前言

定义
正则表达式(Regular Expression)是一个描述字符模式的对象,JavaScript中的正则表达式用RegExp对象表示,可以使用RegExp()构造函数来创建RegExp对象,但更多时候是用直接量语法来创建。
// 通过构造函数来创建: new RegExp(pattern,modifiers)
var reg = new RegExp("\\ba\\b","g")
//全局查找单词a,\b表示匹配一个单词边界,g表示全局匹配
// 直接创建: /pattern/modifiers
var reg = /\ba\b/g
//pattern(模式) 描述了表达式的模式
//modifiers(修饰符) 用于指定全局匹配、区分大小写的匹配和多行匹配
这里介绍一个在线解析正则的网站,可以将正则表达式图形化:www.regexper.com(由于是国外网站,会出现访问慢或者打不开的情况,可以去 GitLab 下载源码安装在自己的电脑上使用)
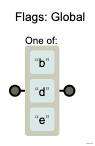
var reg = /[bde]/g //全局匹配bde中任何一个字符
语法
JavaScript 正则表达式中的所有字母和数字都是按照字面含义进行匹配的,比如 /javascript/ 可以匹配所有包含 javascript 的字符串,此外还支持非字母的字符匹配,这些字符需要通过反斜杠\进行转义,构成转义字符/\//:
var str = 'I have a banana and a pear'
//把单词a换成A
//使用字符串的replace函数
var reg = /a/ //匹配字符a
str.replace(reg,'A') //I hAve a banana a pear
//这时候发现把单词中的a也替换成大写A了,我们只想把单词a换成大A
//需要我们需要制定他的匹配位置,需要用到\b来匹配单词边界:单词和符号之间的边界
reg = /\ba\b/
str.replace(reg,'A') //I have A banana a pear
//元字符^的用法,匹配字符串开头
var reg1 = /b/g
'babbaa'.replace(reg1,'B') //BdBBaa 将所有b匹配到了
//现在加上^字符后,只会匹配字符串的开头的b
reg1 = /^b/g //Bdbbaa
//元字符$的用法,匹配字符串结尾
reg1 = /a$/g
'babbaa'.replace(reg1,'A') //babbaA ,只匹配字符串结尾处的a
//元字符\B的用法,匹配非单词边界,就是字符与字符之间的位置
reg1 = /\B/g
'ab cd'.replace(reg1,'A') //aAb cAd 匹配到两个字符之间的边界
元字符-位置类
| 字符 | 含义 | 英文 | ^ | 匹配字符串的开头 | $ | 匹配字符串的结尾 | \b | 匹配一个单词的边界,就是位于字符\w和\W之间的位置,或位于\w与字符串开头或结尾的位置 | boundary | \B | 匹配非单词边界的位置 | boundary |
|---|
//接上面匹配替换的结果:I have A banana a pear
//发现,只配了第一个单词a,后面的a没有匹配到,这时候需要用到全局匹配,使用修饰符g
reg = /\ba\b/g
str.replace(reg,'A') //I have A banana and A pear
//这时候两个单词a都被匹配到了。
//修饰符i的用法,忽略大小写
reg = /i/ //现在我们想匹配字符串中的I,并替换成You
