所谓模板,是我们写在template标签中的内容。
模板编译,则是将这一部分内容处理成render函数代码字符串的过程。
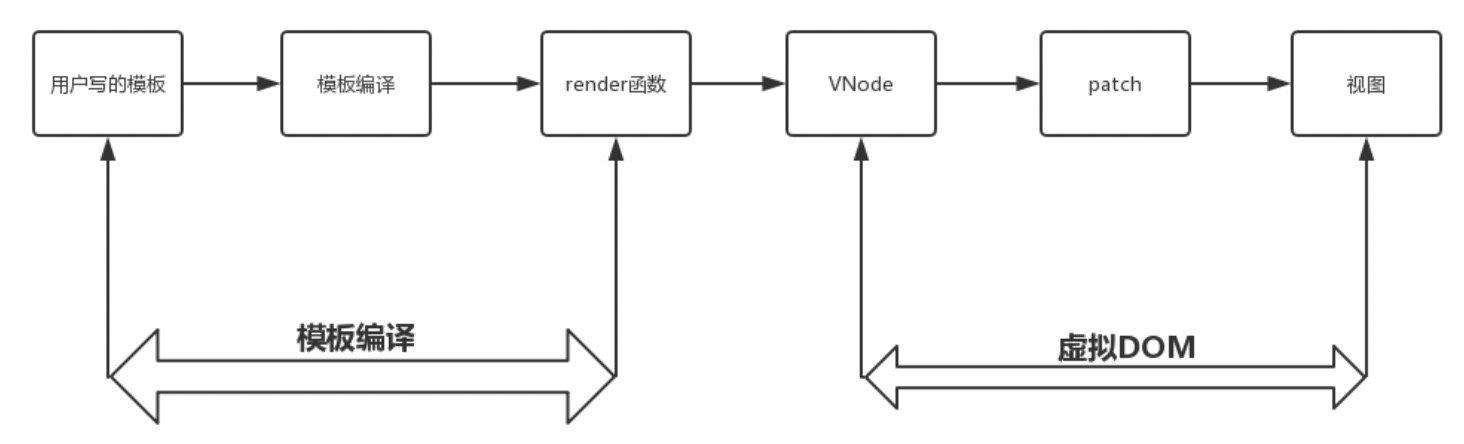
模版编译整体逻辑主要分三部分:
- 将模板字符串解析成AST树(抽象语法树)
- 对AST进行静态节点标记,用于虚拟DOM的渲染优化
- 将AST转换成render函数代码字符串
下面详细介绍一下这三个阶段
-
模板解析
先来看一个?,有个基本的认识,了解解析之后的AST结构大概是什么样子的。
// 模板 <div> <p>{{name}}</p> </div>// 解析之后的AST是一个js对象,对象的属性代表标签的关键有效信息 { tag: "div" type: 1, staticRoot: false, // 优化之后才有的 static: false, // 优化之后才有的 plain: true, parent: undefined, attrsList: [], attrsMap: {}, children: [ { tag: "p" type: 1, staticRoot: false, static: false, plain: true, parent: {tag: "div", ...}, attrsList: [], attrsMap: {}, children: [{ type: 2, text: "{{name}}", static: false, expression: "_s(name)" }] } ] }我们根据源码来看一下解析过程的实现。
/** * Convert HTML string to AST. * 将HTML模板字符串转化为AST */ export function parse(template, options) { // ... // 核心代码 parseHTML(template, { warn, expectHTML: options.expectHTML, isUnaryTag: options.isUnaryTag, canBeLeftOpenTag: options.canBeLeftOpenTag, shouldDecodeNewlines: options.shouldDecodeNewlines, shouldDecodeNewlinesForHref: options.shouldDecodeNewlinesForHref, shouldKeepComment: options.comments, // 当解析到开始标签时,调用该函数 /** * tag:标签名 * attrs:标签属性 * unary: 是否是自闭合标签 */ start (tag, attrs, unary) { // 将解析得到的标签推入栈 }, // 当解析到结束标签时,调用该函数 end () { // 将解析得到的结束标签对应的开始标签推出栈 }, // 当解析到文本时,调用该函数。区分是动态文本或者是纯静态文本 chars (text) { }, // 当解析到注释时,调用该函数 comment (text) { } }) return root }parseHTML 的主要逻辑是使用while循环template模板字符串,使用正则依次取标签名,属性,文本,闭合标签,并用advance移动游标,匹配下一个字符串的类型以做对应的处理,直至结尾。
// parseHTML的主要代码 export function parseHTML (html, options) { let last, lastTag while (html) { last = html if (!lastTag || !isPlainTextElement(lastTag)) { let textEnd = html.indexOf('<') // 注释、条件注释、Doctype、开始标签、结束标签 if (textEnd === 0) { // Comment: if (matchComment) { advance(commentLength) continue } // 条件注释 if (matchConditionalComment) { advance(conditionalCommentLength) continue } // Doctype: const doctypeMatch = html.match(doctype) if (doctypeMatch) { advance(doctypeMatch[0].length) continue } // End tag: const endTagMatch = html.match(endTag) if (endTagMatch) { const curIndex = index advance(endTagMatch[0].length) parseEndTag(endTagMatch[1], curIndex, index) continue } // Start tag: const startTagMatch = parseStartTag() if (startTagMatch) { handleStartTag(startTagMatch) continue } } else { // 文本 } } } }开始标签的处理parseStartTag、handleStartTag
parseStartTag:匹配
<标签名属性>handleStartTag:
用正则匹配出开始标签(且非自闭合标签)后,还要维护一个用来保证构建的
AST节点层级与真正DOM层级一致的stack。stack中的最后一项一定是当前正在解析的节点。解析到开始标签,会把这个节点push到stack中,再匹配到子元素的开始标签,会把子元素节点push到stack中,而stack会把当前节点push到付节点的children中,并把当前节点的parent设置为父节点。advance函数是用来移动解析游标的,解析完一部分就把游标向后移动一部分,确保不会重复解析。匹配属性直至匹配到开始标签的结尾标记
>.结束标签的处理
-
使用正则匹配到结束标签,把当前标签从stack中pop出来。
-
删除结束标签后的空格
parseHtml 两类解析器
- parseText
- parseFilters
-
-
优化阶段
经过了第一阶段,我们已经得到了解析好的AST树。在优化阶段主要做了两件事:
- 在
AST中找出所有静态节点并打上标记; - 在
AST中找出所有静态根节点并打上标记;
静态跟节点:子节点全是静态节点的节点。
那么怎么区分节点是否是静态节点呢?
在我们得到的AST中有一个type属性,1代表元素节点,2代表包含变量的动态文本节点,3代表不包含变量的纯文本节点。
循环判断所有节点,如果当前节点是元素节点,则需要递归判断所有子节点。
为什么要标记静态节点?有什么好处?
-
每次重新渲染的时候不需要为静态节点创建新节点
-
在 Virtual DOM 中 patching 的过程可以被跳过
- 在
-
代码生成
前文例子中生成的render 如下:
{ render: `with(this){return _c('div',[_c('p',[_v(_s(name))])])}` } // 格式化 with(this){ return _c( // _c对应createElement,创建一个元素(标签名, 属性对象(可选), children) 'div', [ _c( 'p', [ _v(_s(name)) // _v 是创建一个文本节点;_s 是返回参数中的字符串 ] ) ] ) }
常见问题FAQ
- 免费下载或者VIP会员专享资源能否直接商用?
- 本站所有资源版权均属于原作者所有,这里所提供资源均只能用于参考学习用,请勿直接商用。若由于商用引起版权纠纷,一切责任均由使用者承担。更多说明请参考 VIP介绍。
- 提示下载完但解压或打开不了?
- 找不到素材资源介绍文章里的示例图片?
- 模板不会安装或需要功能定制以及二次开发?





发表评论
还没有评论,快来抢沙发吧!