概括
js一共用于其中语言类型,分别是
- number
- string
- boolean
- null
- undefined
- symbol
Undefined类型
唯一值undefined
undefined用于表示声明或者创建了但是还没赋值的变量,任何没有赋值的变量的都是undefined,例如
const var1
console.log(var1) // undefined
console.log(var2) // Uncaught ReferenceError: var2 is not defined
// 未声明的标量只能执行 typeof操作 进行其他操作会报错
const var1
console.log(typeof var1) // undefined
console.log(typeof var2) // undefined
综上,只有显示声明了的变量,在未赋值的情况下,其值为undefined
注意JS中的undefined并不是关键字!!!
Null类型
唯一值null
null表示空指针,即一个空对象的指针。null为关键字。
null与undefined的区别
null用于表示一个空指针,一个变量若赋值为null表示该变量不应该出现赋值操作。一般用来原型链的顶点。undefined表示一个声明了但是还没有赋值的变量,这个变量赋值为undefined仅仅为初始化,后续应该会有相应的赋值操作。
String类型
包含所有用字符组成的字符串
string用于表示字符串,字符串类型的变量是不可以被修改的,怎么理解呢,就是一个字符串类型的变量赋值之后就会有自己的内存空间,当再修改这个变量的时候,步骤是先销毁之前的内存空间,然后再新开一个空间给这个变量,赋新的值。
所有的类型都含有toString()方式,是将一个类型的数据转化为字符串类型,但是有两个例外,那就是undefined和null,这两种类型是没有toString()方法的,调用toString()会报错。如果不清楚变量是否是这两个类型的时候,可以使用String()方式,将其转为字符串。
const a = undefined
const b = null
console.log(String(a)) // 'undefined'
console.log(String(b)) // 'null'
除此之外,在数字转为字符串的时候,调用toString()方法,可传入参数,表示转为多少进制的字符串
const num = 100
num.toString(2) // "1100100"
num.toString(16) // "64"
-
UnicodeUnicode为字符集,它包含世界上绝大多数的字符,而UTF-8为一种编码方式,可视为unicode在计算机上的一种实现方式。utf-8是可变长度的编码方式,范围为1-4个字节。UTF-8 最大的一个特点,就是它是一种变长的编码方式。它可以使用1~4个字节表示一个符号,根据不同的符号而变化字节长度。
UTF-8 的编码规则很简单,只有二条:
1)对于单字节的符号,字节的第一位设为
0,后面7位为这个符号的 Unicode 码。因此对于英语字母,UTF-8 编码和 ASCII 码是相同的。2)对于
n字节的符号(n > 1),第一个字节的前n位都设为1,第n + 1位设为0,后面字节的前两位一律设为10。剩下的没有提及的二进制位,全部为这个符号的 Unicode 码。下表总结了编码规则,字母
x表示可用编码的位。Unicode符号范围 | UTF-8编码方式 (十六进制) | (二进制) ----------------------+--------------------------------------------- 0000 0000-0000 007F | 0xxxxxxx 0000 0080-0000 07FF | 110xxxxx 10xxxxxx 0000 0800-0000 FFFF | 1110xxxx 10xxxxxx 10xxxxxx 0001 0000-0010 FFFF | 11110xxx 10xxxxxx 10xxxxxx 10xxxxxx跟据上表,解读 UTF-8 编码非常简单。如果一个字节的第一位是
0,则这个字节单独就是一个字符;如果第一位是1,则连续有多少个1,就表示当前字符占用多少个字节。下面,还是以汉字
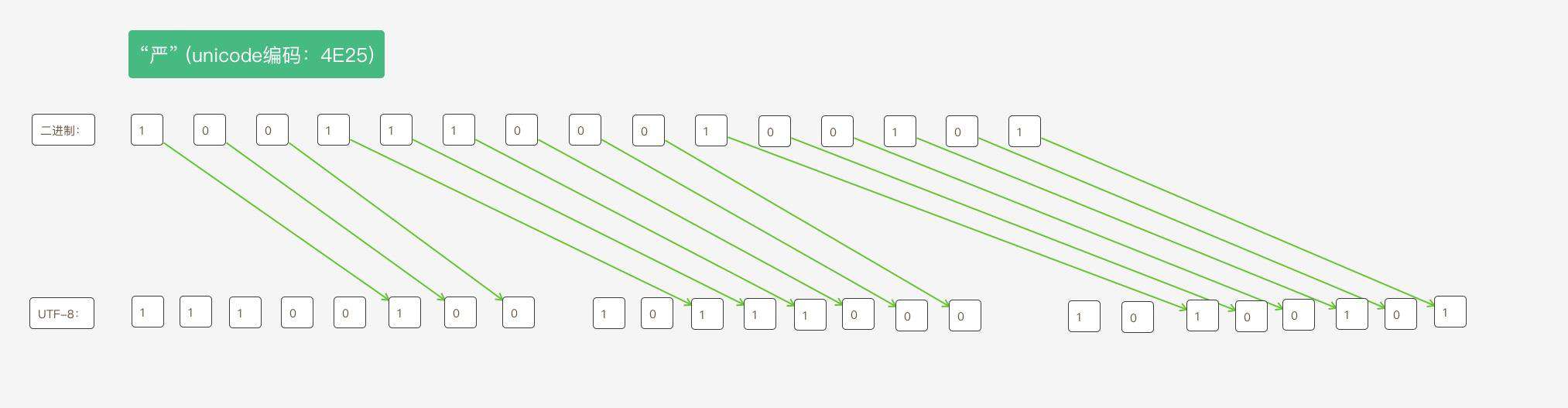