str.replace(reg,'You') //I have A banana and A pear ,没有匹配到
//在后面加上i便可忽略大小写进行匹配
reg = /i/i
str.replace(reg,'You') //You have a banana and an pear
//修饰符m的用法,多行匹配
var str1 = `11
12
13`
//现在我们想将3个字符开头的1替换成5
var reg1 = /^1/g
str1.replace(reg1,'5')
//51
//12
//13
//根据结果只替换了第一个字符,因为即使字符串看上去换行,本质上还是一些换行符,只有结尾和结束
//现在加上修饰符m来处理
var reg1 = /^1/gm
str1.replace(reg1,'5')
//51
//52
//53
//成功将三个字符开头的1替换成了5
修饰符
修饰符用于执行区分大小写和全局匹配:
| 字符 | 含义 | 英文 | i | 执行对大小写不敏感的匹配。 | ignore case | g | 执行全局匹配(不止匹配第一个) | global | m | 执行多行匹配。 | multiple lines |
|---|
//上面提到了多行匹配,正则表达式的语法中也提供了匹配换行符的方法,使用 \n
//继续使用上面定义的str1字符串
var str1 = `11
12
13`
reg1 = /\n/g
str1.replace(reg1,'5') // 11512513
//这时候原字符串不换行了,因为换行符全被替换成了5
//匹配制表符\t的使用
var str1 = 'a aa aaa';
var reg1 = /\t/g
str1.replace(reg1,'b') //abaabbaaa ,将所有制表符换成了字符b
//匹配垂直制表符\v
console.log('i am \v Kyree') //i am Kyree
//javaScript 中没有垂直制表符,在C中会在垂直制表符位置换行继续输出
//匹配换页符/f,一般情况用不到,在提取word文档的中内容可以用到
//匹配回车符/r,\r 代表的是 回车符(ACSII: 13 或0x0d), 也就是"硬回车"
// \n 代表的是 换行符(ACSII: 10 或 0x0a), 也就是 "软回车"
元字符-转义类
| 字符 | 含义 | 英文 | \o | NULL字符 | ignore case | \t | 制表符 | tabulator | \n | 换行符 | newline | \v | 垂直制表符 | verticality | \f | 换页符 | form feed | \r | 回车符 | return | \xnn | 十六进制数nn指定的字符 | \uxxxx | 十六进制数xxxx指定的Unicode字符 | Unicode | \cX | 控制字符^X | Control | \ | 反斜杠\ |
|---|
//有时候我们想匹配一个字符串中所包含的任意字符,这时候便需要用到 []
var str1 = 'abcd12345';
var reg1 = /[bde]/g
str1.replace(reg1,'6') //a6c612345,只要匹配到了b或者d或者e,便将其替换成6
//方括号前面加上^便是取反的意思,不在方括号内的任意字符
reg1 = /[^bde]/g
str1.replace(reg1,'6') //6b6d66666,只要不是b或者d或者e的,全部替换成6
// . 除了换行符以外的任意字符
reg1 = /./g
str1.replace(reg1,'6') //666666666 ,等价于[^\n\r]
