前言
玩了一段时间GraphQL后突然想起来很有必要看一下DataLoader源码, 正好以此作为重新开始更新文章的契机. 我已经攒了一堆想写的文章idea了... 但是人懒真的是没办法的事, 而且最近确实在忙着学很多新东西hhh.
实际上DataLoader本身的实现没有多么复杂, 优秀以及强大的是它的思想, 每个前端工程师都或多或少了解过事件循环的相关概念, 可是能够真正使用事件循环的机制, 来解决GraphQL API最为人诟病的缺点之一: N+1问题, 却并不容易.
这篇文章会包含较多干货, 如:
- 在GraphQL Resolver中应用DataLoader带来的变化
- DataLoader源码解析(Batch部分)
- 迷你实现的DataLoader
- Prisma2中的DataLoader
- 集成DataLoader到ORM层与框架层
这篇文章能帮助你梳理导致GraphQL N+1的问题根源, 再到入手解决它, 稍微复习事件循环机制相关的知识, 以及如何与ORM/框架集成DataLoader, 这也是我对GraphQL的正式第一篇文章.
GraphQL N+1 问题
假设现在有这么一个场景, 我们要拿到所有用户的所有宠物信息, 如果用RESTFul API的话, 要先拿到所有用户的ID, 再去宠物的接口拿到所有宠物的信息:
GET /users
[
{
"id": 1,
"name": "aaa",
"petsId": [1, 2]
},
{
"id": 2,
"name": "bbb",
"petsId": [2, 3, 4]
}
]
GET /pet/:id
[
{
"id": 1,
"kind": "Cat"
},
{
"id": 2,
"kind": "Dog"
}
// ...
]
查询次数 N+1 次, 数据库I/O N+1 次
而对于GraphQL来说, 查询语句通常是这样的:
query {
fetchAllUsers {
id
name
pets {
id
kind
age
isMale
}
}
}
查询次数只有1次对吧? 但数据库I/O次数呢?
看起来好像也只有一次? 因为数据是一起查回来的? 实际上这里的数据库I/O次数达到了N+1次. 具体的demo我们会在下面讲解, 先来简单介绍下上面的GraphQL语句基本含义:
query意味着本次查询是只读不写的, 这是GraphQL中的操作类型概念, 其他的操作类型还有mutation与subscription, 分别代表着读写操作(可以想象为RESTFul中的POST/PUT/Delete等带方法)与订阅操作(可以理解为WebSocket, 实际上订阅操作也必须通过WebSocket承接)fetchAllUsers是一个对象类型, 它的内部包含了idname这些基础属性, 以及pets这一对象属性, 再进入到pets中, 它拥有的都是基础属性. 在一个大型GraphQL API中, 对象属性的嵌套可能会达到数十层甚至更多(这是GraphQL的特色之一, 但往往也可能带来严重的性能问题, 所以通常会限制嵌套的深度, 抛弃掉超出一定深度的请求).- REST API中我们通常有
Controller的概念, 来针对路由级别做出响应. 对应的, GraphQL中也有Resolver的概念, 但是它针对的则是对象类型(ObjectType). 也就是说, 每一个对象类型都会有自己的解析器, 比如上面的fetchAllUsers和pets. 你可以理解为Resolver就是针对对象类型的函数.
现在假设我们有一百个用户, 调用fetchAllUsers的解析器会返回这一百个用户的数组, 接着用户对象内还存在着对象属性pets, 那么我们还需要调用pets对应的解析器次数是? 理想情况当然是1次, 因为我们可以在第一次查询中拿到所有用户的信息, 那么只要用所有的宠物ID再查一次得到所有的宠物信息不就行了吗?
但实际情况中, GraphQL会首先执行用户1的pets解析器, 得到用户1的宠物信息, 然后执行用户2, ..., 一共100次, 加上查询所有用户的那1次, 这就是GraphQL的N+1问题.
实际问题
我们来看实际的demo:
这里我用Apollo-Server写了一个简单的GraphQL服务器, 并且为了减少环境配置成本直接用Promise模拟了数据返回的延迟. 如果你想建立一个完善的GraphQL服务, 推荐使用TypeGraphQL以及Apollo-GraphQL的其他开源项目, 也可参考我写的这个大demo: GraphQL-Explorer-Server
我们的GraphQL Schema定义是这样的:
const typeDefs = gql`
type Query {
fetchAllUsers: [User]
fetchUserByName(name: String!): User
}
type User {
id: Int!
name: String!
partner: User
pets: [Pet]
}
type Pet {
id: Int!
kind: String!
age: Int!
isMale: Boolean!