严为例,演示如何实现 UTF-8 编码。严的 Unicode 是4E25(100111000100101),根据上表,可以发现4E25处在第三行的范围内(0000 0800 - 0000 FFFF),因此严的 UTF-8 编码需要三个字节,即格式是1110xxxx 10xxxxxx 10xxxxxx。然后,从严的最后一个二进制位开始,依次从后向前填入格式中的x,多出的位补0。这样就得到了,严的 UTF-8 编码是11100100 10111000 10100101,转换成十六进制就是E4B8A5。下图为转换过程:
Number类型
包含所有数字的类型
对于数字类型,JS中允许的最大、最小值分别为
-
在JavaScript中数字是以
IEEE 754 双精度64位浮点数来存储的,它的表示格式为:(s) * (m) * (2 ^ e)其中s表示符号位,m 表示尾数,占52位,e 表示指数,占11位,根据ECMAScript 5 规范,e 的范围是 [-1074, 971],这样可以得出 js 能表示的最大值为1 * (2^53 - 1) * (2^971) = 1.7976931348623157e+308,而这个值恰好是 Number.MAX_VALUE 的值;同理可以推出 js 能表示的大于 0 的最小值是1 * 1 * (2 ^ -1074) = 5e-324,这个值恰好是 Number.MIN_VALUE 的值。
这里你可能注意到了,m 是 52位,能表示的最大值是2 ^ 52 - 1,可这里为什么是 53 呢?这就涉及到了隐藏位,比如1 * 1.00111100 * 2 ^ -3 中,m 表示的是 1.00111100 中的小数部分“00111100”,整数部分1就是隐藏位,这也就是说,只要指数不全为 0,那么它的隐藏位就是1。这里顺便提一下,js 里整数可以被精确表示的范围是
-2 ^ 53 + 1 ~ 2 ^ 53 - 1。 -
最大值:可用变量
Number.POSITIVE_INFINITY或者直接用Infinity来表示 -
最小值:可用变量
Number.NEGATIVE_INFINITY或者直接用用-Infinity来表示 -
最大最小值范围:
5e-324 ~ 1.7976931348623157e+308 -
在超出上述范围的时候,会转化为
Infinity,-Infinity来表示超出范围的数字
在number类型中有一个特殊的值,NaN(Not a Number),用于表示一个应该返回数值的数却没返回数值的情况,这样避免了系统抛错。isNaN()函数用于判断一个变量和值是否“不是数值”
isNaN("10") // false 可转化为10
isNaN(100) // false 可转化为100
isNaN(null) // false 可转化为0
isNaN(true) // false 可转化为1
isNaN(undefined) // true
isNaN({name:1}) // true
一下情况会得到返回值为NaN
+undefined // NaN
parseInt(undefined) // NaN
由此可见,NaN值会出现错误的类型转换的时候,还有就是NaN不与任何值相等,包括他自身。
-
0.1 + 0.2 不等于 0.3的原因
在JS中,这样得到的值为false
0.1 + 0.2 === 0.3,原因是: 由于在JS中采用的是二进制进行计算首先对于0.1和0.2要转为相应的二进制0.1(10进制) = 0.0 0011 0011 0011 0011 0011 0011 ... (0011循环) 0.2(10进制) = 0.0011 0011 0011 0011 0011 0011 0011 ... (0011循环)js采用的是IEEE 754双精度64位浮点数,最多保存小数点后52位,将上面转化为科学计数法为
// 0.1 e = -4; m = 1.1001100110011001100110011001100110011001100110011010 (52位) // 0.2 e = -3; m = 1.1001100110011001100110011001100110011001100110011010 (52位)两项相加可得到:
e = -2; m = 1.00110011001100110011001100110011001100110011001100111 (53位)此时,长度以及溢出了,最后一下需要四舍五入,四舍五入完之后就变为
