本文作者:

前言
本文从纯前端出发,因此不会涉及到类似flash或者插件之类跳过浏览器安全检测的操作实现的复制粘贴,完全基于浏览器下的安全限制与一些“奇技淫巧”去实现一个相对较为完整的复制粘贴功能。
本文将从浏览器自身的复制粘贴功能出发,带领大家了解复制粘贴背后的功能实现,对比多个富文本文档实现,在浏览器的各种限制下,如何实现一个基于JSON-MODEL数据并且适用于类富文本的剪切板。
复制粘贴的重要性
面向Google和npm的打工人不可能不了解CV大法有多好,而复制粘贴早已成为我们平时工作生活的一部分。实际上对于文字处理,复制粘贴功能的重要性完全不可想象。
而在代码中,使用表单元素并不少见。在表单元素中,输入框之类可输入载体,我们或许对于内部复制粘贴实现或许不得而知:
例如从外部复制一张图片,粘贴到输入框中,却无法实现,而文字却可以?如何实现文字携带外部样式插入,跟word文档一样?又是如何在富文本中实现复制粘贴图片?如何自定义我们的复制粘贴功能?
复制粘贴的三驾马车
在这里我们需要先了解三个概念:MIME、DataTransfer、clipboardEvent:
媒体类型(MIME)
实际上,当我们在表单元素,例如input,textarea中实现一次完整的复制粘贴,调用的就是浏览器的默认能力。
首先我们要先了解一下什么是MIME:
媒体类型(通常称为 Multipurpose Internet Mail Extensions 或 MIME 类型 )是一种标准,用来表示文档、文件或字节流的性质和格式;
MIME的结构实际上也非常简单:由类型和子类型组成,两个字符串中间用'/'分割组成type/subtype。不允许空格存在。
常见的MIME类型有:text/plain,text/html,image/png,application/json等;
例如我们在写script或者style定义的时候:
<style type="text/css"></style>
<script type="text/javascript"></script>
或者平时请求后端接口的时候:
熟悉接口规范或做过后端服务的应该都知道,content-type字端的定义与后端程序的解析实际上是息息相关的,在调试接口的时候,经常会出现content-type与发送的数据不一致的情况,例如后端需要的是application/json的数据,这时候如果传递的是application/x-www-form-urlencoded格式的话,一般会产生错误的状态码返回。这时候就需要前端针对content-type做相应的数据处理。
当然还有一些特殊的实现:Content-Type: multipart/byteranges; boundary=xxxx去告知浏览器,数据切割成多个部分,实现类似于音视频分段加载的功能;
也就是说浏览器想知道你的数据是什么类型的数据,需要做什么样的解析或者下载处理(例如解析到媒体或者文档文件,一般会当成资源下载),需要通过MIME获知;
在复制粘贴过程中,实际上,也是需要通过MIME去进行对应的解析处理。
DataTransfer

实际上,MDN上的这个解释并不完整,除了drag events还可以在paste,copy,cut等事件上获取。我更倾向于文档中的“移动数据”都可以用DataTransfer来进行定义。DataTransfer有多个属性和方法,但是大部分都是在drag下产生或者才能使用的。例如files只适用于drag事件,如果拖动操作不涉及拖动文件,则属性为空数组:
所以我们只关注items这个属性。items是Data对象;
还有一对方法:
- setData(format,data)用于设置内容;
- getData(format)获取内容;
clipBoardEvent
clipboardEvent是浏览器支持的通用剪切板事件。包括了paste、cut、copy等事件相关;
在复制粘贴下我们也只需要关注这两个属性:
type: 描述了事件的触发类型;
clipboard: 一个DataTransfer对象;
