研究背景
上个月团队很多人都在反馈有个项目打包速度越来越慢,打包发布一次至少要半个小时,这个速度不仅我们接受不了,测试那边也多次反馈发布进度卡在前端,因此对该项目进行了打包优化。
对项目进行 bundle 分析
优化前
 目前线上splitChunks.cacheGroups配置如下:
目前线上splitChunks.cacheGroups配置如下:
{
styles: {
name: 'style',
test: m => m.constructor.name === 'CssModule',
chunks: 'all',
enforce: true,
priority: 40,
},
emcommon: {
name: 'emcommon',
test: module => {
const regs = [/@ant-design/, /@em/, /@bytedesign/];
return regs.some(reg => reg.test(module.context));
},
chunks: 'all',
enforce: true,
priority: 30,
},
byteedu: {
name: 'byteedu',
test: module => {
const regs = [
/@ax/,
/@bridge/,
/axios/,
/lodash/,
/@byted-edu/,
/codemirror/,
/@syl-editor/,
/prosemirror/,
];
return regs.some(reg => reg.test(module.context));
},
chunks: 'all',
enforce: true,
priority: 20,
},
default: {
minChunks: 2,
priority: 1,
chunks: 'all',
reuseExistingChunk: true,
},
};
}
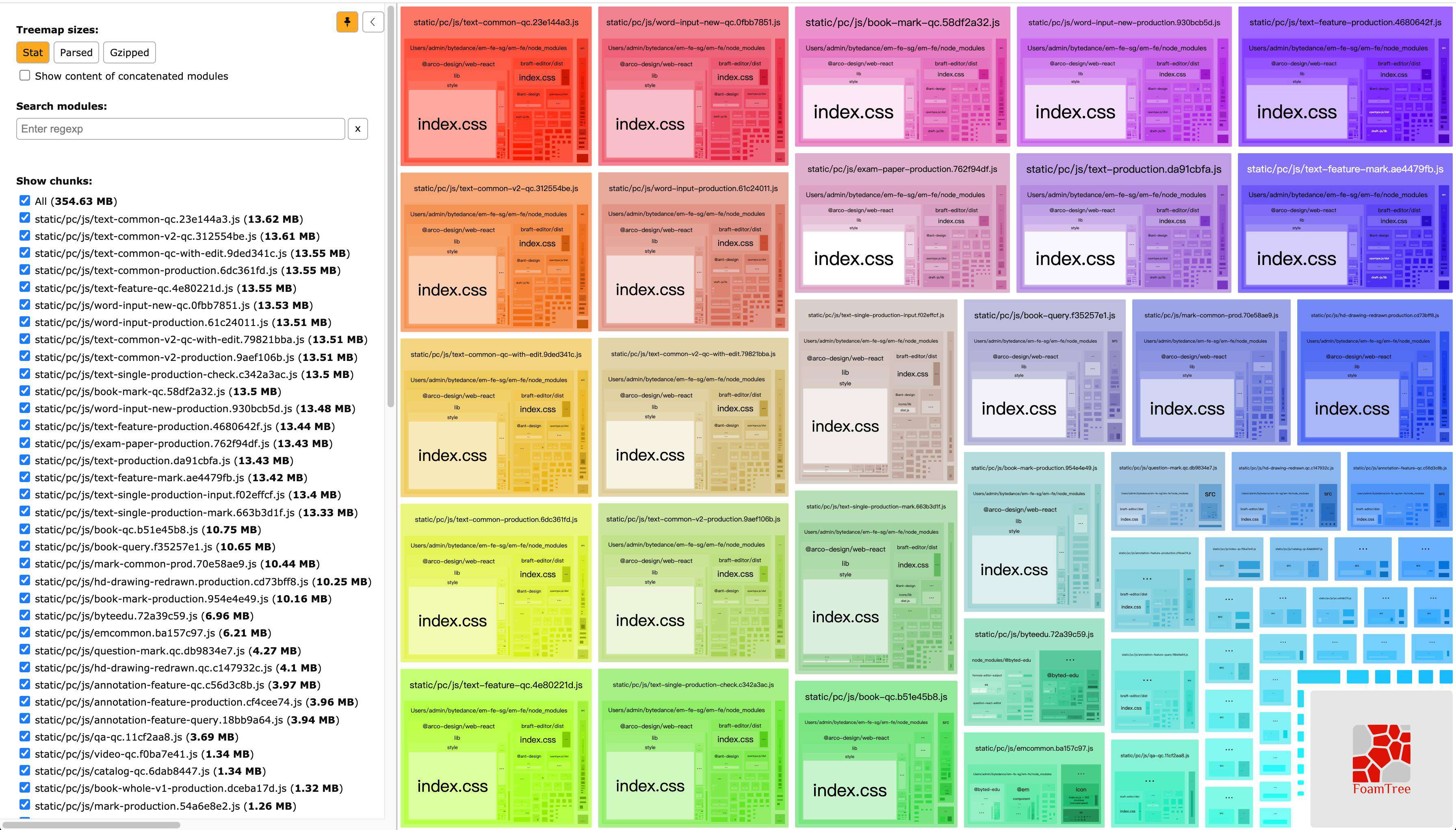
优化前,我们项目在生产环境打包需要14min,通过bundle分析不难发现,并且多个页面都重复打包了arco-design等,很多应该抽离的chunk并没有抽取,导致最终产物极大。这也是打包时间缓慢的重要原因。究其根本原因:default配置没有起作用;按照我们的期望当一个modules被两个或两个以上的chunk共用时,应该就会被提取成独立的chunk,但是结果事与愿违,从bundle分析结果图可以看出arco-design明明被多个chunk共用,却并没有触发该配置。
优化后
定位到问题是default配置没有生效后,我们就针对default进行了一系列的修改,发现当我们将maxAsyncRequests设置为30的时候,default配置起作用了,最终抽离公用chunk,将打包大小降为30M左右,足足缩小了90%。线上打包时间更是缩短到了2.5min左右。 为什么配置maxAsyncRequests才能按照我们的期望进行分包?maxAsyncRequests又是什么?webpack的分包逻辑到底是如何运行的?一系列的问题就需要从webpack的源码出发进行解答了。
default: {
maxAsyncRequests: 30,
minChunks: 2,
priority: 1,
chunks: 'all',
reuseExistingChunk: true,
}
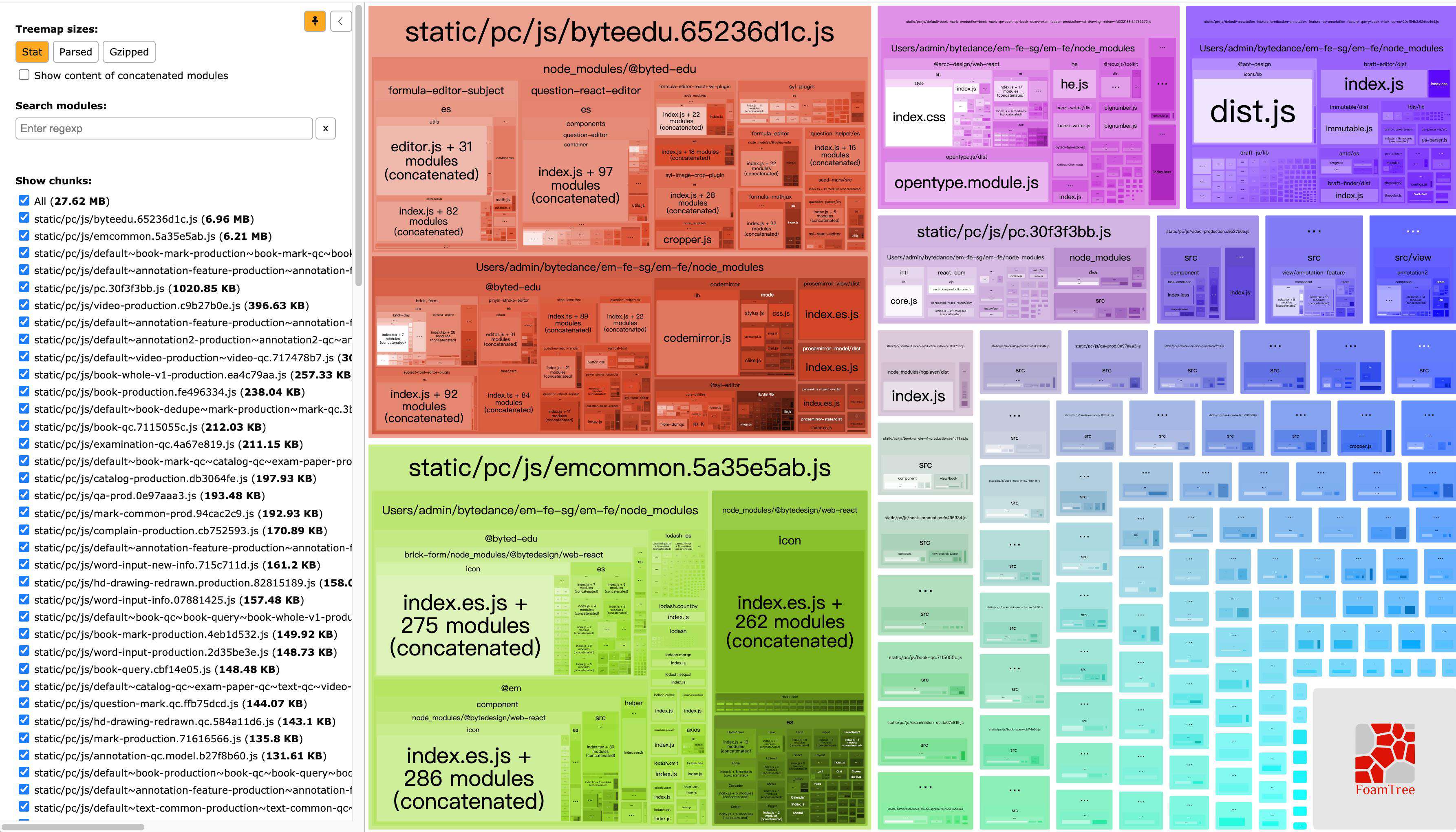
Module和Chunk的关系
由于下文会频繁的出现module和chunk,所以首先单独介绍一下Module和Chunk的关系以及这两者是什么?首先通过一个关系图来理解:
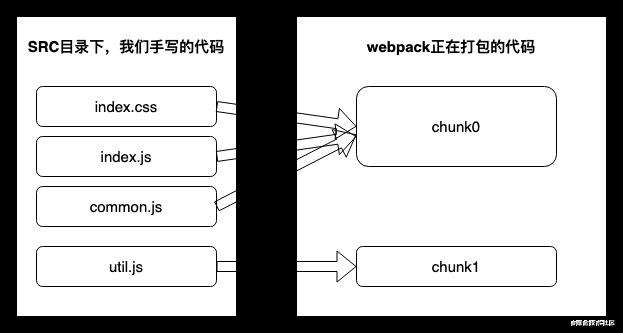
- 对于一份同逻辑的代码,当我们手写下一个一个的文件,它们无论是 ESM 还是 commonJS 或是 AMD,他们都是 module
- 当我们写的 module 源文件传到 webpack 进行打包时,webpack 会根据文件引用关系生成 chunk 文件,webpack 会对这个 chunk 文件进行一些操作
SplitChunksPlugin
我们项目的webpack版本为4.44.2,因此选择这个版本的webpack进行源码解析,进一步了解SplitChunksPlugin如何进行打包的。
SplitChunksPlugin 引入缓存组(cacheGroups)对模块(module)进行分组,每个缓存组根据规则将匹配到的模块分配到代码块(chunk)中,每个缓存组的打包结果可以是单一 chunk,也可以是多个 chunk。webpack 的默认优化就是通过 SplitChunksPlugin 配置实现的,具体可参考官方文档。
默认配置
实际开发会发现哪怕SplitChunksPlugin什么也没有配置,生产环境下还是会按照一些规则进行打包,为什么会这样?这就需要从源码找答案,webpack4有一个文件叫做WebpackOptionsDefaulter.js,在这个文件中有一系列的默认配置。文件的第226行-256行:
this.set("optimization.splitChunks", {});
this.set("optimization.splitChunks.hidePathInfo", "make", options => {
return isProductionLikeMode(options);
});
this.set("optimization.splitChunks.chunks", "async");
this.set("optimization.splitChunks.minSize", "make", options => {
return isProductionLikeMode(options) ? 30000 : 10000;
});
this.set("optimization.splitChunks.minChunks", 1);
this.set("optimization.splitChunks.maxAsyncRequests", "make", options => {
return isProductionLikeMode(options) ? 5 : Infinity;
});
this.set("optimization.splitChunks.automaticNameDelimiter", "~");
this.set("optimization.splitChunks.automaticNameMaxLength", 109);
this.set("optimization.splitChunks.maxInitialRequests", "make", options => {
return isProductionLikeMode(options) ? 3 : Infinity;
});
this.set("optimization.splitChunks.name", true);