// 匹配大小写字母或者数字 \w
var str1 = '我有1个iPhone手机';
var reg1 = /\w/g
str1.replace(reg1,'a') //我有a个aaaaaa手机,将数字和大小写字母都匹配到了
// 匹配非大小写字母或者数字 \W
reg1 = /\W/g
str1.replace(reg1,'a') //aa1aiPhoneaa,除了数字和大小写字母意外,都匹配到了
// 匹配空白符、空格,/s
var str1 = '我 有1个iP hone手 机';
var reg1 = /\s/g
str1.replace(reg1,'a') //我a有1个iPahone手a机,将空格符都替换成了a
//同样取反是大写的 ,\S ,匹配任何非空白符
reg1 = /\S/g
str1.replace(reg1,'a') //a aaaaa aaaaa a ,忽略掉了所有空白符
//匹配任何数字 \d
var str1 = '1个iPhone,2台Mac';
var reg1 = /\d/g
str1.replace(reg1,'a') //a个iPhone,a台Mac
元字符-字符类
| 字符 | 含义 | 英文 | [...] | 方括号内的任意字符 | [^...] | 不在方括号内的任意字符 | . | 除换行符及其他Unicode行终止符之外的任意字符,等价 [^\n\r] | \w | 任何ASCII字符组成的单词,等价于[a-zA-Z0-9] | words | \W | 任何非ASCII字符组成的单词,等价于[^a-zA-Z0-9] | words | \s | 任何Unicode空白符 | space | \S | 任何非Unicode空白符的字符 | space | \d | 任何ASCII数字,等价于[0-9] | digits | \D | 除ASCII数字之外的任意字符,等价于[^0-9] | digits | [\b] | 退格符(特例) | backspace |
|---|
//当需要对同一类型进行多次匹配的时候,这时候就需要用到量词
//比如说,使用{n}来匹配前一项n次
var str1 = '123456';
var reg1 = /\d{4}/g //匹配字符串中出现4次数字的情况
str1.replace(reg1,'a') //a56,
//第一次匹配到出现4次数字的情况,将1234替换成a,a56不符合匹配规则,匹配停止
str1 = '123456789'
str1.replace(reg1,'a')//aa9
//这时候第一次匹配完后,变成a56789,符合规则继续匹配后,变成aa9,aa9不符合规则,匹配停止
// {n,m} 代表前一项至少n次,但不能超过m次,小于等于m
var str1 = '12345';
var reg1 = /\d{2,4}/g //字符串中匹配至少出现2次数字,最多出现4次数字
str1.replace(reg1,'a') // a5
//匹配重复字符是尽可能多的匹配,所以是先匹配出现4次的情况,变成a5后,不符合规则,停止匹配
//这种尽可能匹配多的模式 称为贪婪模式
//如果想进行非贪婪的匹配,只需在待匹配的字符后面跟上一个问号即可
reg1 = /\d{2,4}?/g
str1.replace(reg1,'a') // aa5 ,这时候就尽可能从最少的来匹配
元字符-重复类
| 字符 | 含义 | {n,m} | 匹配前一项至少n次,但不能超过m次 | {n,} | 匹配前一项至少n次 | {n} | 匹配前一项n次 | ? | 匹配前一项0次或1次,等价于{0,1},最多出现一次 | + | 匹配前一项1次或多次,等价于{1,},至少出现一次 | * | 匹配前一项0次或多次,等价于{0,} |