}
`;
然后我们写一个简单的mock数据:
const promiseWrapper = <T>(value: T, indicator: string): Promise<T> =>
new Promise((resolve) => {
setTimeout(() => {
console.log(chalk.cyanBright(indicator));
return resolve(value);
}, 200);
});
const mockService = (() => {
const users: IUser[] = [];
const pets: IPet[] = [];
return {
getUserById: (id: number) =>
promiseWrapper(
users.find((user) => user.id === id),
`getUserById: ${id}`
),
getUserByName: (name: string) =>
promiseWrapper(
users.find((user) => user.name === name),
`getUserByName: ${name}`
),
getUsersByIds: (ids: number[]) =>
promiseWrapper(
users.filter((user) => ids.includes(user.id)),
`getUsersByIds: ${ids}`
),
getAllUsers: () => promiseWrapper(users, "getAllUsers"),
getPetById: (id: number) =>
promiseWrapper(
pets.find((pet) => pet.id === id),
`getPetById: ${id}`
),
getPetsByIds: (ids: number[]) =>
promiseWrapper(
pets.filter((pet) => ids.includes(pet.id)),
`getPetsByIds: ${ids}`
),
getAllPets: () => promiseWrapper(pets, "getAllPtes"),
};
})();
这里模拟了通常会在Controller/Resolver中调用的Service层, promiseWrapper的第二个参数是为了帮助定位当前被调用的方法.
然后我们就需要定义Resolvers了, 前面我们讲过每个对象类型都需要自己的Resolver, 精确一点的说, 是每个在根查询对象Query中被使用(不包括嵌套)的对象类型都需要. 比如这里Query.fetchAllUsers返回[User], 所以需要专门的User Resolver, 而User.pets返回[Pet], 我们却并不需要定义专门的Pet Resolver, 而是直接定义User.pets解析器即可, 举例来说:
const resolvers = {
Query: {
fetchUserByName(root, { name }: { name: string }, { service }: IContext) {
return service.getUserByName(name);
},
fetchAllUsers(root, args, { service }: IContext) {
return service.getAllUsers();
},
},
};
现在Query能正常解析了, 但是fetchAllUsers返回的User类型中的partner和pets没有对应的解析器, 势必会报错, 因此需要补上, 完整的如resolver应该看起来像这样:
const resolvers = {
Query: {
fetchUserByName(root, { name }: { name: string }, { service }: IContext) {
return service.getUserByName(name);
},
fetchAllUsers(root, args, { service }: IContext) {
return service.getAllUsers();
},
},
User: {
async partner(user: IUser, args, { service }: IContext) {
return service.getUserById(user.partnerId);
},
async pets(user: IUser, args, { service }: IContext) {
return service.getPetsByIds(user.petsId);
},
},
};
现在我们编写了好了类型定义与对应的解析器, 就可以基于Apollo-Server启动一个GraphQL 服务了:
const server = new ApolloServer({
typeDefs,
resolvers,
tracing: true,
context: async () => {
return {
service: mockService,
},
};
},
playground: {
settings: {
"editor.fontSize": 16,
"editor.fontFamily": "Fira Code",
},
},
});
server.listen(4545).then(({ url }) => {
console.log(chalk.greenBright(`Apollo GraphQL Server ready at ${url}`));
});
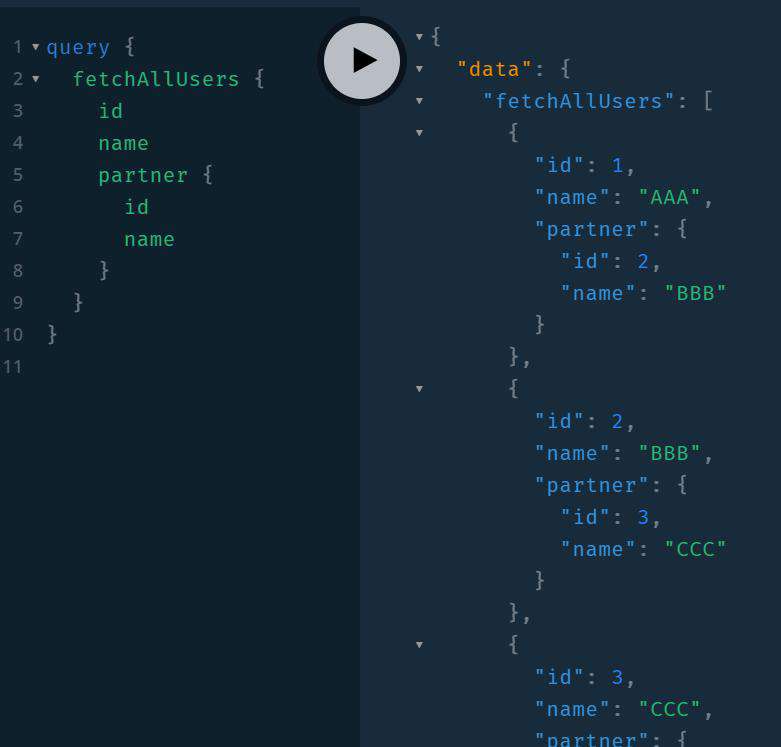
然后访问http://localhost:4545/graphql, 使用如下的查询语句:
query {
fetchAllUsers {
id
name
partner {
id
name
}
}
}
结果应当如图所示:
终端的打印结果:
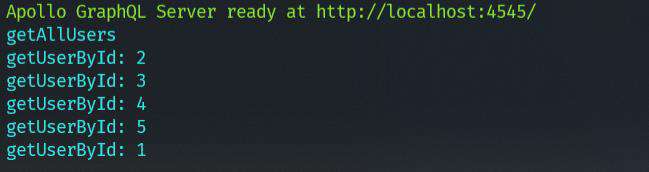
可以看到, 现在调用了1次getAllUsers, 与5次getUserById, 也就是说, 此时N+1问题是存在的. 如何解决? 那就要请出DataLoader了.