this.set("optimization.splitChunks.cacheGroups", {});
this.set("optimization.splitChunks.cacheGroups.default", {
automaticNamePrefix: "",
reuseExistingChunk: true,
minChunks: 2,
priority: -20
});
this.set("optimization.splitChunks.cacheGroups.vendors", {
automaticNamePrefix: "vendors",
test: /[\\/]node_modules[\\/]/,
priority: -10
});
从源码可以看出,SplitChunksPlugin的默认配置在不同的环境下也有变化,比如minSize在生产环境是30000字节,而非生产环境是10000字节。但是官方文档并没有展示这些细节,估计是默认我们最终都会将代码打包到生产环境,但是实际中,我们会在不同模式下切换,因此还是需要注意到这些细节,毕竟开发环境的打包速度也是我们需要关心的。
基本属性
结合前面提到的默认配置的源码,可以确定生产模式下,SplitChunksPlugin的默认配置如下:
splitChunks: {
chunks: "async",
minSize: 30000,
minChunks: 1,
maxAsyncRequests: 5,
maxInitialRequests: 3,
automaticNameDelimiter: '~',
name: true,
cacheGroups: {
vendors: {
test: /[\\/]node_modules[\\/]/,
priority: -10
},
default: {
minChunks: 2,
priority: -20,
reuseExistingChunk: true
}
}
}
这些配置都是什么意义和作用的?一个一个来看:
- chunks: 指的的那些chunks需要进行优化,是一个字符串类型,有效值是:all,async和initial。
async这个值表示按需引入的模块将会被用于优化。initial表示项目中被直接引入的模块将会被用于优化。all顾名思义,表明直接引入和按需引入的模块都会被用于优化。
- minSize: 打包优化完生成的新chunk大小要> 30000字节,否则不生成新chunk。
- minChunks: 共享该module的最小chunk数
- maxAsyncRequests:最多有N个异步加载请求该module
- maxInitialRequests: 一个入口文件可以并行加载的最大文件数量
- automaticNameDelimiter:名字中间的间隔符
- name:chunk的名字,
- 如果设成true,会根据被提取的chunk自动生成。
- 值为 false 时,适合生产模式使用,webpack 会避免对 chunk 进行不必要的命名,以减小打包体积,除了入口 chunk 外,其他 chunk 的名称都由 id 决定,所以最终看到的打包结果是一排数字命名的 js,这也是为啥我们看线上网页请求的资源,总会掺杂一些 0.js,1.js 之类的文件(当然,使资源名为数字 id 的方式不止这一种,懒加载也能轻松办到)。
- 值为 string 时,缓存组最终会打包成一个 chunk,名称就是该 string。此外,当两个缓存组 name 一样,最终会打包在一个 chunk 中。你甚至可以把它设为一个入口的名称,从而将这个入口会移除。
- cacheGroups: 这个就是重点了,我们要切割成的每一个新chunk就是一个cache group。
- test:用来决定提取哪些module,可以接受字符串,正则表达式,或者函数,函数的一个参数为module,第二个参数为引用这个module的chunk(数组)。
- priority:优先级高的chunk为被优先选择(说出来感觉好蠢),优先级一样的话,size大的优先被选择。
- reuseExistingChunk: 当module未变时,是否可以使用之前的chunk。
- 要禁用任何默认缓存组,请将它们设置为
false。例如 default:false
这些规则一旦制定,只有全部满足的模块才会被提取,所以需要根据项目情况合理配置才能达到满意的优化结果。
执行流程
首先看一下wbepack的主题流程:
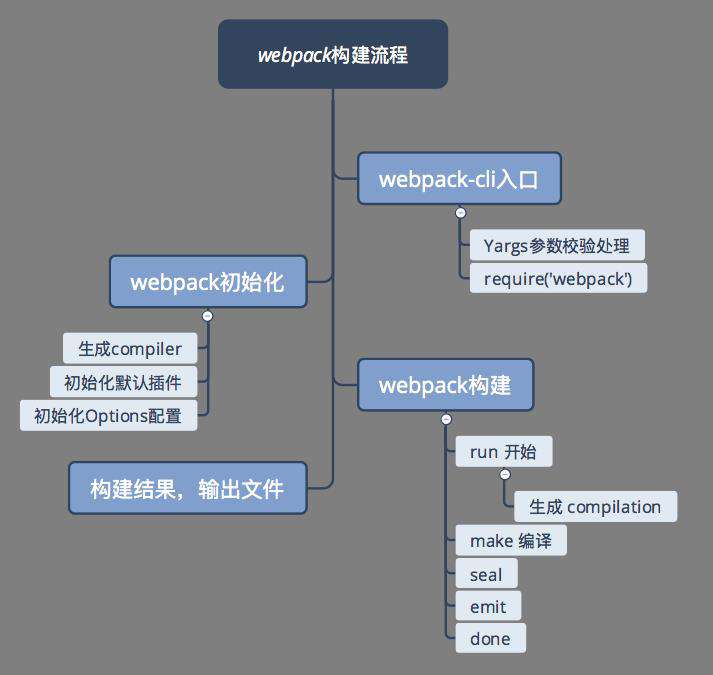 流程图中展示了些核心任务点,简要说明下:
流程图中展示了些核心任务点,简要说明下:
- 通过yargs解析config和shell的配置项
- webpack 初始化过程,首先会根据第一步的 options 生成 compiler 对象,然后初始化 webpack 的内置插件及 options 配置
- run 代表编译的开始,会构建 compilation 对象,用于存储这一次编译过程的所有数据
- make 执行真正的编译构建过程,从入口文件开始,构建模块,直到所有模块创建结束
- seal 生成 chunks,对 chunks 进行一系列的优化操作,并生成要输出的代码
- seal 结束后,Compilation 实例的所有工作到此也全部结束,意味着一次构建过程已经结束
Webpack 插件统一以 apply 方法为入口,然后注册优化事件,apply方法接收一个参数,该参数是webpack初始化过程中生成的compiler 对象的引用,从而可以在回调函数中访问到 compiler 对象。
SplitChunksPlugin逻辑都在 SplitChunksPlugin.js 中:
从源码中可以看到两个重要的对象compiler和compilation,这两个对象是连接plugin和webpack的重要桥梁。官方API
apply(compiler) {
//Compiler 对象包含了 Webpack 环境的所有配置信息,包含options、loaders、plugins等信息。这个对象在 Webpack 启动时被实例化,它是全局唯一的,可以简单地将它理解为 Webpack 实例。
compiler.hooks.thisCompilation.tap("SplitChunksPlugin", compilation => {
//Compilation 对象包含了当前的模块资源、编译生成资源、变化的文件等。当 Webpack 以开发模式运行时,每当检测到一个文件变化,一次新的 Compilation 将被创建。Compilation 对象也提供了很多事件回调供插件做扩展。通过 Compilation 也能读取到 Compiler 对象。
let alreadyOptimized = false;
//当编译开始接受新模块时触发
compilation.hooks.unseal.tap("SplitChunksPlugin", () => {
alreadyOptimized = false;