|---|
//如果想匹配出现多个单词的情况,这时候就需要用到分组匹配
//现在我们想把出现2次iPhone的替换成iPad
'iPhoneiPhonee'.replace(/iPhone{2}/g,'iPad') //iPhoneiPad
//这样写的话,是先匹配iPhon,接着匹配出现2次e的情况,所以后面的iPhonee被替换成了iPad
//这种情况需要用到分组匹配符 ()
'iPhoneiPhonee'.replace(/(iPhone){2}/g,'iPad') //iPade ,成功匹配到了
//选择符或 |
'ab'.replace(/a|ab/g,'c') //cb,匹配a或者ab,从左往右顺序,所以最终只有a被匹配到了
//分组和选择的结合
'abdacd'.replace(/a(b|c)d/g,'X') // XX ,表示abd或者acd都符合匹配规则
//分组的反向引用,分组捕获
//现在想要将日期字符串更改表示方法:2020-12-14=>12/14/2020
var reg = /\d{4}-\d{2}-\d{2}/ //首先是匹配到初始日期的字符串
//接着将正则表达式进行分组
reg = /(\d{4})-(\d{2})-(\d{2})/
//最后使用$进行分组捕获,此时
//$1代表(\d{4})值为2020
//$2代表(\d{2})值为12
//$3代表(\d{3})值为14
//最后在捕获到的分组之间加上/进行替换
'2020-12-14'.replace(/(\d{4})-(\d{2})-(\d{2})/,'$2/$3/$1') //12/14/2020
//分组忽略,如果想将某一个分组忽略掉,只要在前面加上?:即可。
reg = /(?:\d{4})-(\d{2})-(\d{2})/
//此时分组捕获2020已经被忽略掉了
//$1代表(\d{2})值为12
//$2代表(\d{3})值为14
元字符-操作类
| 字符 | 含义 | | | 选择,匹配该字符左边或右边的表达式 | (...) | 组合,将几个项组成一个单元 | (?:...) | 只组合,不可引用 |
|---|
//RegExp对象为我们提供了3种方法
//exec 检索字符串中指定的值,返回一个数组,其中存放匹配的结果。如果未找到匹配,则返回值为null
var str = 'I have an banana'
var reg = /a/g
reg.exec(str)
//输出结果
/*
[
'a', //第一个元素是与正则表达式相匹配的文本
index: 3, //index: 表示匹配项在字符串中的位置,也就是匹配项第一个字符的位置
input: 'I have an banana', //input: 表示应用正则表达式的字符串
groups: undefined
]
*/
// 正则表达式中分组匹配的情况
var str = '2020-12-15'
var reg = /(\d{4})-(\d{2})-(\d{2})/
reg.exec(str)
/*[
'2020-12-15',//第一个元素是与正则表达式相匹配的文本
'2020',//第二个元素是与正则对象第一个子表达式相匹配的文本,也就是第一个分组(如果有的话)
'12',//第三个元素是与正则对象第二个子表达式相匹配的文本,也就是第二个分组(如果有的话)
'15',//第四个元素是与正则对象第三个子表达式相匹配的文本,也就是第三个分组(如果有的话)
index: 0,//index: 表示匹配项在字符串中的位置,也就是匹配项第一个字符的位置