DataLoader 的仓库README讲述了它的来源与历史, 不夸张的说, 除了练手项目以及性能未出现不足的小规模项目以外, 只要是正式使用的GraphQL服务几乎都有DataLoader的身影, 但也有例外, 比如使用了Hasura PostGraphile 这一类直接接管数据库的方案.
DataLoader的构造函数签名是这样的:
constructor(batchLoadFn: DataLoader.BatchLoadFn<K, V>, options?: DataLoader.Options<K, V, C>);
我们主要关注batchLoadFn, 这是我们传入的批处理函数. 简单地说, 就是一个能根据一组ID拿到一组对应数据的函数, 就像TypeORM的repository.findByIds()方法.
看到这里你可能已经明白DataLoader思路了, 或者在最开始我们讲到造成GraphQL N+1问题的根源你可能就明白了, 只要收集一批需要查询的数据ID, 在最后一起解析不就行了吗. DataLoader也就是这么做的, 所以我们才需要在实例化时传入一个批查询函数.
由于DataLoader本身还具有缓存功能, 并且每一个实例都会占据一块内存空间, 所以在存在多个对象类型时, 最好的方法是为每一个对象类型构造一个新的实例, 就像这里:
context: async () => {
return {
service: mockService,
dataloaders: {
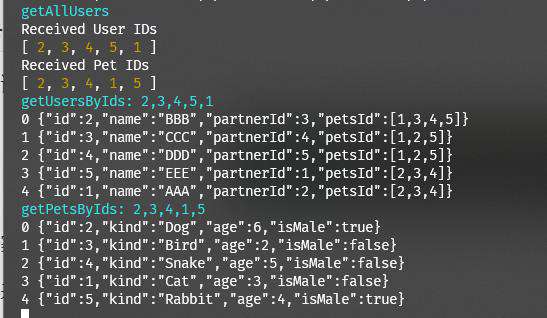
users: new DataLoader(async (userIds: Readonly<number[]>) => {
console.log("Received User IDs");
console.log(userIds);
const users = await mockService.getUsersByIds(userIds as number[]);
return users.sort(
(prev, curr) => userIds.indexOf(prev.id) - userIds.indexOf(curr.id)
);
}),
pets: new DataLoader(
async (petIds: Readonly<number[]>) => {
console.log("Received Pet IDs");
console.log(petIds);
const pets = await mockService.getPetsByIds(petIds as number[]);
return pets.sort(
(prev, curr) => petIds.indexOf(prev.id) - petIds.indexOf(curr.id)
);
}
),
},
};
},
需要注意的地方:
- 在完成实例化后, DataLoader实例上主要有load和loadMany这两个方法, 对于这里的User.partner(一对一关系), 应当使用load方法, 对于User.pets(一对多), 应当使用loadMany方法
- 为了使用DataLoader的缓存能力, 这里我们应当确保入参(userIds)和返回值(users)的顺序是一一对应的, 或者你也可以自定义缓存的映射关系, 这里不做展开.
修改resolver, 改为使用dataloader获取数据:
const resolvers = {
// ...
User: {
async partner(user: IUser, args, { service, dataloaders }: IContext) {
// return service.getUserById(user.partnerId);
return dataloaders.users.load(user.partnerId);
},
async pets(user: IUser, args, { service, dataloaders }: IContext) {
// return service.getPetsByIds(user.petsId);
return dataloaders.pets.loadMany(user.petsId);
},
},
};
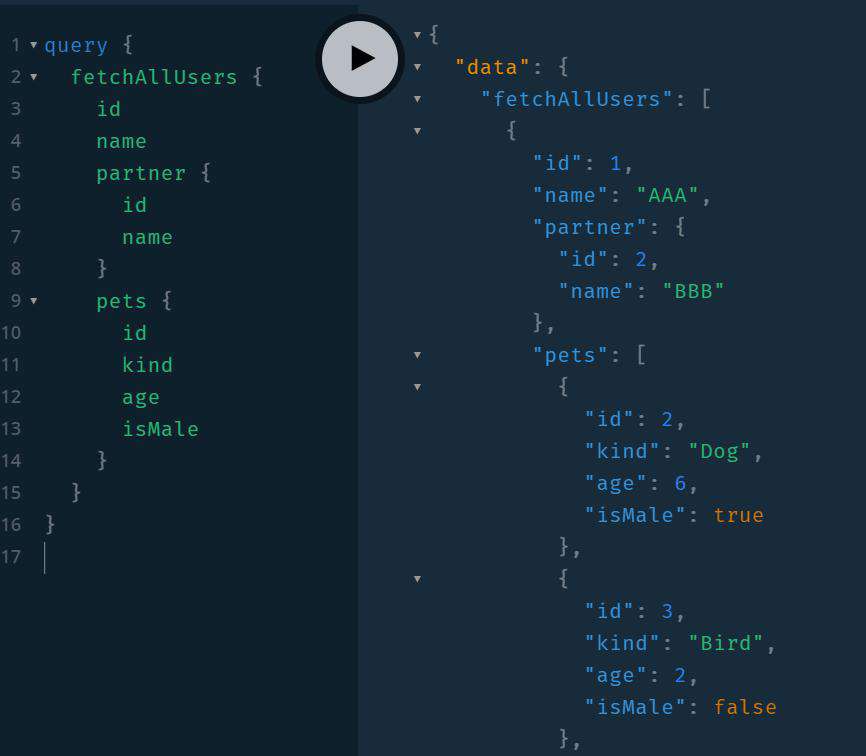
查询语句不变来看看结果:

好家伙, 现在只会调用一次getUsersByIds方法即可取回所有的数据, 你可真是个小天才.