});
//在块优化阶段的开始时调用。插件可以利用此钩子来执行块优化。
compilation.hooks.optimizeChunksAdvanced.tap(
"SplitChunksPlugin",
chunks => {
//核心代码
}
);
});
}
在编译过程中,SplitChunksPlugin监听了optimizeChunksAdvanced钩子;在块优化阶段的开始时,触发 optimizeChunksAdvanced 事件并传入 chunks,开始代码分割优化过程,所有优化都在 optimizeChunksAdvanced 事件的回调函数中完成。
分块策略执行步骤
回调事件注册好后,接下来是核心的分块策略执行流程,这一块的代码较多,因此根据每块代码的作用,将执行过程分为三步:1、优化前准备阶段;2、模块分组阶段;3、依次检查阶段。
优化前准备阶段
在进行块优化前,首先要定义一些必要的方法和数据结构,在优化过程的每个阶段中都可能使用到这些方法和数据结构,具体流程如图:
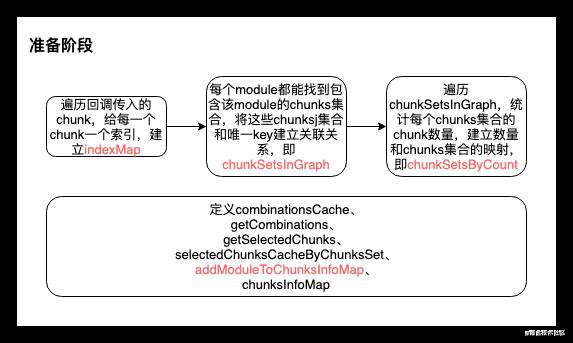
接下来看具体代码,着重是流程图中红色部分:
// 给每个选定的块一个索引(从块中创建字符串)index从1开始递增
const indexMap = new Map();
let index = 1;
for (const chunk of chunks) {
indexMap.set(chunk, index++);
}
// 获取chunks的唯一key,通过上一步的index索引拼接而成,索引数组按从小到大排序。compareNumbers = (a, b) => a - b;
const getKey = chunks => {
return Array.from(chunks, c => indexMap.get(c))
.sort(compareNumbers)
.join();
};
/**
* 块优化的核心就是提取公共的module。所以要为包含某一module的chunks生成一个key值
* 每个module都能找到包含该module的chunks集合(module.chunksIterable),根据chunks集合就可以生成有chunk索引拼接而成的key
* 这样我们就知道每个module在哪些chunk中重复了,这对优化起了关键作用。
* 这里将该key值和这些chunks建立映射关系,存在chunkSetsInGraph中,便于之后通过key值取出这些chunks集合,进行优化。
*/
const chunkSetsInGraph = new Map();
for (const module of compilation.modules) {
const chunksKey = getKey(module.chunksIterable);
if (!chunkSetsInGraph.has(chunksKey)) {
chunkSetsInGraph.set(chunksKey, new Set(module.chunksIterable));
}
}
/**
* 在上一步的代码中,我们知道了每个module在哪些chunks中重复,并存在了chunkSetsInGraph中。这一步统计每个module重复的次数,并将重复次数存在chunkSetsByCount中。
* 这一步是为了匹配minChunks属性,可以根据minChunks(module的最小重复次数)直接找到对应的chunksSet的集合,
* 不符合minChunks的chunks集合会直接排除在优化之外,即该module不会被提取。
* 注意,一个module对应一个chunksSet,一个count对应多个chunksSet,也就对应多个module */
const chunkSetsByCount = new Map();
for (const chunksSet of chunkSetsInGraph.values()) {
// 遍历chunkSetsInGraph,统计每个chunks集合的chunk数量,即每个module的重复次数,建立数量和chunks集合的映射
const count = chunksSet.size;
let array = chunkSetsByCount.get(count);
if (array === undefined) {
array = [];
chunkSetsByCount.set(count, array);
}
array.push(chunksSet);
}
const combinationsCache = new Map(); // Map<string, Set<Chunk>[]>
// 获得可能满足minChunks条件chunks集合,用于后续和minChunks条件比对
const getCombinations = key => {
// 首先通过传入的key拿到chunks集合
const chunksSet = chunkSetsInGraph.get(key);
var array = [chunksSet];
if (chunksSet.size > 1) {
for (const [count, setArray] of chunkSetsByCount) {
//遍历chunkSetsByCount,当chunk集合小于传入key对应的chunk集合时,进入是否时子集的判断。如果是子集则和通过key拿到的集合存在一个数组中,最后返回
if (count < chunksSet.size) {
for (const set of setArray) {
if (isSubset(chunksSet, set)) {
array.push(set);
}
}
}
}
}
return array;
};
// 判断两个chunk集合,后者是否时前者的子集
const isSubset = (bigSet, smallSet) => {
if (bigSet.size < smallSet.size) return false;
for (const item of smallSet) {
if (!bigSet.has(item)) return false;
}
return true;
};
const selectedChunksCacheByChunksSet = new WeakMap();
/**
* 传入chunks和chunks过滤方法,最终返回满足条件的chunk集合和集合key
* 从性能方面考虑,会将通过过滤条件产生的结果与过滤条件、传入的chunk集合一起缓存起来
**/
const getSelectedChunks = (chunks, chunkFilter) => {
// 通过传入的chunks集合,判断是否缓存过,如果没有缓存过则创建缓存
let entry = selectedChunksCacheByChunksSet.get(chunks);
