相信大家都学习过webpack的用法,但是它的原理是怎样的呢?面试官问到webpack打包原理的时候,该如何回答呢?我这里借鉴了Dell老师的教程,简单的写一个打包工具,带大家深入了解一下webpack打包原理,废话不多说,直接开始:
---------分---------割---------线---------
第一部分:入口文件分析
首先在根目录下创建一个src文件夹,用来保存要打包的文件,在src文件里创建word.js、message.js、index.js三个文件
// word.js
export const word = 'hello';
// message.js
import { word } from './word';
const message = `say ${word}`;
export default message;
// index.js
import message from './message';
console.log(message);
上面已经创建好了要打包的文件,然后再创建一个bundler.js文件,用来实现打包功能,目录结构如下:
首先打包的第一步,就是对入口模块进行分析,所以我们先创建一个函数,命名为moduleAnalyser,这里我们的入口文件就是index.js,所以函数要接收一个入口文件作为参数,我们就把index.js传进去
const moduleAnalyser = fileName => {
// 在这里分析代码
};
moduleAnalyser('./src/index.js');
第一步相信大家都能理解,我们继续分析:要想分析这个文件里的内容,首先我们要拿到它的内容,所以这里就需要引入node里的核心模块fs,然后使用readFileSync方法获取到文件内容,然后打印出内容:
const fs = require('fs');
const moduleAnalyser = fileName => {
const content = fs.readFileSync(fileName, 'utf8');
console.log(content);
};
moduleAnalyser('./src/index.js');
然后再控制台中运行bundler,我们可以看到,输出的结果就是index文件中的内容:

好了,第一步拿到入口文件内容已经成功了,第二步,我们要拿到模块的依赖,在index.js这个模块中,依赖文件是message.js,所以我们要把message.js从代码中提取出来,如何提取呢?这里我们需要借助到babel的一个工具,安装@babel/parser,然后引入,这个工具会为我们提供一个parse()方法,接收两个参数,第一个参数是要分析的代码,第二个参数是配置项,因为我们的代码用到了ES Module的语法,所以第二个参数要进行相关配置,然后我们打印出结果进行查看:
const fs = require('fs');
const paser = require('@babel/parser');
const moduleAnalyser = fileName => {
const content = fs.readFileSync(fileName, 'utf8');
console.log(paser.parse(content, { sourceType: "module" }));
};
moduleAnalyser('./src/index.js');
然后在控制台里执行这段代码,可以看到输出了很长的一个对象:
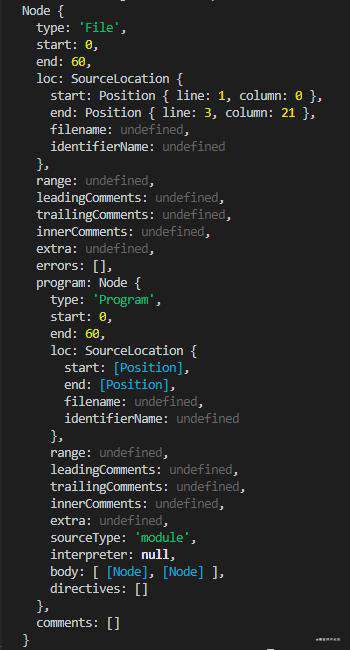
没错!这个对象就是我们平时常说的AST抽象语法树!
