深度遍历(DFS)和广度遍历(BFS)是数据结构遍历的两种常用方式,广泛运用在处理树形结构的数据类型,例如:处理目录、数据结构树形化、diff算法等等。DFS的处理逻辑如下(左)BFS如下(右)。
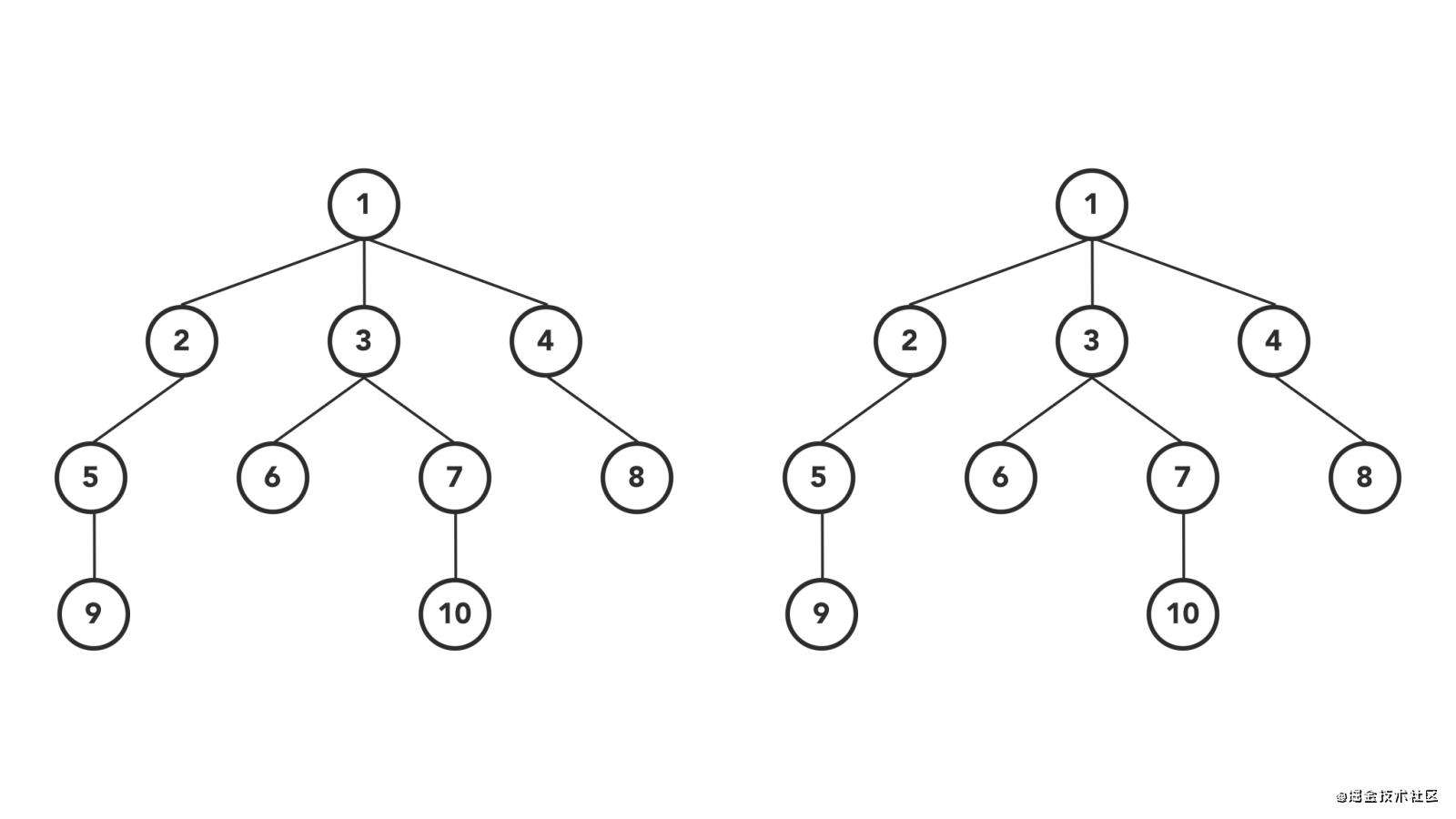 两种方式都会把整个节点走一遍,
两种方式都会把整个节点走一遍,深度优先遍历是以分支为一条路线,处理逻辑为9 -> 5 -> 2 -> 6 -> 10 -> 7,可以发现规律是为触碰到某个分支的最后一个节点(这个节点下没有子节点),就会向上冒泡,形象的说就是:
广度优先遍历是以等级作为路线,处理逻辑为1 -> 2 -> 3 -> 4 -> 5,和深度优先遍历不同,广度优先遍历不关心是否有子节点,他只关心排队在当前节点后的那个节点是什么,形象的说就是:
弄清概念之后,下面开始code example,用比较常见的nodejs处理目录的例子来解释这两种遍历模式
深度优先遍历
以上面的gif为目录结构,做些改造,偷偷加两个文件:
/1
|---/2
|-------/5
|------------/9
|--------2.index.js
|---/3
|-------/6
|-------/7
|-----------/10
|---/4
|-------4.index.js
|-------/8
用深度优先遍历,把目录结构变成形如:
[
{ name: 1, children: [{ name: 2, children: [{ name: 5, children: [{ name: 9 }] }, { name: '2.index.js' }] }] },
{
name: 3,
children: [
{ name: 6, children: [] },
{ name: 7, children: [] }
]
},
{ name: 4, children: [{ name: '4.index.js' }, { name: 8, children: [] }] }
];
代码如下:
/*
* 递归的处理逻辑,把处理路径传给递归处理函数
* 如果这个路径类型是文件夹,那么创建children字段,并把目录push到children
* 例如第一次生成的result => [{name: 9}]
* 第二次遍历的目录5,要把上一次的name: 9 变成name: 5的 children 的一项
* 做到处理每一个节点的关键是,我们每次递归都要把子目录的dir作为参数传下去
*/
function dfs(dir) {
const result = [];
if (fs.statSync(dir).isDirectory()) {
const dirs = fs.readdirSync(path.resolve(__dirname, dir));
dirs.forEach(filename => {