浏览器的默认实现
在浏览器下,一般复制粘贴会使用浏览器通用的标准MIME格式(来源自MDN截图):

例如在input和textarea复制粘贴中都只接收text/plain的MIME类型,这也可能是所有软件(还没遇见过不支持这种格式的)都会支持的默认文本格式。
当然,如果你的input type设置为file是可以支持选择其他文件类型的,这里不多做讨论。
富文本的场景
在富文本中,除了纯文本也就是text/plain这种类型之外,一般还需要支持另外两种MIME类型,分别是text/html和image/png(这里单纯指复制粘贴)
text/html:
例如实现一个功能:从word之类的文档复制粘贴一段文本,要求样式和格式保持一致性,这应该是富文本很常见的功能;
这时候,如果我们直接获取text/plain的话,只能获取到对应的纯文字版本。这时候就需要我们去拿text/html类型的文本。值得注意的是,一般的文字编辑器(word,ppt,金山文档......),获取到的并不是标准的html格式,或者说,带有大量的多余数据,这时候,我们可能需要主动去进行一次数据清洗,只保留我们需要的数据。一般可以在获取数据后,使用正则去清除多余的数据,在ueditor、wangeditor等常见的富文本中可以看到对应的数据处理。
image/png:
复制图片,一般是从外部进行复制粘贴;
当下的场景
首先我需要在一个类似PPT文档下实现一个复制粘贴的功能包括,可复制文本和图片并粘贴到我们的页面上,其次需要支持内部定义好的其他元素,最后需要支持跨标签页甚至是跨浏览器在我们的页面上保持一致性的复制粘贴交互;
并且由于JSON数据与html数据之间并不相通,例如在普通的富文本编辑器中,直接复制,基本都是直接拿到的html数据;而当前的场景下,因为使用了MVVM框架的原因,我们是将所有的dom转化成单个的model数据,因此你复制出来的数据需要做单独的处理,并不能直接粘贴到任何富文本上。
于是遇到了以下的问题:
1. 浏览器的剪切板安全限制
浏览器对于剪切板是有严格的安全限制的:不允许直接读取剪切板内容,除非使用提案中的navigator.clipboard.readText / navigator.clipboard.read进行权限的询问,用户主动通过后,可以直接读取;但是这是有风险的,首先,这个提案还是在draft的阶段,当然通过的几率很大,毕竟为了取代document.execCommand存在的,但是我们程序必须是向下兼容的。其次,倘若用户主动禁止了这个方法,那么后续的粘贴操作还是有问题。所以必须在现有的标准下操作才行;
Google Slides上实现:
- 主动询问用户是否安装插件,在插件上跳过这层安全限制;
- 不安装的情况下,在
safari点击粘贴你会发现又弹出来一个小按钮,这是因为safari有可以定制化菜单的能力;
2. 右键菜单定制化的窘境
而且实际上,在大多数的这种情景下,右键菜单也是定制化的。一般来说,我们可以直接调用右键菜单的进行符合浏览器行为的复制粘贴,但是,如果想要定制化菜单,当然可以监听contextMenu事件,然后主动阻止默认行为,例如腾讯文档或者Google Slides那样。但是有些浏览器的行为就会被隐藏甚至无法主动调用:例如复制粘贴。甚至有些web文档点击菜单上的粘贴按钮,直接弹出提示希望用户直接使用快捷键粘贴,这当然很反人类。
基于以上两点,是需要有自己的一套内存数据,在剪切板和右键菜单提供数据,然后在必要的时候主动更新clipboard,让系统的粘贴内存数据和内部的内存数据达成统一。
这里有一个技巧,就是可以使用document.execCommand('copy/cut')去主动更新clipboard里的数据。当你在右键点击复制的时候,倘若需要主动更新数据到剪切板上,可以主动调用,获取cut/copy事件抛出的clipboardData,然后使用该对象下的setData,对内外数据统一,在跨标签页上保持数据的流通很有作用。
private bindCopy = (e) => {
......