在AST对象中,有一个program字段,在program中,有一个body字段,是我们需要用到的,我们打印一下body,同时再稍微优化一下我们的代码:
const fs = require('fs');
const paser = require('@babel/parser');
const moduleAnalyser = fileName => {
const content = fs.readFileSync(fileName, 'utf8');
const ast = paser.parse(content, { sourceType: "module" });
console.log(ast.program.body);
};
moduleAnalyser('./src/index.js');
然后再次执行,查看结果:
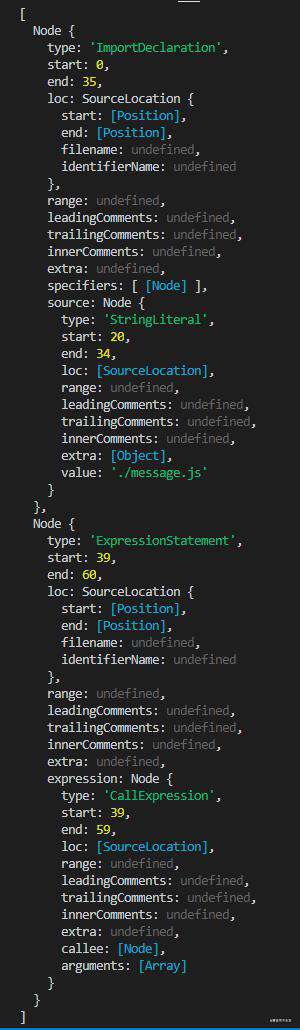
这次控制台又打印出了两个东西,这是program里的内容所对应的节点,第一个节点告诉我们,“这是一个引入”,正好对应我们index文件中的 import message from './message'这行代码,确实是一个引入;第二个节点告诉我们,“这是一个表达式”,正好对应我们index文件中的console.log(message)这行代码,确实是一个表达式
所以我们用babel的parse方法,可以帮助我们分析出AST抽象语法树,通过AST又可以拿到声明的语句,声明的语句里放置了入口文件里对应的依赖关系,所以我们利用抽象语法树,把我们的js代码转换成了js对象
那么我们现在要做的事情是,拿到代码里面所有的依赖的对应关系,具体做法就是遍历body对象,但是这里,不需要手写遍历,babel又为我们提供了一个方法,可以快速找到import的节点,安装@babel/traverse,然后引入(引入的时候注意后面要加.default),然后使用traverse方法进行遍历,这个方法接收两个参数,第一个参数是AST抽象语法树,第二个参数是配置项
const fs = require('fs');
const paser = require('@babel/parser');
const traverse = require('@babel/traverse').default;
const moduleAnalyser = fileName => {
const content = fs.readFileSync(fileName, 'utf8');
const ast = paser.parse(content, { sourceType: "module" });
traverse(ast, {
ImportDeclaration({ node }) {
console.log(node);
}
});
};
moduleAnalyser('./src/index.js');
然后在控制台中执行代码,可以看到输出了一个新的对象,也就是我们遍历之后的结果:
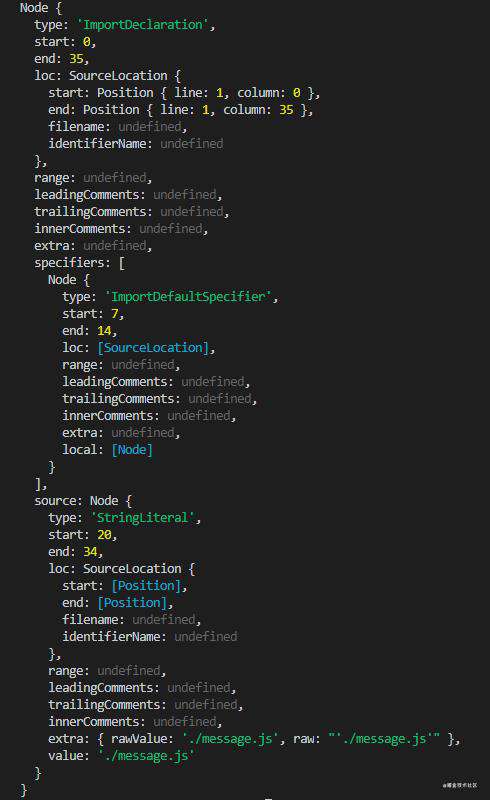
这时候可以再次对代码进行优化:声明一个空数据,每次在遍历的时候,每次遇到一个依赖,我们就把依赖放进数组里保存起来,需要注意的是,我们不用把整个依赖信息都保存起来,可以看到,对象里有个source字段,这个字段里有个value字段,value的值是依赖的文件名,我们只需要保存value就好了,最后再打印一下我们的依赖数组(需要注意的是,这里有一个小坑:path.join()方法在Mac系统中输出的结果和在Windows系统中是不一样的,在Mac中输出"/",在Windows中输出"\\",所以我们这里需要用到正则进行处理一下):
const fs = require('fs');
const path = require('path');
const paser = require('@babel/parser');
const traverse = require('@babel/traverse').default;
const moduleAnalyser = fileName => {
const content = fs.readFileSync(fileName, 'utf8');
const ast = paser.parse(content, { sourceType: "module" });
const dependencies = [];
traverse(ast, {
ImportDeclaration({ node }) {
const dirname = path.dirname(fileName);
const newFile = './' + path.join(dirname, node.source.value);
dependencies.push(newFile.replace(/\\/g, '/'));
}
});
console.log(dependencies);
};
moduleAnalyser('./src/index.js');
然后在控制台执行代码,查看输出结果:

从输出结果中可以看到,我们已经成功的分析出了入口文件中的依赖文件!
但是!我们可以看到,这里的打印出来的依赖路径是一个相对路径,是相对src文件的,然而我们在真正做代码打包的时候,这些依赖文件不能是相对路径,必须是绝对路径(即便是相对路径,也必须要相对根路径才可以,这样打包才不会有问题),那么这个问题该如何解决呢?这里可以引入node中的另外一个模块path,然后用path.dirname()获取到入口文件的相对路径,然后用path.join()把两个路径拼接起来,就能得到绝对路径了,这个路径才是我们打包时需要用到的,当然,当代码写到后面的时候,大家会发现,如果dependencies里保存的不是相对路径的话,在后面打包的时候还是比较麻烦的,最好的办法是,既存一个相对路径,又存一个绝对路径,那我们就可以这样写:把dependencies变成对象,相对路径作为key,绝对路径作为value来保存,那么这时候,上面的代码又可以改写为:
const fs = require('fs');
const path = require('path');
const paser = require('@babel/parser');
const traverse = require('@babel/traverse').default;
const moduleAnalyser = fileName => {
const content = fs.readFileSync(fileName, 'utf8');
const ast = paser.parse(content, { sourceType: "module" });
const dependencies = {};
traverse(ast, {
ImportDeclaration({ node }) {
const dirname = path.dirname(fileName);
const newFile = './' + path.join(dirname, node.source.value);
dependencies[node.source.value] = newFile.replace(/\\/g, '/');
}
});
console.log(dependencies);
};
moduleAnalyser('./src/index.js');
在控制台执行代码,查看输出结果:
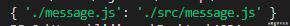
可以看到,结果从上面的数组变成了一个对象,是没有任何问题的
接下来要做的事情,就是用babel对代码进行转换、编译,把代码转换成浏览器可以认识的es5,安装@babel/core,并且引入,这个工具提供给我们一个transformFromAst()方法进行转换,方法接收三个参数,第一个参数是ast,第二个参数可以填null,第三个参数是配置项(注意配置项里的"@babel/preset-env"也需要手动安装),这个方法会把ast抽象语法树转换成一个对象并且返回,对象里包含一个code,这个code就是编译生成的,可以在浏览器上直接运行的当前模块的代码,这里可以打印一下code:
const fs = require('fs');
const path = require('path');
const paser = require('@babel/parser');
const traverse = require('@babel/traverse').default;
const babel = require('@babel/core');
const moduleAnalyser = fileName => {
const content = fs.readFileSync(fileName, 'utf8');
const ast = paser.parse(content, { sourceType: "module" });
const dependencies = {};
traverse(ast, {
ImportDeclaration({ node }) {
const dirname = path.dirname(fileName);
const newFile = './' + path.join(dirname, node.source.value);
dependencies[node.source.value] = newFile.replace(/\\/g, '/');
}
});
const { code } = babel.transformFromAst(ast, null, {
presets: ["@babel/preset-env"]
});
console.log(code);
};
moduleAnalyser('./src/index.js');
在控制台执行代码,查看输出结果:

可以看到,打印出的代码已经不是我们之前在src目录下的代码了,而且经过翻译的代码,然后把上面的入口文件、依赖文件、还有代码三个字段返回,那么写到这里,恭喜你,我们对入口文件代码的分析就大功告成了!