input: '2020-12-15',//input: 表示应用正则表达式的字符串
groups: undefined
]*/
//如果正则表达式有g标识,在每次执行完exec后,该正则对象的lastIndex值就会被改变,
//该值表示下次匹配的开始下标
var str = 'I have an banana'
var reg = /a/g
reg.exec(str) //[ 'a', index: 3, input: 'I have an banana', groups: undefined ]
reg.lastIndex //4
reg.exec(str) //[ 'a', index: 7, input: 'I have an banana', groups: undefined ]
reg.lastIndex //8
//输出结果中的groups的含义:用来存储命名捕获组的信息
var str = 'ab'
var reg = /(?<first>\w)(?<second>\w)/ //语法为:(?<捕获组的名字>捕获组对应的规则)
reg.exec(str).groups// { first: 'a', second: 'b' }
//test():用来查看正则表达式与指定的字符串是否匹配。匹配到返回 true,否则返回false。
var str = 'ab'
var reg = /a/
var reg1 = /c/
reg.test(str) //true
reg1.test(str) //false
//当正则表达式使用全局模式时,lastIndex属性会影响test()方法的返回值
var str = 'ab'
var reg = /\w/g
reg.test(str)+',lastindex:'+reg.lastIndex //true,lastindex:1
reg.test(str)+',lastindex:'+reg.lastIndex //true,lastindex:2
reg.test(str)+',lastindex:'+reg.lastIndex //false,lastindex:0 ,再次变成0
reg.test(str)+',lastindex:'+reg.lastIndex //true,lastindex:1
//toString:返回正则表达式的字符串
var reg = /\w/g
reg.toString() // /\w/g
RegExp 对象方法
| 方法 | 描述 | exec | 检索字符串中指定的值。返回找到的值,并确定其位置。 | test | 检索字符串中指定的值,返回 true 或 false。 | toString | 返回正则表达式的字符串。 |
|---|
//在string对象中,也有支持正则表达式的方法
//search方法执行正则表达式和 String对象之间的一个搜索匹配
//如果匹配成功,返回正则表达式在字符串中首次匹配项的索引,否则返回-1。
'ab'.search(/b/) //1
'ab'.search(/c/) //-1
//match(),用于搜索字符串,找到一个或多个与正则表达式匹配的字符
//返回:一个包含了整个匹配结果以及任何括号捕获的匹配结果的 Array ;如果没有匹配项,则返回 null。
'I hava a banana'.match(/a/)//[ 'a', index: 3, input: 'I hava a banana', groups: undefined ]
//全局匹配,返回一个数组,存放字符串中所有匹配的字符串