console.error('copy');
e.preventDefault();
this.duplicate.attemptToCopy(e, false);
};
// Duplicate类
/**
* 复制/剪切
* @param e ClipboardEvent
* @param isCut 是否为剪切
* 1. 主动快捷键复制粘贴
* 2. 右键菜单点击复制(不存在clipboardData对象)
* 3. 主动塞入自定义数据
*/
public attemptToCopy(e: ClipboardEvent | null, isCut = false) {
this.isCutCommand = isCut;
if (e && e?.clipboardData) {
const clipboardData = this.updateStash();
clipboardData && this.updateClipboard(e, clipboardData);
} else {
this.autoCopy();
}
}
/**
* 自动拷贝
* 1. 支持execCommand时,相当于复制后重新走一次addEventListener('copy')
* 这时候可以拿到e.clipboardData对象,可以执行上面的updateStash
* 好处:可以在copy里setData,设置标志位;缺点:execCommand有风险为被废除
* 2. 不支持时,使用writeText
* 好处:降级处理;缺点:无法设置特殊MIME,只能在getData('text/plain')里判断
*/
public autoCopy() {
if (!document.execCommand(this.isCutCommand ? "cut" : 'copy')) {
const clipboardData = this.updateStash();
clipboardData && navigator.clipboard.writeText(JSON.stringify(clipboardData));
}
}
当然,我这里做了一点兼容,毕竟document.execCommand方法是个废除的状态。当然使用navigator.clipboard.write也是可以的。
3. 定制化MIME类型之殇
我们通过clipboard也就是DataTransfer是可以直接我们的内部数据的,
比如我们给予一个特殊的标示类似 text/copy, 也就是我们自己定义MIME类型,那么下次我们就可以直接通过getData('text/copy')获取,感觉是不是很好?
这好比说标准的MIME类型是个硬通货,那么多年下来,所有地区(浏览器厂商和系统软件)都支持,并且也有自己的兑换方法(通用的MIME解析),而我们自己定义的MIME却是一个不知哪里冒出来的数字货币,肯定是不被市场认可的,只能在内部使用。同理:在一般情况下,这完全是可行的。但是毕竟这不是标准的MIME类型,无法实现跨浏览器获取。也就是说,某些极端场景是不行的。
那么为什么我们要自己设置MIME呢?首先通用的MIME除了text/plain之外,其余的类型都会主动添加该类型下所需的数据,例如text/html的话,会在首尾添加对应的xml格式数据,而其他的在前面也说过,会经过一次MIME解析,对于标准但特殊的MIME格式可能会有一些特殊添加数据或者解析操作。
其次,跨浏览器目前为止我只看到text/plain和text/html是可以传递数据的,其余的一律被过滤......但是如果直接设置text/plain是会造成,所有的复制内部数据都会暴露在外面的粘贴事件上,如果是普通的文本数据倒还好,如果是内部的保存的格式化数据,就会让用户感觉很奇怪。
那么初步是敲定使用一个特殊的MIME类型+一个text/html,可以做到对内部数据的解析。
想法很美好,然而这时候你会遇到另外一个问题:对于部分富文本编辑器,获取的基本都是text/html再去做一层解析,这时候你的数据就会暴露给别人了。对于这个,如果是复制给外部粘贴,那么不好意思,没有好的方法,因为你要保持数据的统一性和跨浏览器行为。如果是内部的编辑器就要去匹配,如果是内部数据,那么直接过滤掉。
当然还有可能会有一些特殊情况,例如外部复制一张svg图片,实际上,svg是xml格式的文本数据,小的svg图片当然还好,如果是大的图片,那么不保证浏览器不会卡死。那么这时候你可能需要text/plain顺带着做前置判断......