const curFilePath = dir + path.sep + filename;
if (fs.statSync(curFilePath).isDirectory()) {
const block = { name: filename, children: [] };
block.children.push(...dfs(curFilePath));
result.push(block);
} else {
result.push({ name: filename });
}
});
}
return result;
}
console.log(dfs('1'))
广度优先遍历
整个深度优先遍历,不仅使用了迭代计算(创建一个result数组作为命名空间)而且必须使用递归计算,递归比较耗性能和不稳定,在处理上述这类树形重组比较实用,当我们只需要找到每一个节点,或者对某些节点做一些操作,就可以优先使用广度优先遍历,例如上述例子,找出目录中的所有.js文件:
/**
* bfs会把节点拍平,添加到数组末
* 每次操作完,会把这一项去掉
* 整个流程是先添加,再处理,处理完成就删除
*/
function bfs(dir) {
const stack = [];
if (fs.statSync(dir).isDirectory()) {
const dirs = fs.readdirSync(path.resolve(__dirname, dir));
dirs.forEach(filename => {
stack.push(dir + path.sep + filename);
});
while (stack.length) {
const item = stack.shift();
if (path.extname(item) === '.js') {
console.log(item);
}
if (fs.statSync(item).isDirectory()) {
stack.push(...fs.readdirSync(path.resolve(__dirname, item)).map(file => item + path.sep + file));
}
}
}
}
bfs('1'); // 输出 1/2/2.index.js 和 1/4/4.index.js
总结
本文抛砖引玉的介绍了两种常见的遍历模式,在选择上如果是case1这种结构重组,建议使用深度优先,如果只是数据提取或修改,建议使用广度优先避免递归带来的麻烦。
常见问题FAQ
- 免费下载或者VIP会员专享资源能否直接商用?
- 本站所有资源版权均属于原作者所有,这里所提供资源均只能用于参考学习用,请勿直接商用。若由于商用引起版权纠纷,一切责任均由使用者承担。更多说明请参考 VIP介绍。
- 提示下载完但解压或打开不了?
- 找不到素材资源介绍文章里的示例图片?
- 模板不会安装或需要功能定制以及二次开发?



发表评论
还没有评论,快来抢沙发吧!