再来试试pets字段:
import DataLoader from "./dataloader";
DataLoader源码
接下来我们可以看DataLoader源码了, 在开始前不妨想想如果让你来实现, 你会用什么方式?
DataLoader的核心功能主要有Batch和Cache, 这里我们只讲解Batch部分, 因为Cache功能的实现没有特别玄学的地方, 很容易看懂. 对于TypeScript代码来说, 最好的阅读方式就是先瞅瞅它的类型声明:
// class内部
constructor(batchLoadFn: BatchLoadFn<K, V>, options?: Options<K, V, C>) {
this._batchLoadFn = batchLoadFn;
this._batchScheduleFn = getValidBatchScheduleFn(options);
this._maxBatchSize = getValidMaxBatchSize(options);
this._batch = null;
}
使用batchLoadFn和options实例化DataLoader, 这里的类型重点是BatchLoadFn和Options:
export type BatchLoadFn<K, V> = (
keys: Readonly<Array<K>>
) => Promise<Readonly<Array<V | Error>>>;
export type Options<K, V, C = K> = {
batch?: boolean;
maxBatchSize?: number;
batchScheduleFn?: (callback: () => void) => void;
};
没啥需要讲的, 这里的batchScheduleFn是非常重要的一个函数, 字面意义上可以理解为调度函数,
this._batchScheduleFn = getValidBatchScheduleFn(options); 这里我们调用了一个getValidBatchScheduleFn, 并将其作为此实例的调度函数:
function getValidBatchScheduleFn(
options?: Options<any, any, any>
): (fn: () => void) => void {
let batchScheduleFn = options && options.batchScheduleFn;
if (batchScheduleFn === undefined) {
return enqueuePostPromiseJob;
}
if (typeof batchScheduleFn !== "function") {
throw new TypeError(
`batchScheduleFn must be a function: ${batchScheduleFn}`
);
}
return batchScheduleFn;
}
这个函数做的事情也很简单, 如果你在实例化时传入了调度函数, 那就用传入的, 否则就用**enqueuePostPromiseJob**, 这东西是啥我们后面再讲, 变量名来看, 就是入队一个Promise后的任务.
然后来看我们前面使用的load方法:
type Batch<K, V> = {
hasDispatched: boolean;
keys: Array<K>;
callbacks: Array<{
resolve: (value: V) => void;
reject: (error: Error) => void;
}>;
};
load(key: K): Promise<V> {
let batch = getCurrentBatch(this);
batch.keys.push(key);
const promise: Promise<V> = new Promise((resolve, reject) => {
batch.callbacks.push({ resolve, reject });
});
return promise;
}
load方法的实现意料之外的简单, 这也是我初读时的感叹.
调用getCurrentBatch方法获取到batch, 并将入参key添加到keys数组中, 然后生成一个promise, 将这个promise的resolve reject方法添加到callbacks数组中.
看到这里你可能还是一头雾水, 问题不大, 再看两个函数你就豁然开朗了!
function getCurrentBatch<K, V>(loader: DataLoader<K, V, any>): Batch<K, V> {
let existingBatch = loader._batch;
if (
existingBatch !== null &&
!existingBatch.hasDispatched &&
existingBatch.keys.length < loader._maxBatchSize
) {
return existingBatch;
}
let newBatch = { hasDispatched: false, keys: [], callbacks: [] };
loader._batch = newBatch;
loader._batchScheduleFn(() => {
dispatchBatch(loader, newBatch);
});
return newBatch;
}
由这个函数名我们知道它的作用是返回当前的batch, 在其内部逻辑中首先判断是否已经当前实例是否已经处于一个batch(或者说拥有?), 如果有, 则返回已存在的batch. 如果没有, 就生成一个新的, 并将其标记为未派发的(hasDispatched: false), 并且将一个调用dispatchBatch的函数添加到调度函数中.
解析:
- 第一次调用load方法会创建一个新的batch并挂载到实例上, 同一个batch内的后续调用会返回这个batch. 在获得这个batch的饮用后, 将调用load时的key添加到batch.keys中
- 只有第一次调用load方法时, 会将
dispatchBatch(loader, newBatch)添加到调度函数中, 从函数名意义理解, 也就是开始执行当前batch内的"任务".