当然,如果不需要处理跨浏览器,那么并不需要那么麻烦,只需要保持一个自定义的MIME类型即可。
一般来说,我们获取剪切板内容判断,是会先从内部数据开始判断的,也就是自定义的MIME类型,然后是图片类型,最后才是纯文本类型;
import { SPEC_MIME } from "../util/variable";
class PasteHelper {
// 获取img数据
// 网上图片直接右键复制: [text/html, image/png]
// ppt/截图工具 [image.png]
// ppt文字:[text/plain,text/html,text/rtf,image/png]
// RTF: 微软下的跨文本格式
// https://zh.wikipedia.org/wiki/RTF
public getImgTransData(e: ClipboardEvent) {
if (!e.clipboardData?.items?.length) {
return false;
};
const transferDatas = Array.from(e.clipboardData.items);
const isText = transferDatas.find(c => c.type === 'text/rtf');
// 需要处理视频类的情况,返回img,但是getAsFile为null
if (!isText) {
const imgTransData = transferDatas.filter(c => c.kind === 'file' && c.type.indexOf('image') === 0)[0];
if (!imgTransData) {
return false;
} else {
const imgFile = imgTransData.getAsFile();
if (imgFile) {
return imgFile;
}
}
};
return false;
}
/**
* 判断是否为内部数据
* 降级SPEC_MIME -> htmlData(跨浏览器) -> plainText(execommand不可用,走writeText)
* @param e ClipboardEvent
*/
public getInnerData (e: ClipboardEvent) {
const innerData = e.clipboardData?.getData(SPEC_MIME);
......
}
// 获取纯文本,空白字符过滤
public getPlainText (e: ClipboardEvent) {
// 过滤特殊字符,给予空字符串
const reg = /[\0-\x08\x0B\f\x0E-\x1F\uFFFE\uFFFF]|[\uD800-\uDBFF](?![\uDC00-\uDFFF])|(?:[^\uD800-\uDBFF]|^)[\uDC00-\uDFFF]/;
let text = e.clipboardData?.getData('text/plain') || "";
text = text.replace(reg, " ");
return text ?? false;
}
}
export default new PasteHelper();
4. 地狱是平台兼容
一般来说,复制粘贴的话我们希望能跟word、ppt等本地应用交互一致。然而想象很丰满,现实很骨感。
在多个平台下,支持的程度不同,甚至实现起来,获取到的数据也完全不同。
下表是从外部来源复制,粘贴到内部的获取数据情况:
| 外部来源 | 文本 | 图片 | 文本框 | 音视频 | 网页(正常情况) | 支持 | 支持 | 转换为文本 | 不支持 | google slide | 支持 | 不支持 | 转换为文本 | 不支持 | 腾讯文档 | 支持 | 不支持 | 转换为文本 | 不支持 | office ppt(web) | 支持 | 不支持 | 不支持 | 不支持 | 金山文档(web) | 支持 | 不支持 | 不支持 | 不支持 | office (ppt/excel) | 支持 | 支持 | 转换为文本 | 转换成图片 | wps | 支持 | 不支持 | 不支持 | 不支持 | keynote | 支持 | 支持 | 转换为文本 | 转换成图片 | numbers | 支持 | 支持 | 转换为文本 | 不支持 | windows(系统) | 支持 | 不支持 | - | 不支持 | uos(系统) | 支持 | 转换成文本 | - | 转换为文本 | mac(系统) | 支持 | 支持 | - | 转换为文本 |
|---|
Google Slides 、腾讯文档等web应用不支持复制图片,需要单独解析text/html数据里的图片,也就是需要做字符串解析,实际上是可以做到;
金山文档、office等web应用不支持文本框和文本的原因是,这些应用使用了内部协议,我们一般不针对特殊协议(MIME)做处理;windows系统不支持图片和音视频复制粘贴,经测试,在该系统下只能拿到纯文本;
像这种情况,你只能抱住产品爸爸的大腿,然后说:臣妾做不到......