'I hava a banana'.match(/a/g)//[ 'a', 'a', 'a', 'a', 'a', 'a' ]
//replace()方法,原字符不变的情况下,返回一个由替换值替换一些或所有匹配的模式后的新字符串
'a1b2c3d'.replace(/\d/,'X') //aXbXcXd
//分隔符split() ,使用指定的分隔符字符串将一个String对象分割成字符串数组
//语法:str.split([separator[, limit]]);
'a, b, c, d'.split(/,/) //["a", " b", " c", " d"]
'a, b, c, d'.split(,) //["a", " b", " c", " d"],当separator为字符串时,其实也是默认转成正则去执行
//分组分割
'a1b2c3'.split(/(\d)/) //["a", "1", "b", "2", "c", "3", "d"]
//限制返回值中分割元素数量
'a1b2c3'.split(/(\d)/,3) //[ 'a', '1', 'b' ]
String 对象方法
| 方法 | 描述 | search | 检索与正则表达式相匹配的值。 | match | 找到一个或多个正则表达式的匹配。 | replace | 替换与正则表达式匹配的子串。 | split | 把字符串分割为字符串数组。 |
|---|
//当然,RegExp对象也内置很多属性
//constructor ,返回一个函数,该函数是一个创建RegExp对象的原型
var reg = new RegExp('a','g')
reg.constructor //ƒ RegExp() { [native code] }
//global 判断是否设置了g修饰符
//ignoreCase 判断是否设置了i修饰符
//multiline 判断是否设置了m修饰符
var reg = /a/g
reg.global // true
reg.ignoreCase //false
reg.multiline //false
//lastIndex 设置下次匹配的开始位置,该属性只有设置了g标志才能使用
var str = 'ab'
var reg = /\w/g
reg.test(str)+',lastindex:'+reg.lastIndex //true,lastindex:1
reg.test(str)+',lastindex:'+reg.lastIndex //true,lastindex:2
reg.lastIndex = 0 //此时手动将lastIndex设置为0,所以下列输出为true,否则为false
reg.test(str)+',lastindex:'+reg.lastIndex //true,lastindex:1
RegExp 对象属性
| 属性 | 描述 | constructor | 返回一个函数,该函数是一个创建 RegExp 对象的原型。 | global | 判断是否设置了 "g" 修饰符 | ignoreCase | 判断是否设置了 "i" 修饰符 | lastIndex | 用于规定下次匹配的起始位置 | multiline | 判断是否设置了 "m" 修饰符 | source | 返回正则表达式的匹配模式 |
|---|
常用场景
检测用户名
非中文用户名
规则如下
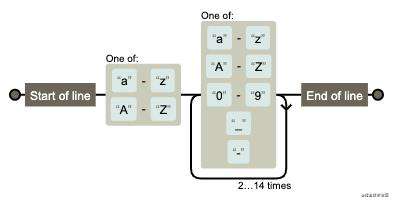
- 最短4位,最长16位 {4,16}
- 可以包含小写大母 [a-z] 和大写字母 [A-Z]
- 可以包含数字 [0-9]
- 可以包含下划线 [ _ ] 和减号 [ - ]
- 首字母只能是大小写字母