if (entry === undefined) {
entry = new WeakMap();
selectedChunksCacheByChunksSet.set(chunks, entry);
}
/** @type {SelectedChunksResult} */
// 通过缓存条件判断是否有筛选结果,有则直接返回,没有则生成选择结果并缓存
let entry2 = entry.get(chunkFilter);
if (entry2 === undefined) {
/** @type {Chunk[]} */
const selectedChunks = [];
for (const chunk of chunks) {
if (chunkFilter(chunk)) selectedChunks.push(chunk);
}
entry2 = {
chunks: selectedChunks,
key: getKey(selectedChunks)
};
entry.set(chunkFilter, entry2);
}
return entry2;
};
const chunksInfoMap = new Map();
// 关键的Map结构,每一项对应一个分割出来的缓存组,键名为根据name属性生成的key值,键值为该key值对应的modules、chunks和cacheGroup信息对象
const addModuleToChunksInfoMap = (
cacheGroup,
cacheGroupIndex,
selectedChunks,
selectedChunksKey,
module
) => {
// Break if minimum number of chunks is not reached
// 如果选择的chunk集合小于设置的**minChunks,直接返回**
if (selectedChunks.length < cacheGroup.minChunks) return;
// 确定拆分块的名称
const name = cacheGroup.getName(
module,
selectedChunks,
cacheGroup.key
);
// 创建map的key,如果有传入名称,就会以名称作为key,否则用chunk集合生成的key做key
const key =
cacheGroup.key +
(name ? ` name:${name}` : ` chunks:${selectedChunksKey}`);
// 将模块添加到map中
let info = chunksInfoMap.get(key);
if (info === undefined) {
chunksInfoMap.set(
key,
(info = {
modules: new SortableSet(undefined, sortByIdentifier),
cacheGroup,
cacheGroupIndex,
name,
size: 0,
chunks: new Set(),
reuseableChunks: new Set(),
chunksKeys: new Set()
})
);
}
// info.modules是一个set,通过oldSize和添加module之后大size比较,确定要不要更新info的size
const oldSize = info.modules.size;
info.modules.add(module);
if (info.modules.size !== oldSize) {
info.size += module.size();
}
// 同上,info.chunks是一个set,根据chunksKeys的size判断要不要加选中的chunk集合加入info.chunks
const oldChunksKeysSize = info.chunksKeys.size;
info.chunksKeys.add(selectedChunksKey);
if (oldChunksKeysSize !== info.chunksKeys.size) {
for (const chunk of selectedChunks) {
info.chunks.add(chunk);
}
}
};
前面这一块代码都是优化前的准备阶段,这个阶段最关键的点就是chunksInfoMap和addModuleToChunksInfoMap。
chunksInfoMap存储着代码分割信息,每一项都是一个缓存组,对应于最终要分割出哪些额外代码块,会不断迭代,最终将代码分割结果加入results中,而results最终会生成我们见到的打包文件。这些缓存组还附带一些额外信息,比如 cacheGroup,就是我们配置的 cacheGroup 代码分割规则,用于后续校验;再比如 sizes,记录了缓存组中模块的总体积,用于之后判断是否符合我们配置的 minSize 条件。addModuleToChunksInfoMap这个方法就是向chunksInfoMap中添加新的代码分割信息(选中的chunk集合),在方法中会通过key去更新缓存组或者添加新的缓存组。
模块分组阶段
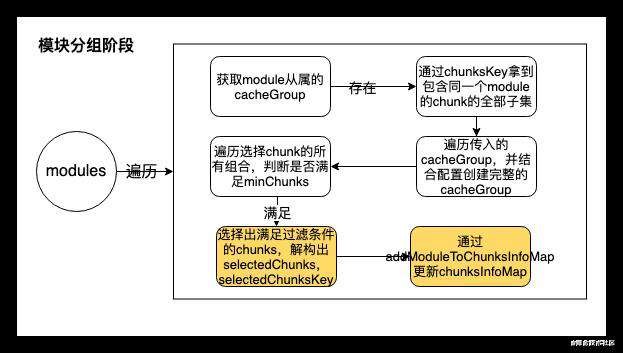
准备工作做好之后,开始核心的分组优化工作,遍历所有的models,将符合条件的module 通过 addModuleToChunksInfoMap 方法存到 chunksInfoMap 中。该代码在SplitChunksPlugin.js的565-670行:
// Walk through all modules
// 遍历所有modules
for (const module of compilation.modules) {
// Get cache group
// 通过getCacheGroups得到module从属的cacheGroup,一个module可能符合多个cacheGroup的条件
let cacheGroups = this.options.getCacheGroups(module);
if (!Array.isArray(cacheGroups) || cacheGroups.length === 0) {
continue;
}
// Prepare some values
// 包含同一个module的chunk会对应唯一的key值,通过前期准备阶段的各种方法,获取唯一的key,通过chunksKey拿到 包含同一个module的chunk的全部子集,并存入combinationsCache做缓存
const chunksKey = getKey(module.chunksIterable);
let combs = combinationsCache.get(chunksKey);
if (combs === undefined) {
combs = getCombinations(chunksKey);
combinationsCache.set(chunksKey, combs);