e = -2; m = 1.0011001100110011001100110011001100110011001100110100(52位)此时的值已经是不准确了的,将其转为非科学计数法的二进制值为:
0.010011001100110011001100110011001100110011001100110100再将其转化为10进制得到结果为
0.30000000000000004
Symbol
只有唯一值Symbol(),用于表示一个独一无二的值,并且每一个Symbol()都不相等
Symbol() === Symbol() // false
使用场景,比如对一个数组,定义它的id的时候便可以用Symbol()
const arr = []
for(let i = 0; i < 10; i ++) {
arr.push({
uuid: Symbol(),
name: `name ${i}`
})
}
const id = arr[4].uuid // 随便取一个数组元素,就假设地5个元素吧
console.log(...arr.filter(item => item.uuid === id))
// {uuid: Symbol(), name: "name 4"}
Boolean
该类型有两个值,分别为ture和false,在隐式的类型转换的时候true == 1,false == 2
Object
在JS中Object是一种复杂的数据类型,它是一组数据和功能的集合。相对于其他几个类型而言,Object类型的门道就可深了,其他设计到的对象会在之后进行总结。所以在此只说一下Object的底层机制。相对于上面六种基本数据类型,Object类型被称之为复杂类型或者是引用类型。下面这个例子能看出一定的区别。
let str1 = "test"
console.log(str1) // "test"
let str2 = str1
console.log(str2) // "test"
str1 = "hahaha"
console.log(str2) // "test"
// str2 不会因为 str1 的改变而改变
const obj1 = {
name: "zhansan",
age: 18
}
const obj2 = obj1
obj1.name = "lisi"
console.log(obj2) // {name: "lisi", age: 18}
// obj2因为obj1的改变而改变
从上述的例子中可以看出,对于字符串类型的变量str1和str2,str2 不会因为 str1 的改变而改变,而对于引用类型的变量obj1和obj2,却obj2因为obj1的改变而改变。下面来详细讲解一下,基本数据类型和引用类型在内存中的管理方式区别。
首先在计算机的内存之中,分为了栈内存和堆内存,栈内存采用了线性表的储存形式,而堆内存采用的二叉树的数据结构进行存储,关于数据结构的知识在此不详细说了。总之,它们两的特点分别是:
- 栈:读取速度快,并且大小是提前声明好的。
- 堆:读取速度慢,但是大小可以不固定。
所以在js中,六种基本类型的大小是固定,可以直接写入栈中,而复杂类型的大小不固定只有写入堆内存之中,然后把它在堆内存中的指针存放在栈内存中,由此可以解释上面的例子:在str1声明的时候,首先新开一个栈空间,赋值的时候将值"test"写入这一个栈空间,声明str2的时候同理,新开空间写入赋值,所以在str1的内容修改的时候不会影响到str2。但是在来看obj1和obj2,在声明obj1的时候,系统为其在堆内存中开辟了一个动态的内存空间,并且将这块空间的指针赋值到了栈内存中,在声明obj2的时候,同样新开了一块栈空间,但是存入的却是obj1的堆内存指针,所以obj1的值发生了变化了,实际上是obj1的堆内存里面的内容发生了变化,但是二者在栈内存中存储的指针未变,导致了obj1的改变会引起obj2的值变化。
常见问题FAQ
- 免费下载或者VIP会员专享资源能否直接商用?
- 本站所有资源版权均属于原作者所有,这里所提供资源均只能用于参考学习用,请勿直接商用。若由于商用引起版权纠纷,一切责任均由使用者承担。更多说明请参考 VIP介绍。
- 提示下载完但解压或打开不了?
- 找不到素材资源介绍文章里的示例图片?
- 模板不会安装或需要功能定制以及二次开发?



发表评论
还没有评论,快来抢沙发吧!