var reg = /^[a-zA-Z][a-zA-Z0-9_-]{3,15}$/;
reg.test('kyree') //true
reg.test('3Mike') // false
图解:
中文用户名
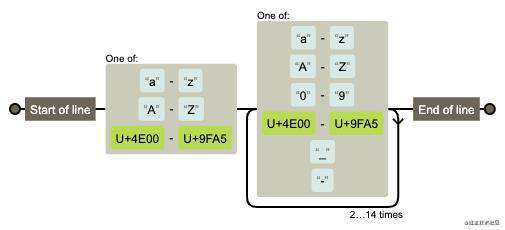
// [\u4E00-\u9FA5]是汉字的正则匹配,包括基本汉字2万多个
var reg = /^[a-zA-Z\u4E00-\u9FA5][a-zA-Z0-9\u4E00-\u9FA5_-]{3,15}$/;
reg.test('CV打字员') //true
reg.test('kyree@') //false
图解:
检测密码强度
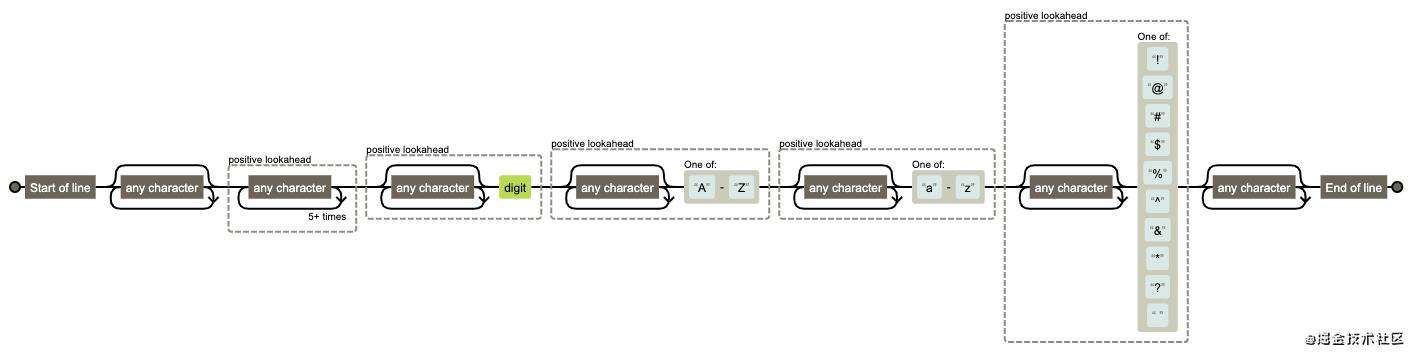
密码规则:最少6位,包括至少1个大写字母,1个小写字母,1个数字,1个特殊字符
var reg = /^.*(?=.{6,})(?=.*\d)(?=.*[A-Z])(?=.*[a-z])(?=.*[!@#$%^&*? ]).*$/;
reg.test('Kyree123@') //true
reg.test('kyree..') //false
图解:
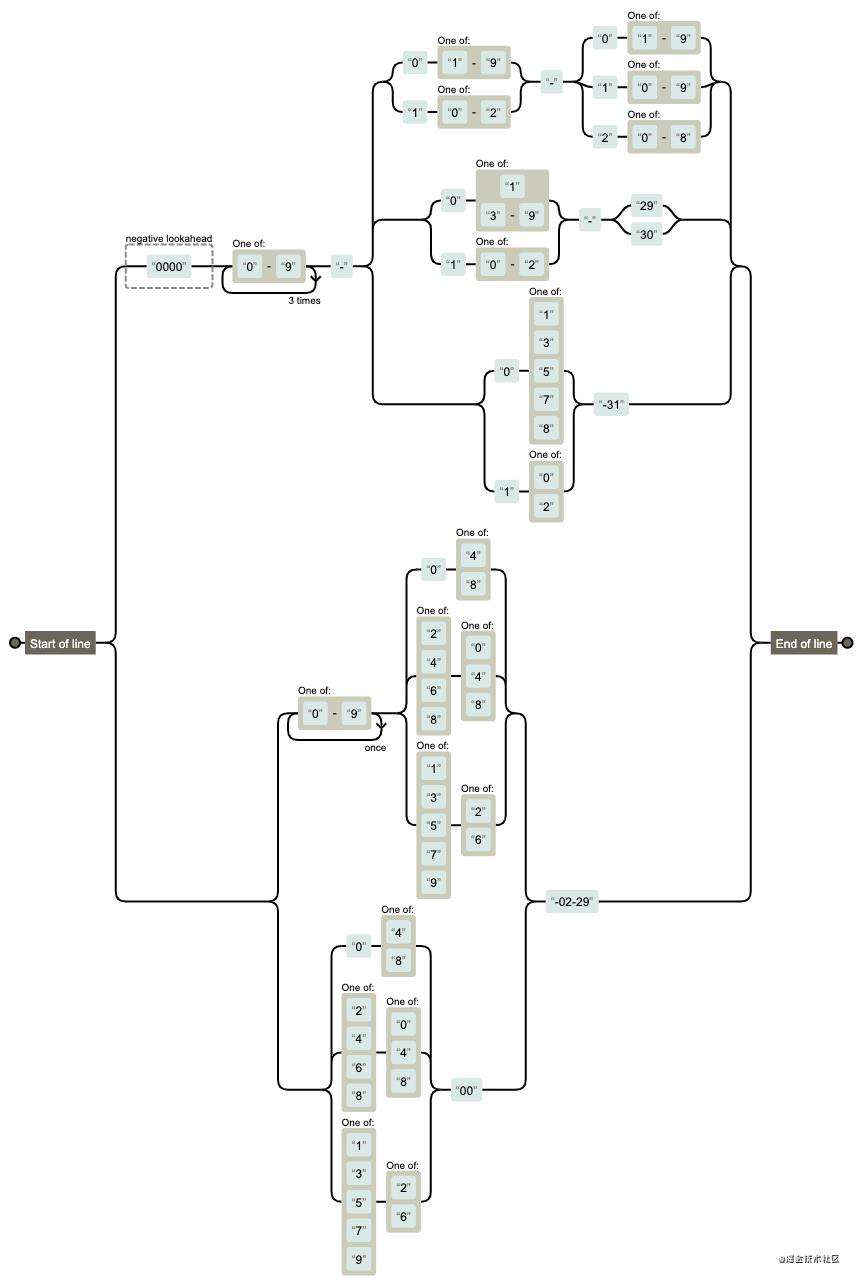
检测日期
var reg = /^(?:(?!0000)[0-9]{4}-(?:(?:0[1-9]|1[0-2])-(?:0[1-9]|1[0-9]|2[0-8])|(?:0[13-9]|1[0-2])-(?:29|30)|(?:0[13578]|1[02])-31)|(?:[0-9]{2}(?:0[48]|[2468][048]|[13579][26])|(?:0[48]|[2468][048]|[13579][26])00)-02-29)$/;
reg.test('2020-12-15') //true
reg.test('2021-02-29') //false ,2021年的2月只有28天
图解:
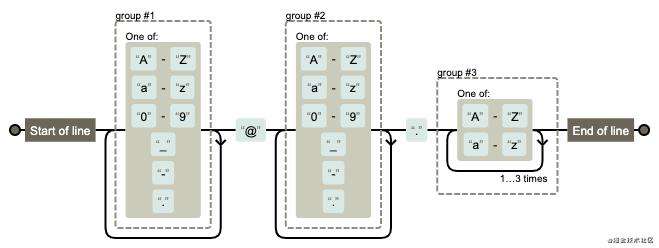
检测邮箱地址
var reg = /^([A-Za-z0-9_\-\.])+\@([A-Za-z0-9_\-\.])+\.([A-Za-z]{2,8})$/
reg.test('kyreem@163.com') //true
reg.test('kyreem@163.163') //false
图解:
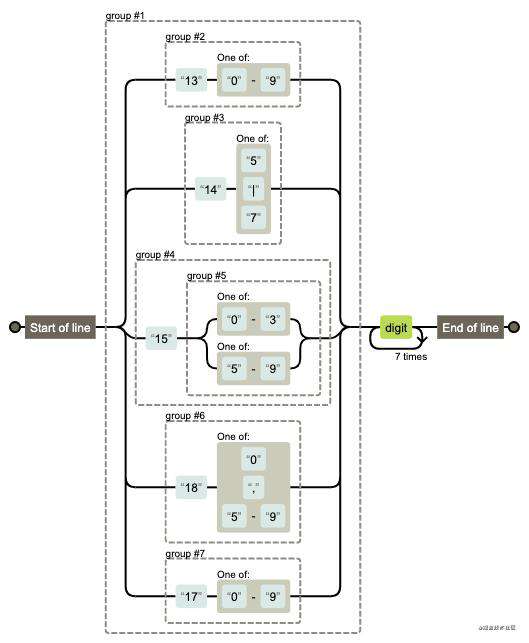
检测手机号码
var reg = /^((13[0-9])|(14[5|7])|(15([0-3]|[5-9]))|(18[0,5-9]))\d{8}$/;
reg.test('13088888888') //true
reg.test('12062516875') //false
图解:
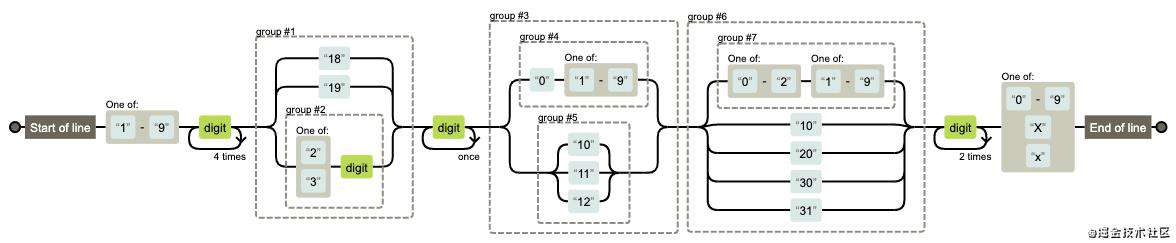
检测身份证号码
//身份证号码18位
var reg = /^[1-9]\d{5}(18|19|([23]\d))\d{2}((0[1-9])|(10|11|12))(([0-2][1-9])|10|20|30|31)\d{3}[0-9Xx]$/;
reg.test('110105199806053713') //true
reg.test('110105199806323713') //false
图解:
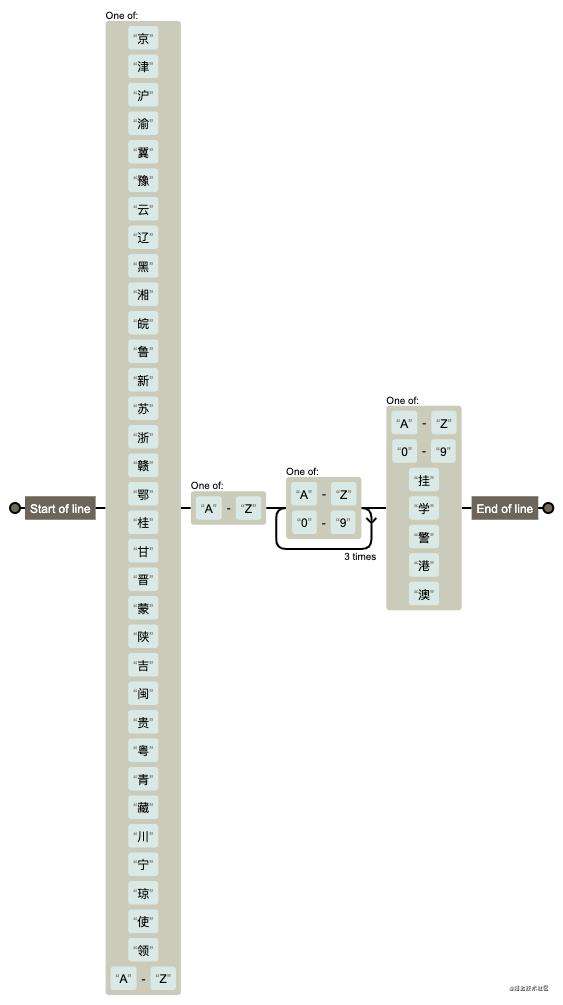
检测车牌号