}
let cacheGroupIndex = 0;
for (const cacheGroupSource of cacheGroups) {
// 遍历将的cacheGroup配置都取出来,如果值不存在,则会从splitChunks全局配置继承
const minSize =
cacheGroupSource.minSize !== undefined
? cacheGroupSource.minSize
: cacheGroupSource.enforce
? 0
: this.options.minSize;
const enforceSizeThreshold =
cacheGroupSource.enforceSizeThreshold !== undefined
? cacheGroupSource.enforceSizeThreshold
: cacheGroupSource.enforce
? 0
: this.options.enforceSizeThreshold;
// 按照配置创建cacheGroup
const cacheGroup = {
key: cacheGroupSource.key,
priority: cacheGroupSource.priority || 0,
chunksFilter:
cacheGroupSource.chunksFilter || this.options.chunksFilter,
minSize,
minSizeForMaxSize:
cacheGroupSource.minSize !== undefined
? cacheGroupSource.minSize
: this.options.minSize,
enforceSizeThreshold,
maxSize:
cacheGroupSource.maxSize !== undefined
? cacheGroupSource.maxSize
: cacheGroupSource.enforce
? 0
: this.options.maxSize,
minChunks:
cacheGroupSource.minChunks !== undefined
? cacheGroupSource.minChunks
: cacheGroupSource.enforce
? 1
: this.options.minChunks,
maxAsyncRequests:
cacheGroupSource.maxAsyncRequests !== undefined
? cacheGroupSource.maxAsyncRequests
: cacheGroupSource.enforce
? Infinity
: this.options.maxAsyncRequests,
maxInitialRequests:
cacheGroupSource.maxInitialRequests !== undefined
? cacheGroupSource.maxInitialRequests
: cacheGroupSource.enforce
? Infinity
: this.options.maxInitialRequests,
getName:
cacheGroupSource.getName !== undefined
? cacheGroupSource.getName
: this.options.getName,
filename:
cacheGroupSource.filename !== undefined
? cacheGroupSource.filename
: this.options.filename,
automaticNameDelimiter:
cacheGroupSource.automaticNameDelimiter !== undefined
? cacheGroupSource.automaticNameDelimiter
: this.options.automaticNameDelimiter,
reuseExistingChunk: cacheGroupSource.reuseExistingChunk,
_validateSize: minSize > 0,
_conditionalEnforce: enforceSizeThreshold > 0
};
// For all combination of chunk selection
// 遍历选择chunk的所有组合
for (const chunkCombination of combs) {
// Break if minimum number of chunks is not reached
// 首先判断是否满足minChunks,如果不满足,就直接跳过,不建立这个缓存组,也就不会分割相应代码
if (chunkCombination.size < cacheGroup.minChunks) continue;
// Select chunks by configuration
// 利用准备阶段的方法,从chunk集合中,选择出满足过滤条件的chunks,并解构为selectedChunks,selectedChunksKey
const {
chunks: selectedChunks,
key: selectedChunksKey
} = getSelectedChunks(
chunkCombination,
cacheGroup.chunksFilter
);
// 利用准备阶段的addModuleToChunksInfoMap方法,将上一步产生的符合条件的selectedChunks、selectedChunksKey,结合modules、chunks、cacheGroupIndex和cacheGroup信息存到chunksInfoMap中,cacheGroupIndex每次都会+1
addModuleToChunksInfoMap(
cacheGroup,
cacheGroupIndex,
selectedChunks,
selectedChunksKey,
module
);
}
cacheGroupIndex++;
}
}
chunksFilter是chunks属性的过滤,即判断chunk是满足all、async还是initial。因此在分组阶段,除了将 cacheGroup 的配置全部取出,还检查配置中的 minChunks 和 chunks 规则,满足条件的分组才会被创建出来。其他各种需要校验的配置会在下一个阶段做处理。
依次检查阶段
在上一个阶段,我们将模块按照按照一定条件分组,并存入了chunksInfoMap中。本阶段就是优化的最后一步,判断chunksInfoMap的每一个缓存组是不是符合用户的cacheGroup配置,不满足就剔除。还是流程图出发:
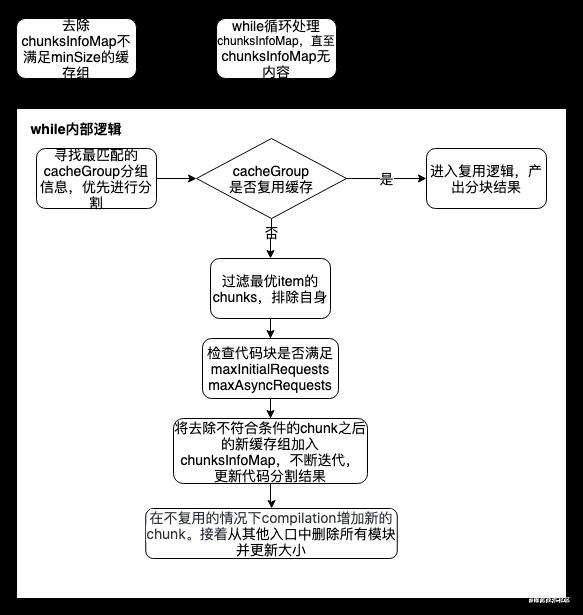
// Filter items were size < minSize