然后,我们可以打印出最终的结果,稍微优化一下代码:
const fs = require('fs');
const path = require('path');
const paser = require('@babel/parser');
const traverse = require('@babel/traverse').default;
const babel = require('@babel/core');
const moduleAnalyser = fileName => {
const content = fs.readFileSync(fileName, 'utf8');
const ast = paser.parse(content, { sourceType: "module" });
const dependencies = {};
traverse(ast, {
ImportDeclaration({ node }) {
const dirname = path.dirname(fileName);
const newFile = './' + path.join(dirname, node.source.value);
dependencies[node.source.value] = newFile.replace(/\\/g, '/');
}
});
const { code } = babel.transformFromAst(ast, null, {
presets: ["@babel/preset-env"]
});
return { fileName, dependencies, code };
};
const moduleInfo = moduleAnalyser('./src/index.js');
console.log(moduleInfo);
在控制台执行代码,查看输出结果:
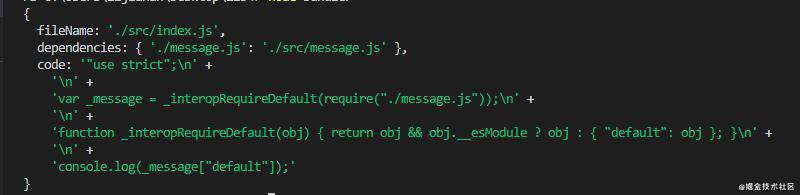
好了,没有问题!
截止这里,我们已经对入口文件的代码做了完整的分析,分析的结果也获取到了,讲到这里,我们的进度已经完成了三分之一,是不是很有趣呢?
好了,第一部分如果全部看懂,我们开始进行第二部分,如果没看懂,建议再看一遍
---------分---------割---------线---------
第二部分:生成依赖图谱
先复习一下,我们在第一部分中,完成了一个moduleAnalyser函数,这个函数的作用是:当我们把一个文件传进去的时候,这个函数会帮我们分析出这个文件的依赖以及源代码,并且返回分析出的结果
上面我们只是对一个模块进行了分析,在这部分,我们的任务是要对整个工程里的所有模块进行分析,所以下一步,我们又要分析其它文件对应的模块信息,一层一层分析,最终把所有模块的信息分析出来,要想实现这个效果,我们要再去写一个函数,这里可以定义一个新的函数,和上面的moduleAnalyser一样,需要接收一个入口文件:
const makeDependenciesGraph = entry => {
const entryModule = moduleAnalyser(entry);
console.log(entryModule);
};
makeDependenciesGraph('./src/index.js');
这时候打印出的结果和之前还是没有任何区别的
很显然,这是不够的,因为在这部分,我们不仅要对入口文件做分析,还要对依赖的文件做分析,这里,我们可以用递归来实现:
- 先创建新数组graphArray,然后把上面分析出的entryModule保存到数组里
- 然后对数组graphArray进行遍历,再从遍历的每一项中拿出依赖信息dependencies
- 然后判断依赖信息dependencies是否存在,如果存在的话,说明这个文件中有依赖,然后再对依赖信息进行遍历,这里需要注意的是,依赖信息dependencies是一个对象,而不是数组,所以要用for...in进行遍历,而不能用for循环
- 遍历之后,这里再次调用moduleAnalyser方法,对依赖信息里的每一项进行分析
- 分析出结果之后,再把结果push进graphArray里,这里就实现了递归的效果
这样一来,第一次循环结束的时候,这个graphArray里面不仅有了入口文件,还会多出依赖信息对应的模块,也被分析完成了,这个时候,graphArray的数组长度发生了变化,又会继续进行遍历,接着又会分析下一个依赖信息……反复循环,最后我们就把入口文件、以及依赖文件、以及依赖文件的依赖……一层一层全部推进graphArray里面,代码如下:
const makeDependenciesGraph = entry => {
const entryModule = moduleAnalyser(entry);
const graphArray = [entryModule];
for (let i = 0; i < graphArray.length; i++) {
const item = graphArray[i];
const { dependencies } = item;
if (dependencies) {
for (let j in dependencies) {
const resule = moduleAnalyser(dependencies[j]);
graphArray.push(resule);
}
}
}
console.log(graphArray);
};
makeDependenciesGraph('./src/index.js');
在控制台执行代码,打印出graphArray数组,查看打印结果:
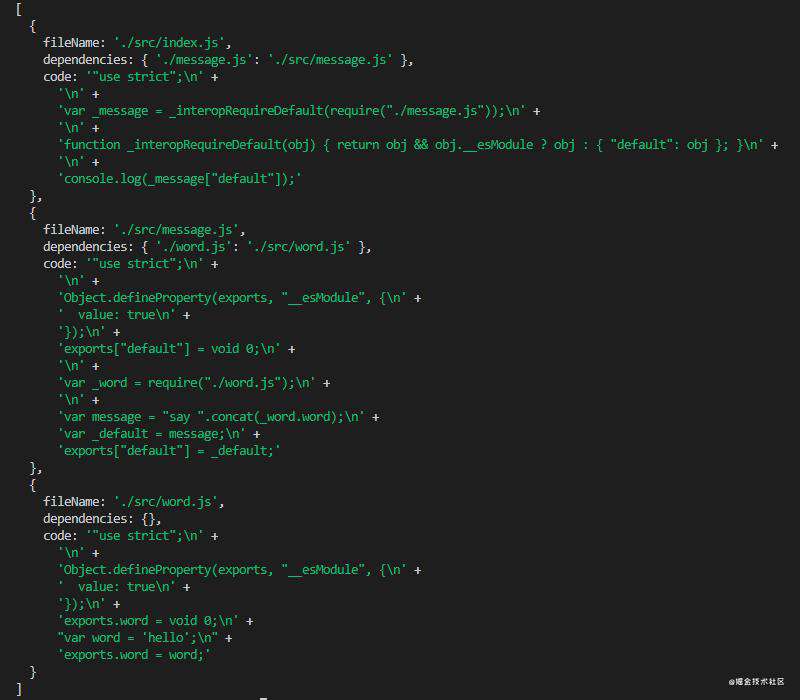
可以看到,每一个文件的信息都被完美的分析出来!
这里的数组graphArray,就可以当做一个依赖图谱,它可以准确的反映出我们项目的依赖信息!
