前文我们介绍了打包器的基本情况,今天对于webpack进行详细的介绍。
分为以下几个部分
- 概念
- 基本使用
- 源码debug
- 实现一个简单的打包器
- 进阶用法
- 二次开发
1 概念
在介绍webpack之前我们先了解相关的概念
- entry 指定入口文件,打包时从该文件开始递归解析依赖,生成依赖图(dependency graph),后者用于表示模块之间的依赖关系
- output 指定打包后的文件输出目录
- loaders webpack本身只能处理js和json,如果要处理其他文件需要先使用对应loader将其转化为有效模块然后才能加到依赖图
- plugin 插件用于loader以外的工作处理
- mode 设定当前打包的模式,会自动注入环境变量,并自动启用相关优化
- target webpack可以打包node端和web端的文件,设置target可以根据特定环境使用相关api
- asset 是各种类型文件的通用叫法,用于在html文件中引入,比如css、images等
- bundle 打包后的最终文件
- bundle splitting/code splitting 将一个应用最终生成的bundle分为多个,可有效利用缓存和按需加载
- chunk 是bundle生成的中间形式,表示模块之间的依赖关系,分为两种
- initial 表示入口文件指定的依赖,用filename指定name
- non-initial 当动态加载或者使用SplitChunksPlugin拆分出去的bundle,用于懒加载,用chunkFilename指定name
- manifest 当bundle在浏览器中运行时,runtime会使用其解析和加载各个打包好的模块
- tree shaking 打包时移除不需要的代码
- config 用于指定webpack工作的配置文件
2 基本使用
作为一个打包器,我们介绍一下最基本用法,
- 准备一个空文件夹,执行
npm init -y初始化package.json,下载我们所需要的包,我们这里使用yarn,包管理器相关参考这里- webpack webpack核心文件
- webpack-cli 使用命令行调用webpack api的工具
yarn add webpack webpack-cli --dev - 创建src文件夹,创建一个index.js文件
import { log } from "./print";
log(3);
再在当前文件夹创建一个依赖的文件print.js
export const log = (v) => {
console.log(v);
};
- 执行webpack打包我们第一个文件,如果没有配置文件默认entry是
src/index,输出的bundle文件是dist/main.js,具体为在命令行调用npx webpack或者在package.json文件中配置script,后者具体用法参考task-runner相关文章。
此时我们在dist文件夹得到了一个打包后的文件main.js,如果创建一个html文件使用script引入便可以直接使用。
(()=>{"use strict";console.log(3)})();
这就是打包器最简单的使用方式,其中src中两个文件是模块,main.js是bundle。
3 源码debug
想要知道实现原理当然要看源码,走起
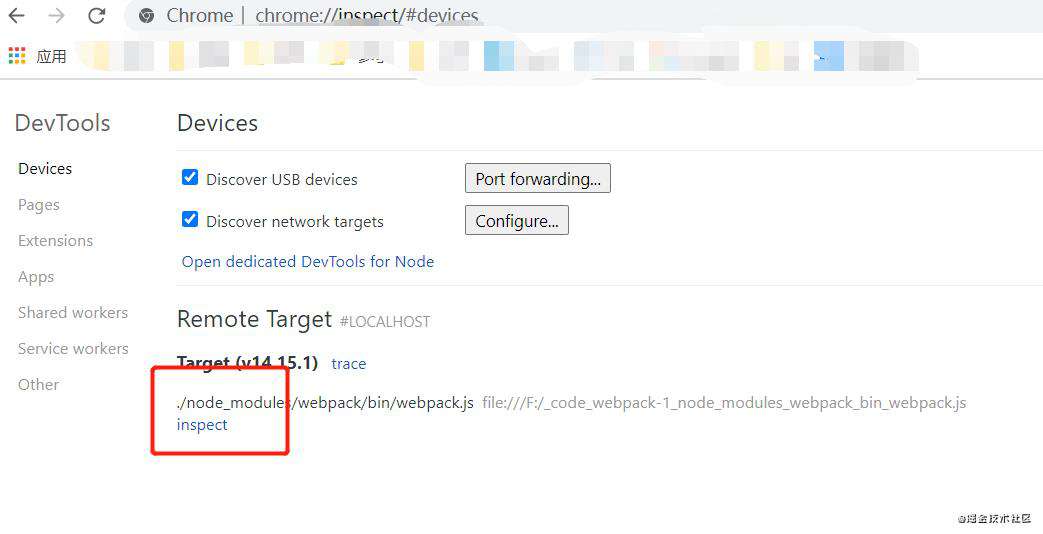
debug一个node.js项目,node.js官方给出了很多方法,详见这里,我们选用chrome调试,调试webpack版本为5.21.2,即
- 在chrome打开chrome://inspect
- 在项目根目录执行
node --inspect-brk ./node_modules/webpack/bin/webpack.js,点击下图红框中的链接即可进入调试模式
具体实现细节自己一步步调试,这里大体介绍一下运行情况。