var reg = /^[京津沪渝冀豫云辽黑湘皖鲁新苏浙赣鄂桂甘晋蒙陕吉闽贵粤青藏川宁琼使领A-Z]{1}[A-Z]{1}[A-Z0-9]{4}[A-Z0-9挂学警港澳]{1}$/;
reg.test('苏A86826') //true
reg.test('江B53893') //fasle
图解:
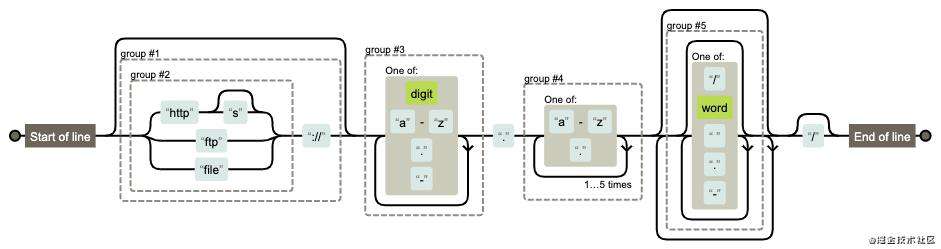
检测URL地址
var reg = /^((https?|ftp|file):\/\/)?([\da-z\.-]+)\.([a-z\.]{2,6})([\/\w \.-]*)*\/?$/
reg.test('http://www.test.com') //true
reg.test('http:\\www.test.com') //false
图解:
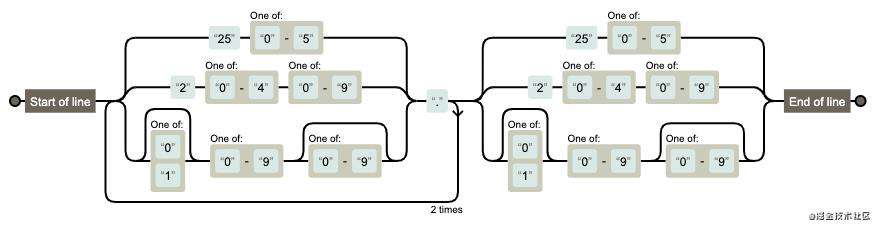
检测ip地址
ipv4地址
var reg = /^(?:(?:25[0-5]|2[0-4][0-9]|[01]?[0-9][0-9]?)\.){3}(?:25[0-5]|2[0-4][0-9]|[01]?[0-9][0-9]?)$/;
reg.test("115.28.47.26"); //true
图解:
IPv6地址
var reg =/(([0-9a-fA-F]{1,4}:){7,7}[0-9a-fA-F]{1,4}|([0-9a-fA-F]{1,4}:){1,7}:|([0-9a-fA-F]{1,4}:){1,6}:[0-9a-fA-F]{1,4}|([0-9a-fA-F]{1,4}:){1,5}(:[0-9a-fA-F]{1,4}){1,2}|([0-9a-fA-F]{1,4}:){1,4}(:[0-9a-fA-F]{1,4}){1,3}|([0-9a-fA-F]{1,4}:){1,3}(:[0-9a-fA-F]{1,4}){1,4}|([0-9a-fA-F]{1,4}:){1,2}(:[0-9a-fA-F]{1,4}){1,5}|[0-9a-fA-F]{1,4}:((:[0-9a-fA-F]{1,4}){1,6})|:((:[0-9a-fA-F]{1,4}){1,7}|:)|fe80:(:[0-9a-fA-F]{0,4}){0,4}%[0-9a-zA-Z]{1,}|::(ffff(:0{1,4}){0,1}:){0,1}((25[0-5]|(2[0-4]|1{0,1}[0-9]){0,1}[0-9])\.){3,3}(25[0-5]|(2[0-4]|1{0,1}[0-9]){0,1}[0-9])|([0-9a-fA-F]{1,4}:){1,4}:((25[0-5]|(2[0-4]|1{0,1}[0-9]){0,1}[0-9])\.){3,3}(25[0-5]|(2[0-4]|1{0,1}[0-9]){0,1}[0-9]))/;
reg.test("fe80:0000:0000:0000:0204:61ff:fe9d:f156"); //true
由于图解太过复杂,想了解的同学可以去这个网站上www.regexper.com 进行解析查看。
结语
感谢你看到这里,文章可能还有不足和需要改正的地方,欢迎在评论区留下你的建议。如果觉得本篇文章对你有点帮助的话,可以点赞或者分享给你的朋友。
常见问题FAQ
- 免费下载或者VIP会员专享资源能否直接商用?
- 本站所有资源版权均属于原作者所有,这里所提供资源均只能用于参考学习用,请勿直接商用。若由于商用引起版权纠纷,一切责任均由使用者承担。更多说明请参考 VIP介绍。
- 提示下载完但解压或打开不了?
- 找不到素材资源介绍文章里的示例图片?
- 模板不会安装或需要功能定制以及二次开发?



发表评论
还没有评论,快来抢沙发吧!