现在我们可以来看看前面说的enqueuePostPromiseJob了, 实际上这是整个DataLoader Batch功能实现的核心:
let enqueuePostPromiseJob =
typeof process === "object" && typeof process.nextTick === "function"
? function (fn) {
if (!resolvedPromise) {
resolvedPromise = Promise.resolve();
}
resolvedPromise.then(() => {
process.nextTick(fn);
});
}
: setImmediate || setTimeout;
很好理解, 如果当前是在NodeJS环境下, 就使用
Promise.resolve().then(()=>{
process.nextTick(fn)
})
在浏览器环境下, 如果支持则使用setImmediate, 否则使用setTimeout
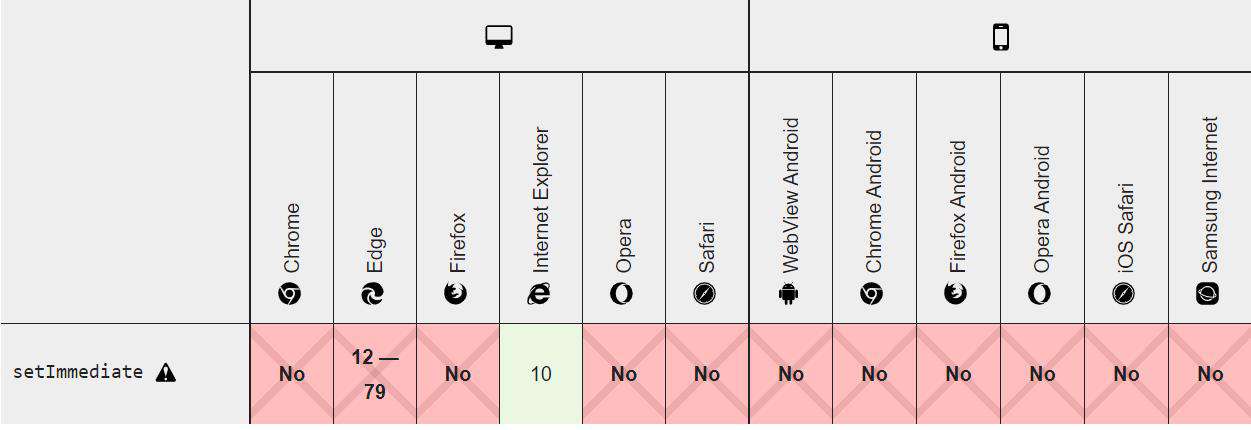
知道了这些, 我们先继续看后面的逻辑, 会有专门的一节讲解这些API在NodeJS事件循环中的优先级.
function dispatchBatch<K, V>(
loader: DataLoader<K, V, any>,
batch: Batch<K, V>
) {
batch.hasDispatched = true;
if (batch.keys.length === 0) {
return;
}
let batchPromise = loader._batchLoadFn(batch.keys);
batchPromise
.then((values) => {
for (let i = 0; i < batch.callbacks.length; i++) {
let value = values[i];
if (value instanceof Error) {
batch.callbacks[i].reject(value);
} else {
console.log(`${i} ${JSON.stringify(value)}`);
batch.callbacks[i].resolve(value);
}
}
})
.catch((error) => {
failedDispatch(loader, batch, error);
});
}
在dispatchBatch中:
- 标记当前batch为已派发
- 使用batch.keys作为参数调用实例化时传入的批查询函数(即需要进行批处理的数据)
- 遍历批查询函数返回的值(Promise内), 依次调用
batch.callbacks(或者reject)中的resolve, 也就是将load返回的promise resolve掉. 这里可以看到key和callbacks都是遵从添加顺序的.
我们从头理一遍逻辑:
- 调用load方法, 首先调用
getCurrentBatch获取到当前batch getCurrentBatch中, 返回已存在的batch或者新建一个batch, 对于新创建的batch, 调用_batchScheduleFn, 将dispatchBatch(loader, newBatch)添加到批处理函数中_batchScheduleFn方法, 如果选项中没有传入, 就会使用enqueuePostPromiseJob, 这个变量实际上就是根据环境来选择使用的调度函数, 通常在NodeJs下会使用process.nextTick()(还会包裹在一个立刻resolve的promise的then方法中), 在浏览器中使用setTimeout来作为调度函数. 你也可以显式的指定(通过实例化时的options.batchScheduleFn)- 在load方法中获取到batch后, 会将当前的入参key添加到batch.keys中, 生成一个promise, 将其resolve reject分别添加到
batch.callbacks中, 并返回这个promise - 在
dispatchBatch执行时, load方法已经被调用多次, 所有本次batch内需要的key都被添加到batch.keys内, 所以在此方法内可以直接使用实例化时传入的batchLoadFn传入keys来获取所有需要的结果, 而后遍历结果, resolve/reject掉每一个(load返回的)promise. - 在所有load方法的promise都已经resolve/reject后, 本次batch结束
NodeJS中的事件循环
在这里我们只讲解NodeJS中的事件循环, 因为enqueuePostPromiseJob的作用是相同的, 都是确保 dispatchBatch在所有Promise任务后执行 .