当我们在命令行执行一个包自带的命令时,如果是直接执行,比如执行webpack,则会在全局安装的目录中去找对应包下的package.json的"bin"字段,执行对应的文件,如果想要执行当前项目中的包命令,需要使用完整目录或者使用npx作为辅助。因此我们在执行前述debug命令时其实执行的是node_modules/webpack/bin/webpack.js 中的内容,这也是我们debug的入口文件。
- 执行启动文件
开始执行时,检查webpack-cli有没有安装,没有的话安装,否则执行webpack-cli中的bin文件,即node_modules/webpack-cli/bin/cli.js
- 合成配置
正式打包之前要先读取相关配置文件,包括但不限于webpack.config.json,读取命令启动时的参数,并添加其他默认参数,组成最后的参数
- 调用webpack api
这一步是webpack的核心,调用webpack()方法创建实例化Compiler,一个compiler表示一次webpack的启动,主要负责编译前的准备工作和编译后的文件输出,最重要的是会实例化一个compilation对象进行实际的编译,当使用watch模式启动时,每次文件修改compiler对象都会实例化新的compilation对象,执行一次新的编译。
webpack使用tapable在编译的各个阶段挂载了很多hook,在各个不同阶段我们可以通过插件来访问compiler,乃至进一步访问compilation等对象,来执行我们想进行的操作。
整个编译过程大致可分为以下步骤
- 调用
createCompiler()实例化compiler,并挂载配置文件中的插件 - 执行compiler的run方法,实例化NormalModuleFactory和ContextModuleFactory对象,获取实例化compilation的参数,比如解析loaders配置
- 调用
createCompilation()实例化compilation对象执行编译- 从入口文件开始使用loader对文件进行转换
- 将处理后的代码解析为ast,做进一步处理,比如将源码中的require转变为__webpack_require__
- 重新生成源码,并生成依赖关系图
- compiler执行
emitAssets()将编译后的代码输出
4 实现一个简单的打包器
假定你现在已经将源码debug过了,现在为了更好的理解相关原理,我们要将打包器的基本功能实现一遍。思路如下
- 抄一个配置文件作为我们新打包器的配置文件
- 打包器的启动文件为一个js文件,实例化我们打包器中的compiler,并调用run方法启动
- 实现一个compiler类,初始化各种hook,注册插件,初始化compilation对象,输出文件。
- 实现一个compilation类,从入口文件开始递归遍历,使用loader处理文件后再编译成ast进一步处理,然后
具体实现细节
- 开始编译时,先递归遍历各依赖项,为了防止重复遍历需要设置一个moduleMap,用于存放遍历过的文件
- 对于loader我们会使用babel将源码处理,并将其他模块语法,比如import转化为require,方便后续处理,对于babel作为编译器的使用细节,参考这里
- 对于插件,我们会在相关hook中打印个日志
- 对于编译成ast以及进一步处理,我们仍然使用babel
- 对于bundle文件的输出,我们会用模板引擎cjs,将解析后的代码插入到模板中,其中模板中含有__webpack_require__的实现
具体实现源码在这里。
5 进阶使用
本部分会对webpack的相关配置、具体使用和原理做详细介绍
6 二次开发
这部分包括利用webpack打包应用以外的开发,包括
- library
- loader
- plugin
最后两章待补充。
常见问题FAQ
- 免费下载或者VIP会员专享资源能否直接商用?
- 本站所有资源版权均属于原作者所有,这里所提供资源均只能用于参考学习用,请勿直接商用。若由于商用引起版权纠纷,一切责任均由使用者承担。更多说明请参考 VIP介绍。
- 提示下载完但解压或打开不了?
- 找不到素材资源介绍文章里的示例图片?
- 模板不会安装或需要功能定制以及二次开发?





发表评论
还没有评论,快来抢沙发吧!