// 第一步,去除chunksInfoMap不满足minSize的缓存组(chunsInfoItem)
for (const pair of chunksInfoMap) {
const info = pair[1];
if (
info.cacheGroup._validateSize &&
info.size < info.cacheGroup.minSize
) {
chunksInfoMap.delete(pair[0]);
}
}
const maxSizeQueueMap = new Map();
// 第二步,while 循环,直到chunksInfoMap的缓存组全部分配好
while (chunksInfoMap.size > 0) {
// Find best matching entry
// 寻找最匹配的cacheGroup分组信息,优先进行分割,优先产生打包结果
let bestEntryKey;
let bestEntry;
for (const pair of chunksInfoMap) {
const key = pair[0];
const info = pair[1];
if (bestEntry === undefined) {
bestEntry = info;
bestEntryKey = key;
} else if (compareEntries(bestEntry, info) < 0) {
// 比较那个cacheGroup更需要有限分割
bestEntry = info;
bestEntryKey = key;
}
}
const item = bestEntry;
chunksInfoMap.delete(bestEntryKey);
let chunkName = item.name;
// Variable for the new chunk (lazy created)
// 由缓存组生成的新chunk
/** @type {Chunk} */
let newChunk;
// When no chunk name, check if we can reuse a chunk instead of creating a new one
let isReused = false;
// 从这里开始真正的分割代码
// 如果没有设定name,则寻找是否能复用已有的chunk
if (item.cacheGroup.reuseExistingChunk) {
outer: for (const chunk of item.chunks) {
if (chunk.getNumberOfModules() !== item.modules.size) continue;
if (chunk.hasEntryModule()) continue;
for (const module of item.modules) {
// 结束最外层for循环
if (!chunk.containsModule(module)) continue outer;
}
if (!newChunk || !newChunk.name) {
newChunk = chunk;
} else if (
chunk.name &&
chunk.name.length < newChunk.name.length
) {
newChunk = chunk;
} else if (
chunk.name &&
chunk.name.length === newChunk.name.length &&
chunk.name < newChunk.name
) {
newChunk = chunk;
}
chunkName = undefined;
isReused = true;
}
}
// 过滤chunks,过滤chunk自身
const selectedChunks = Array.from(item.chunks).filter(chunk => {
return (
(!chunkName || chunk.name !== chunkName) && chunk !== newChunk
);
});
// 获取enforced
const enforced =
item.cacheGroup._conditionalEnforce &&
item.size >= item.cacheGroup.enforceSizeThreshold;
// selectedChunks长度为0直接跳过
if (selectedChunks.length === 0) continue;
// chunks 去重
const usedChunks = new Set(selectedChunks);
// Check if maxRequests condition can be fulfilled
// 检测缓存组中的代码块是否满足maxInitialRequests和maxAsyncRequests条件,如果它们都是无穷大,就跳过检测
if (
!enforced &&
(Number.isFinite(item.cacheGroup.maxInitialRequests) ||
Number.isFinite(item.cacheGroup.maxAsyncRequests))
) {
for (const chunk of usedChunks) {
// 如果chunk是初始代码块,只需判断maxInitialRequests条件是否满足;
// 如果chunk不是初始代码块,只需判断maxAsyncRequests条件是否满足;
// 如果chunk可以作为初始代码块,就取两者最小值;不过目前这个分支条件是走不到的,因为目前版本代码块只有初始(作为入口)或者非初始(懒加载)
const maxRequests = chunk.isOnlyInitial()
? item.cacheGroup.maxInitialRequests
: chunk.canBeInitial()
? Math.min(
item.cacheGroup.maxInitialRequests,
item.cacheGroup.maxAsyncRequests
)
: item.cacheGroup.maxAsyncRequests;
// 如果不满足最大请求数的条件,则从validChunks中去除
if (
isFinite(maxRequests) &&
getRequests(chunk) >= maxRequests
) {
usedChunks.delete(chunk);
}
}
}
outer: for (const chunk of usedChunks) {
for (const module of item.modules) {
//结束外层for循环
if (chunk.containsModule(module)) continue outer;
}
// 包含item.modules中任意module的chunk要剔除
usedChunks.delete(chunk);