NodeJS中的事件循环由Libuv实现, 每一轮循环分为这么几个阶段:
- 初始化, 执行
process.nextTick与microTasks - 正式的Event Loop:
- timers, 执行到期的
setTimeout与setInterval, 检查并完成所有的process.nextTick, 检查并完成所有的microtask - I/O 回调, 执行已完成的I/O操作的回调函数, 检查并完成所有的process.nextTick, 检查并完成所有的microtask
- idle与prepare阶段, 可忽略
- poll:
- 检查是否有可用回调(定时器 I/O), 并执行, 检查并完成所有的process.nextTick, 检查并完成所有的microtask
- 没有回调时, 检查
setImmediate回调, 如果均没有, 阻塞在此阶段等待新的事件通知. 如果有, 才进入下一阶段check. - 不存在尚未完成的回调, 进入下一阶段check
- check: 执行
setImmediate回调, 检查并完成所有的process.nextTick, 检查并完成所有的microtask - close callbacks
- timers, 执行到期的
dispatchBatch实际上是这样被执行的(NodeJS环境下):
promise.then(() => {
process.nextTick(dispatchBatch(loader, newBatch))
})
因此, 很容易理解使用这种方式添加的dispatchBatch会在下次事件循环的开始执行, 而所有promise此时已经执行完毕, 也就意味着load方法已经将所有key都添加到batch.keys中, 此时执行batchLoadFn, 就能确保已经收集完毕批查询所需的key.
在浏览器中, 由于可以简单的分为微任务和宏任务, 因此使用setTimeout来确保dispatchBatch在所有promise任务后执行是更容易理解的.
Mini版本DataLoader
如果要实现一个简单的, 仅需要支持Batch功能的DataLoader就要简单得多.
Mini版本的DataLoader主要有这些不同:
- 直接使用
process.nextTick作为enqueuePostPromiseJob - 使用数组而不是一个对象来表示batch, 在这里我们定义为任务队列, batch处理中需要使用
hasDispatched来标识状态, 这里我们直接用任务队列的长度来标识: 首次调用load, 任务队列为空, 将执行方法通过enqueuePostPromiseJob添加到JavaScript的任务队列
完整实现如下:
type BatchLoader<K, V> = (
keys: Readonly<Array<K>>
) => Promise<Readonly<Array<V | Error>>>;
type Task<K, V> = {
key: K;
resolve: (val: V) => void;
reject: (reason?: unknown) => void;
};
type Queue<K, V> = Array<Task<K, V>>;
export default class TinyDataLoader<K, V, C> {
readonly _batchLoader: BatchLoader<K, V>;
_taskQueue: Queue<K, V>;
constructor(batchLoader: BatchLoader<K, V>) {
this._batchLoader = batchLoader;
this._taskQueue = [];
}
load(key: K): Promise<V> {
const currentQueue = this._taskQueue;
const shouldDispatch = currentQueue.length === 0;
if (shouldDispatch) {
enqueuePostPromiseJob(() => {
executeTaskQueue(this);
});
}
const promise = new Promise<V>((resolve, reject) => {
currentQueue.push({ key, resolve, reject });
});
return promise;
}
loadMany(keys: Readonly<Array<K>>): Promise<Array<V | Error>> {
return Promise.all(keys.map((key) => this.load(key)));
}
}
let resolvedPromise: Promise<void>;
function enqueuePostPromiseJob(fn: () => void): void {
if (!resolvedPromise) {
resolvedPromise = Promise.resolve();
}
resolvedPromise.then(() => process.nextTick(fn));
}
function executeTaskQueue<K, V>(loader: TinyDataLoader<K, V, any>) {
// 保存后清空
const queue = loader._taskQueue;
loader._taskQueue = [];
// 这里已经拿到了所有key
const keys = queue.map(({ key }) => key);
const batchLoader = loader._batchLoader;
const batchPromise = batchLoader(keys);
batchPromise.then((values) => {
queue.forEach(({ resolve, reject }, index) => {
const value = values[index];
value instanceof Error ? reject(value) : resolve(value);
});
});
}
为了更好的理解, 可以将Task与Queue分别对标到原本版本实现的batch.callbacks与batch, 只不过这里的Queue实际上就是Task组成的数组, 每一个Task自身携带key resolve reject属性.
Prisma中的DataLoader
如果你此前没有使用过Prisma, 我这里简单的介绍一下, Prisma是**"下一代的ORM"**, 但又和你使用过的ORM完全不同, 比如定义实体, TypeORM与Sequelize在ts文件内通过JavaScript/TypeScript对象(类)的方式定义, 由ORM在运行时完成到表/列的定义的转换, 比如一个TypeORM的实体可能是这样的:
import {
Entity,
PrimaryGeneratedColumn,
Column,
PrimaryColumn,
Generated,
} from "typeorm";
@Entity()
export class User {
@PrimaryGeneratedColumn()
id!: number;
@Column()
firstName!: string;
@Column({ nullable: true })
lastName?: string;
@Column({ nullable: true })
age?: number;
}
而Prisma完全不同, 你需要通过.prisma文件定义数据库的结构, 然后运行prisma generate生成Prisma Client, 在文件中导入它, 然后就可以进行各种操作了.
