实际的网页中我们打开network观察资源加载情况也可以发现,JS的加载后面的一些资源加载,也是可以被浏览器解析到同时发出请求的,这似乎和我们在5.2中说的有一些矛盾。
但是其实这是浏览器自身的优化机制,并不是如我们想的那样,html文件一被浏览器从服务器下载下来就开始解析的:

可以从时间线上明显看到,从html文件被下载,到第一个资源开始加载,中间还经过了一段时间,这段时间就是预加载扫描器造成的。
引用MDN的解释:
知道了这个我们就能很好的理解为什么JS的加载会阻塞HTML的解析,但其后的资源请求还是可以发出去了,预加载器帮我们提前扫描了外部资源的请求,所以上面那个例子index.js后面的preload早就被预加载器解析了,当然可以正常的提前加载。
结语
本文是我多方面总结浏览器渲染原理之后集合出来的,网上大概很多文章讲述各种方面,但是没有统一在一起讲的,而且很少有讲到预加载器这个东西的文章,中间很长一段时间导致我不能理解为什么浏览器可以提前解析到位于JS加载后面的外部资源。希望这篇文章能帮到你提高网页性能。
原地址->我的博客
参考
juejin.cn/post/684490…
developer.mozilla.org/zh-CN/docs/…
developer.mozilla.org/zh-CN/docs/…
developer.mozilla.org/zh-CN/docs/…
developers.google.com/web/fundame…
常见问题FAQ
- 免费下载或者VIP会员专享资源能否直接商用?
- 本站所有资源版权均属于原作者所有,这里所提供资源均只能用于参考学习用,请勿直接商用。若由于商用引起版权纠纷,一切责任均由使用者承担。更多说明请参考 VIP介绍。
- 提示下载完但解压或打开不了?
- 找不到素材资源介绍文章里的示例图片?
- 模板不会安装或需要功能定制以及二次开发?





发表评论
还没有评论,快来抢沙发吧!