}
// Were some (invalid) chunks removed from usedChunks?
// => readd all modules to the queue, as things could have been changed
// 将去除不符合条件的chunk之后的新缓存组加入chunksInfoMap,不断迭代,更新代码分割结果
if (usedChunks.size < selectedChunks.length) {
// 剩余chunk大于minChunks,则加入chunksInfoMap,迭代分割
if (usedChunks.size >= item.cacheGroup.minChunks) {
const chunksArr = Array.from(usedChunks);
for (const module of item.modules) {
addModuleToChunksInfoMap(
item.cacheGroup,
item.cacheGroupIndex,
chunksArr,
getKey(usedChunks),
module
);
}
}
continue;
}
// Create the new chunk if not reusing one
// 如果不重用一个,则compilation创建新的块
if (!isReused) {
newChunk = compilation.addChunk(chunkName);
}
// Walk through all chunks
for (const chunk of usedChunks) {
// Add graph connections for splitted chunk
// 创建了新代码块还不够,还需要建立chunk和chunkGroup之间的关系
chunk.split(newChunk);
}
// Add a note to the chunk
// 提供输出信息:根据是否复用输出不同信息
newChunk.chunkReason = isReused
? "reused as split chunk"
: "split chunk";
// 提供输出信息便于我们debug
if (item.cacheGroup.key) {
newChunk.chunkReason += ` (cache group: ${item.cacheGroup.key})`;
}
if (chunkName) {
console.log(chunkName)
newChunk.chunkReason += ` (name: ${chunkName})`;
// If the chosen name is already an entry point we remove the entry point 如果所选名称已经是入口点,我们将删除该入口点
const entrypoint = compilation.entrypoints.get(chunkName);
if (entrypoint) {
compilation.entrypoints.delete(chunkName);
entrypoint.remove();
newChunk.entryModule = undefined;
}
}
if (item.cacheGroup.filename) {
if (!newChunk.isOnlyInitial()) {
throw new Error(
"SplitChunksPlugin: You are trying to set a filename for a chunk which is (also) loaded on demand. " +
"The runtime can only handle loading of chunks which match the chunkFilename schema. " +
"Using a custom filename would fail at runtime. " +
`(cache group: ${item.cacheGroup.key})`
);
}
newChunk.filenameTemplate = item.cacheGroup.filename;
}
if (!isReused) {
// Add all modules to the new chunk 将所有的modules添加到新chunk
for (const module of item.modules) {
if (typeof module.chunkCondition === "function") {
// 这个版本永远是true
if (!module.chunkCondition(newChunk)) continue;
}
// Add module to new chunk
// 建立module和新chunk的关系 关键代码,通过这里变更chunk图
GraphHelpers.connectChunkAndModule(newChunk, module);
// Remove module from used chunks 从使用的chunk移除module
for (const chunk of usedChunks) {
chunk.removeModule(module);
module.rewriteChunkInReasons(chunk, [newChunk]);
}
}
} else {
// Remove all modules from used chunks
// 如果是复用的,则从usedChunks中删除所有的module
for (const module of item.modules) {
for (const chunk of usedChunks) {
chunk.removeModule(module);
module.rewriteChunkInReasons(chunk, [newChunk]);
}
}
}
if (item.cacheGroup.maxSize > 0) {
// 如果cacheGroup.maxSize > 0,则更新maxSizeQueueMap,更新newChunk的minSize,maxSize等
const oldMaxSizeSettings = maxSizeQueueMap.get(newChunk);
maxSizeQueueMap.set(newChunk, {
minSize: Math.max(
oldMaxSizeSettings ? oldMaxSizeSettings.minSize : 0,
item.cacheGroup.minSizeForMaxSize
),
maxSize: Math.min(
oldMaxSizeSettings ? oldMaxSizeSettings.maxSize : Infinity,
item.cacheGroup.maxSize
),