一份Prisma Schema可以是这样:
// This is your Prisma schema file,
// learn more about it in the docs: https://pris.ly/d/prisma-schema
datasource db {
provider = "sqlite"
url = env("SINGLE_MODEL_DATABASE_URL")
}
generator client {
provider = "prisma-client-js"
output = "./client"
}
model Todo {
id Int @id @default(autoincrement())
title String
content String?
finished Boolean @default(false)
createdAt DateTime @default(now())
updatedAt DateTime @updatedAt
}
生成的client结构则是这样的:
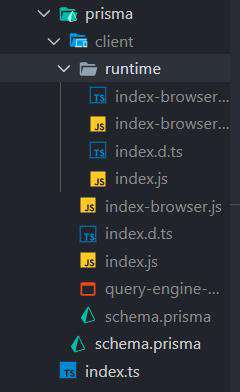
使用:
import { PrismaClient } from "./prisma/client";
const prisma = new PrismaClient();
async function createTodo(title: string, content?: string) {
const res = await prisma.todo.create({
data: {
title,
content,
},
});
return res;
}
前面我们说到GraphQL API要么使用dataloader, 要么使用Hasura/PostGraphile这种数据库层的方案, 来解决n+1问题, 其实使用Prisma作为ORM也能解决, 因为Prisma内置了DataLoader(应该是在Prisma 2才有了内置功能, 我没有在V1版本中看到).
这里的实现也相当精简, 只有百来行不到, 核心思路类似于原版的DataLoader, 也是使用process.nextTick来执行dispatchBatch, 见 源码
这里放一下加过注释的代码:
// 每一个任务包含这些属性 可以理解为前面迷你实现的Task
interface Job {
resolve: (data: any) => void;
reject: (data: any) => void;
request: any;
}
export type DataloaderOptions<T> = {
singleLoader: (request: T) => Promise<any>;
batchLoader: (request: T[]) => Promise<any[]>;
// 批处理的标识符 标识各个batch
batchBy: (request: T) => string | null;
};
export class Dataloader<T = any> {
batches: { [key: string]: Job[] };
private tickActive = false;
constructor(private options: DataloaderOptions<T>) {
this.batches = {};
}
get [Symbol.toStringTag]() {
return "Dataloader";
}
request(request: T): Promise<any> {
// 获得当前batch的标识符
const hash = this.options.batchBy(request);
if (!hash) {
// 如果不需要使用批处理, 直接使用singleLoader
return this.options.singleLoader(request);
}
// 如果是全新的batch, 声明一个新的命名空间(this.batchers[hash])存储需要批量执行的任务
if (!this.batches[hash]) {
this.batches[hash] = [];
// make sure, that we only tick once at a time
// 将新的batch对应的加入到未来执行(enqueuePostPromiseJob)
if (!this.tickActive) {
this.tickActive = true;
process.nextTick(() => {
this.dispatchBatches();
this.tickActive = false;
});
}
}
return new Promise((resolve, reject) => {
// 添加任务到对应batch的命名空间下
this.batches[hash].push({
request,
resolve,
reject,
});
});
}
private dispatchBatches() {
for (const key in this.batches) {
const batch = this.batches[key];
delete this.batches[key];
// only batch if necessary
// this might occur, if there's e.g. only 1 findUnique in the batch
// 当batch下仅存在一个任务时, 只使用singleLoader
if (batch.length === 1) {
this.options
.singleLoader(batch[0].request)
.then((result) => {
if (result instanceof Error) {
batch[0].reject(result);
} else {
batch[0].resolve(result);
}
})
.catch((e) => {
batch[0].reject(e);
});
} else {
// 使用batchLoader
this.options
.batchLoader(batch.map((j) => j.request))
.then((results) => {
if (results instanceof Error) {
for (let i = 0; i < batch.length; i++) {
batch[i].reject(results);
}
} else {
// 遍历resolve/reject
for (let i = 0; i < batch.length; i++) {
const value = results[i];
if (value instanceof Error) {
batch[i].reject(value);
} else {
batch[i].resolve(value);
}
}
}
})
.catch((e) => {
for (let i = 0; i < batch.length; i++) {
batch[i].reject(e);
}
});
}
}
}
}
DataLoader集成
TypeGraphQL-DataLoader
如果我们使用的是TypeGraphQL这种方式, 上面那种传入typeDefs和resolvers的方案就不能再使用了, 因为TypeGraphQL与Apollo-Server一同使用时, 传入的schema属性会屏蔽掉传入的typeDefs与resolvers. 并且, 使用TypeGraphQL的情况下Resolver也是完全不同的定义方式, 参考上面的GraphQL-Explorer-Server. 这种时候想要使用DataLoader, 就需要在ORM层操作了(如果你不使用ORM, 也可以像上面那样在context中为每个对象类型定义dataloader实例).