接下来,我们要对数组做一个格式的转换,把数组转换成对象,然后返回出去,以方便打包代码:
const makeDependenciesGraph = entry => {
const entryModule = moduleAnalyser(entry);
const graphArray = [entryModule];
for (let i = 0; i < graphArray.length; i++) {
const item = graphArray[i];
const { dependencies } = item;
if (dependencies) {
for (let j in dependencies) {
const resule = moduleAnalyser(dependencies[j]);
graphArray.push(resule);
}
}
}
const graph = {};
graphArray.forEach(item => {
const { fileName, dependencies, code } = item;
graph[fileName] = { dependencies, code };
});
return graph;
};
const graphInfo = makeDependenciesGraph('./src/index.js');
console.log(graphInfo);
在控制台执行代码,打印出graphInfo,查看打印结果:
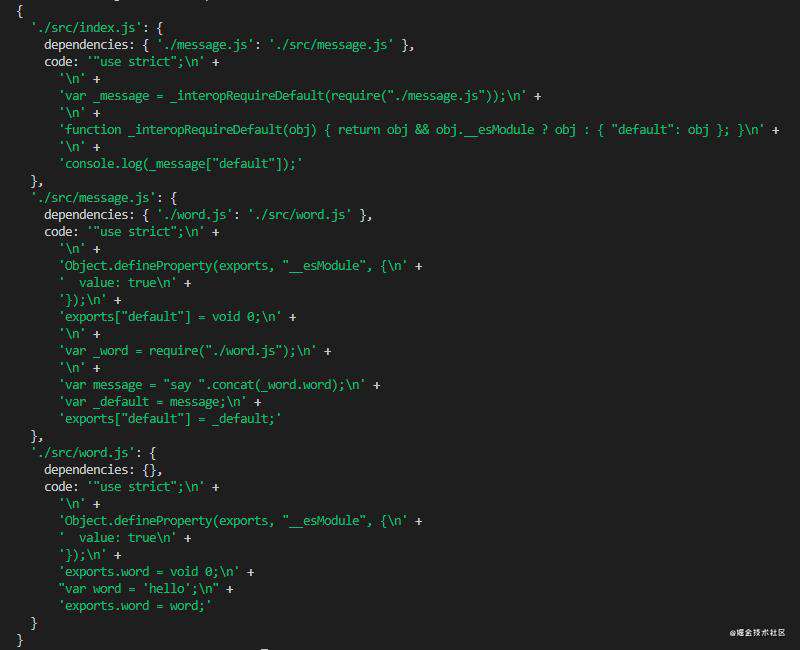
OK,这样结构就非常清晰了!
截止目前,我们已经生成了整个项目的依赖图谱,讲到这里,我们的进度已经完成了三分之二,胜利就在眼前!
好了,第二部分如果全部看懂,我们开始进行第三部分,如果没看懂,建议再看一遍
---------分---------割---------线---------
第三部分:生成最终代码
在前面两部分,我们完成了对一个模块的代码分析、以及对所有模块的代码分析、以及项目的依赖图谱,这部分,我们要借助依赖图谱生成可以真正在浏览器上运行的代码
这里我们可以创建一个新的函数generateCode,同样接收一个入口文件作为参数,当然,函数最终要生成代码,所以return的结果应该是字符串,所以这里返回字符串:
const generateCode = entry => {
const graph = makeDependenciesGraph(entry);
return `
// 生成的代码
`;
};
const code = generateCode('./src/index.js');
console.log(code);
首先我们知道,网页中的所有代码都应该放在一个大的闭包里面,避免勿扰全局环境,所以第一步,我们要写个闭包:
const generateCode = entry => {
const graph = makeDependenciesGraph(entry);
return `
(function(graph){
function require(module) {
function localRequire(relativePath) {
return require(graph[module].dependencies[relativePath]);
};
var exports = {};
(function(require, exports, code) {
eval(code);
})(localRequire, exports, graph[module].code);
return exports;
};
require('${entry}');
})(${JSON.stringify(graph)});
`;
};
const code = generateCode('./src/index.js');
console.log(code);
常见问题FAQ
- 免费下载或者VIP会员专享资源能否直接商用?
- 本站所有资源版权均属于原作者所有,这里所提供资源均只能用于参考学习用,请勿直接商用。若由于商用引起版权纠纷,一切责任均由使用者承担。更多说明请参考 VIP介绍。
- 提示下载完但解压或打开不了?
- 找不到素材资源介绍文章里的示例图片?
- 模板不会安装或需要功能定制以及二次开发?





发表评论
还没有评论,快来抢沙发吧!