automaticNameDelimiter: item.cacheGroup.automaticNameDelimiter,
keys: oldMaxSizeSettings
? oldMaxSizeSettings.keys.concat(item.cacheGroup.key)
: [item.cacheGroup.key]
});
}
// remove all modules from other entries and update size
// 从其他入口中删除所有模块并更新大小
for (const [key, info] of chunksInfoMap) {
if (isOverlap(info.chunks, usedChunks)) {
// 判断info的chunk是有有在usedChunks中
// update modules and total size
// may remove it from the map when < minSize
//
const oldSize = info.modules.size;
for (const module of item.modules) {
// 将info.modules中的item.modules的module都删除
info.modules.delete(module);
}
if (info.modules.size !== oldSize) {
if (info.modules.size === 0) {
chunksInfoMap.delete(key);
continue;
}
info.size = getModulesSize(info.modules);
if (
info.cacheGroup._validateSize &&
info.size < info.cacheGroup.minSize
) {
chunksInfoMap.delete(key);
}
if (info.modules.size === 0) {
chunksInfoMap.delete(key);
}
}
}
}
}
compareEntries、isOverlap代码
const compareEntries = (a, b) => {
// 1. by priority 通过cacheGroup的priority比较
const diffPriority = a.cacheGroup.priority - b.cacheGroup.priority;
if (diffPriority) return diffPriority;
// 2. by number of chunks,比较两个cacheGroyp的chunks的大小
const diffCount = a.chunks.size - b.chunks.size;
if (diffCount) return diffCount;
// 3. by size reduction 比较两个cacheGroyp的大小
const aSizeReduce = a.size * (a.chunks.size - 1);
const bSizeReduce = b.size * (b.chunks.size - 1);
const diffSizeReduce = aSizeReduce - bSizeReduce;
if (diffSizeReduce) return diffSizeReduce;
// 4. by cache group index 比较cacheGroupIndex
const indexDiff = b.cacheGroupIndex - a.cacheGroupIndex;
if (indexDiff) return indexDiff;
// 5. by number of modules (to be able to compare by identifier) 比较cacheGroup的modules数量
const modulesA = a.modules;
const modulesB = b.modules;
const diff = modulesA.size - modulesB.size;
if (diff) return diff;
// 6. by module identifiers比较modules的identifiers
modulesA.sort();
modulesB.sort();
const aI = modulesA[Symbol.iterator]();
const bI = modulesB[Symbol.iterator]();
// eslint-disable-next-line no-constant-condition
while (true) {
const aItem = aI.next();
const bItem = bI.next();
if (aItem.done) return 0;
const aModuleIdentifier = aItem.value.identifier();
const bModuleIdentifier = bItem.value.identifier();
if (aModuleIdentifier > bModuleIdentifier) return -1;
if (aModuleIdentifier < bModuleIdentifier) return 1;
}
};
const isOverlap = (a, b) => {
for (const item of a) {
if (b.has(item)) return true;
}
return false;
};
经过本阶段的筛选,chunksInfoMap 中符合配置规则的缓存组会被全部打包成新代码块,完成代码分割的工作。
总结
以上就是SplitChunksPlugin的整个工作流程,从优化前准备到模块分组,最终依次检查,输出最终打包文件。不管是哪一个步骤都有着关键的作用。SplitChunksPlugin的源码我们不能修改,但是cacheGroups是交给我们配置的,合适cacheGroups配置,就能产出合适的chunksInfoMap,从而输出合适的分包结果。
分析源码的过程,可以看到整个过程并没有复杂的算法逻辑,而是合理的安排每一个步骤,在合适的时间做合适的事情,最终将一个庞大的项目分割成能够预测的结果。我们自己在开发过程中也应该学习这样的思想,不要过度设计,而是把复杂的设计简单化。当然简化流程的代价可能就是复杂的数据结构,这两者如何抉择还是因项目而异了。
常见问题FAQ
- 免费下载或者VIP会员专享资源能否直接商用?
- 本站所有资源版权均属于原作者所有,这里所提供资源均只能用于参考学习用,请勿直接商用。若由于商用引起版权纠纷,一切责任均由使用者承担。更多说明请参考 VIP介绍。
- 提示下载完但解压或打开不了?
- 找不到素材资源介绍文章里的示例图片?
- 模板不会安装或需要功能定制以及二次开发?





发表评论
还没有评论,快来抢沙发吧!