而社区已经有了提供这一能力的包: TypeGraphQL-DataLoader
它的使用方式也很简单, 就是在TypeORM的关系属性上定义@TypeormLoader装饰器, 并在ApolloServer中注入ORM获得连接的方法(如TypeORM的getConnection),根据传入的类型定义以及装饰的target class获得关系定义:
const relation = tgdContext
.typeormGetConnection()
.getMetadata(target.constructor)
.findRelationWithPropertyPath(propertyKey.toString());
然后根据关系类型与当前装饰的属性是否是关系的所有者调用对应的handle, 包括handleToOne handleToMany 等:
const handle =
relation.isManyToOne || relation.isOneToOneOwner ?
handleToOne :
relation.isOneToMany ?
option?.selfKey ?
handleOneToManyWithSelfKey :
handleToMany :
relation.isOneToOneNotOwner ?
option?.selfKey ?
handleOneToOneNotOwnerWithSelfKey :
handleToOne :
relation.isManyToMany ?
handleToMany :
() => next();
在不同的handle方法内部, 又调用了不同作用的DataLoader实例, 如
class ToOneDataloader<V> extends DataLoader<any, V> {
constructor(relation: RelationMetadata, connection: Connection) {
super(
directLoader(
relation,
connection,
relation.inverseEntityMetadata.primaryColumns[0].propertyName
)
);
}
}
整体起作用则是通过TypeGraphQL的useMiddleware来拦截Resolver执行.
NestJS-DataLoader
这一集成方式又和上面的大不相同, 更像我们一开始的使用方式: 为每个对象类型实例化一个新的DataLoader实例:
// 创建
@Injectable()
export class AccountLoader implements NestDataLoader<string, Account> {
constructor(private readonly accountService: AccountService) { }
generateDataLoader(): DataLoader<string, Account> {
return new DataLoader<string, Account>(keys => this.accountService.findByIds(keys));
}
}
// 省略注册为provider过程
// 使用
@Resolver(Account)
export class AccountResolver {
@Query(() => [Account])
public getAccounts(
@Args({ name: 'ids', type: () => [String] }) ids: string[],
@Loader(AccountLoader.name) accountLoader: DataLoader<Account['id'], Account>): Promise<Account[]> {
return accountLoader.loadMany(ids);
}
}
是不是和一开始使用的差不多? 考虑到@Query(@Resolver和@Query都来自于@nestjs/graphql, 但实际作用和TypeGraphQL的一样)实际上就是定义resolver的方式, 可以说使用方式基本是一样的.
实际上, TypeGraphQL-DataLoader也提供了这种方式来为每个对象类型(或者说实体)提供一个DataLoader实例的方式, 这也是灵活度最高, 优化最好的一种方式.
源码就简单得多了, 直接参考注释版 nestjs-dataloader
总结
DataLoader相关的知识就分享到这里, 回顾一下, 实际上最核心的思路还是enqueuePostPromiseJob, 通过这种方式巧妙地将 一批单次的数据查询(GetSingleUserById) 转化为 一次批量的数据查询(GetBatchUsersByIds), 大大减少了数据库I/O的次数, 使得你的GraphQL API性能一下有了明显提升.
在最后我想有必要补充一点, DataLoader并不一定能提升你的GraphQL API响应速度, 你可以通过ApolloServer的tracing选项来开启请求链路耗时追踪:
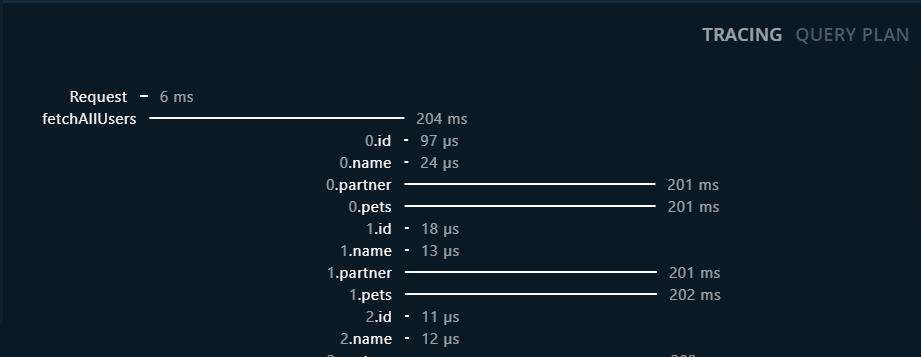
在不使用DataLoader时, 假设执行N次GetSingleUserById, 那么I/O会是这样的:
----->
----->
------>
---->
相当于是多个耗时较小的I/O并行执行.
而执行1次GetBatchUsersByIds, I/O可能会是这样的:
--------------->
相当于单个耗时较大的I/O执行.
所以, 使用DataLoader并不一定能提升你的接口RT, 只有在数据量级达到一定程度时, 才有可能带来明显的RT提升, 在数据量级较小时, 它反而可能带来反作用.
资源总结
- 林不渡的GitHub主页
- 本篇文章及相关demo仓库 DataLoader-Source-Explore
- GraphQL-Explorer-Server
- DataLoader
- TypeGraphQL
- Apollo-GraphQL
- TypeGraphQL-DataLoader
- NestJS-DataLoader
- Prisma 2
常见问题FAQ
- 免费下载或者VIP会员专享资源能否直接商用?
- 本站所有资源版权均属于原作者所有,这里所提供资源均只能用于参考学习用,请勿直接商用。若由于商用引起版权纠纷,一切责任均由使用者承担。更多说明请参考 VIP介绍。
- 提示下载完但解压或打开不了?
- 找不到素材资源介绍文章里的示例图片?
- 模板不会安装或需要功能定制以及二次开发?




发表评论
还没有评论,快来抢沙发吧!