5. 媒体文件的处理之阿克琉斯之踵
基于内部数据的信任,一开始你或许只想着复制数据,序列化之后塞到我们定制好的MIME类型里面,下一次再拿出来反序列化就好了。
然而,一开始我们的产品对多媒体的文件(音视频、图片)做了特殊处理:在一上传到我们页面的时候单纯转成blob,保存在内存里,等下一次同步的时候再去做一次上传到云端的处理。这种做法一定程度上可以提高用户的体验,毕竟不需要一上传就必须要经过一次上传云端的操作。
但是在这里就有一个弊端了:跨标签页的时候,如果上一个的标签页关闭,那么势必blob链接会失效,因为blob的内存或者说引用地址是保存在上一个标签页的,但是如果这时候去改动的话,影响范围会变得比较广。
这时候,只能采取降级方案:已经上传到云端上的,直接获取链接地址;还未上传的,是blob链接的只能先复制blob地址,在新的标签页,先通过fetch下载到当前页面,然后就可以跟普通文件一样处理了。当然这会有两个问题:
一、在复制完后,立刻关闭当前页面,那么blob内存会被释放,也是无法在下载的,考虑到这种情况的话那就只能复制的时候直接上到云端,或者在空闲时间,静默上传;二、在跨浏览器上,无能为力,也只能是云端链接格式才行。Google slides就是blob在转url的做法,而腾讯文档就是直接上传,语雀则是先用一张base64展示在上传。
当然或许有人会说,可以先将文件转成base64的格式,但是我们复制一般可能会有多个媒体文件,这时候base64就会耗费时间生成,而且数据量可能会超过剪切板内存大小。毕竟找不到可以在浏览器间传递二进制文件的方法,只能先采用这种恶心的方法。
if (isBlobUrl(model.source)) {
if (medias[model.hash]) {
model.source = medias[model.hash];
} else {
let blob;
if (blob = await url2blob(model.source)) {
// 根据blobUrl重新创建当前页面的blob
const file = await blob2File(blob, model.mediaName || model.pictureName);
const blobUrl = await file2BlobUrl(file);
model.source = blobUrl;
// 缓存media数据
this.storageData.update({
medias: {
[model.hash]: blobUrl
}
});
} else {
console.error('不支持的blob_URL或者跨域');
return null;
}
}
}
直接使用一个DataTransfer对象,然后往里面塞数据,经测试也是不行的。
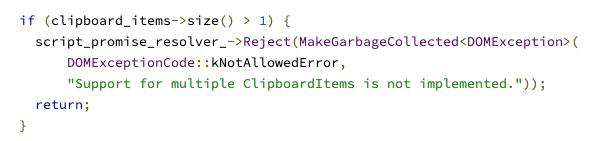
当然,倘若你了解clipboardItems,你可能会觉得clipboardItems可以往剪切板里塞数据。
是的,完全可以,不过clipboardItems看起来像个数组,用起来也是个数组,就是数据是只支持长度为1的数组.
6. 图片的黑洞
事实上,我完全没想过图片居然还需要这种异常的处理。在复制粘贴图片的过程中,你可能不会想到,你复制一个“瘦子”,最后给你一个完全认不出来的“胖子”;
在浏览器里,我们通过image/png拿到的永远是单一的图片格式,因为浏览器为了支持、兼容图片格式,都会将图片转成bitmap给你,这样一来你在image/png里拿到的只是bitmap的blob格式,这会产生两个问题:
- 你无法获取图片原来的格式,永远只能拿到
png,也就无法进行格式判断; bitmap在不同平台下的转换不同,这会造成图片有可能会增大体积,例如一张20m的图片,通过getAsFile方法获取到的,可能超过30m......在mac和window下测试可能会得到两个不同的结果。
果然还是要通过input才能完整的获得浏览器的文件能力。
具体可参考:
lists.whatwg.org/pipermail/w…
结尾
当然,还有一些其他的问题存在,例如复制粘贴外部的表格实际上需要单独做一层解析,这个过程会更加麻烦;序列化和反序列化的数据需要慎重考虑,因为有些数据在格式化后会有转变的风险......
但是基本上整个复制粘贴的过程就是这样
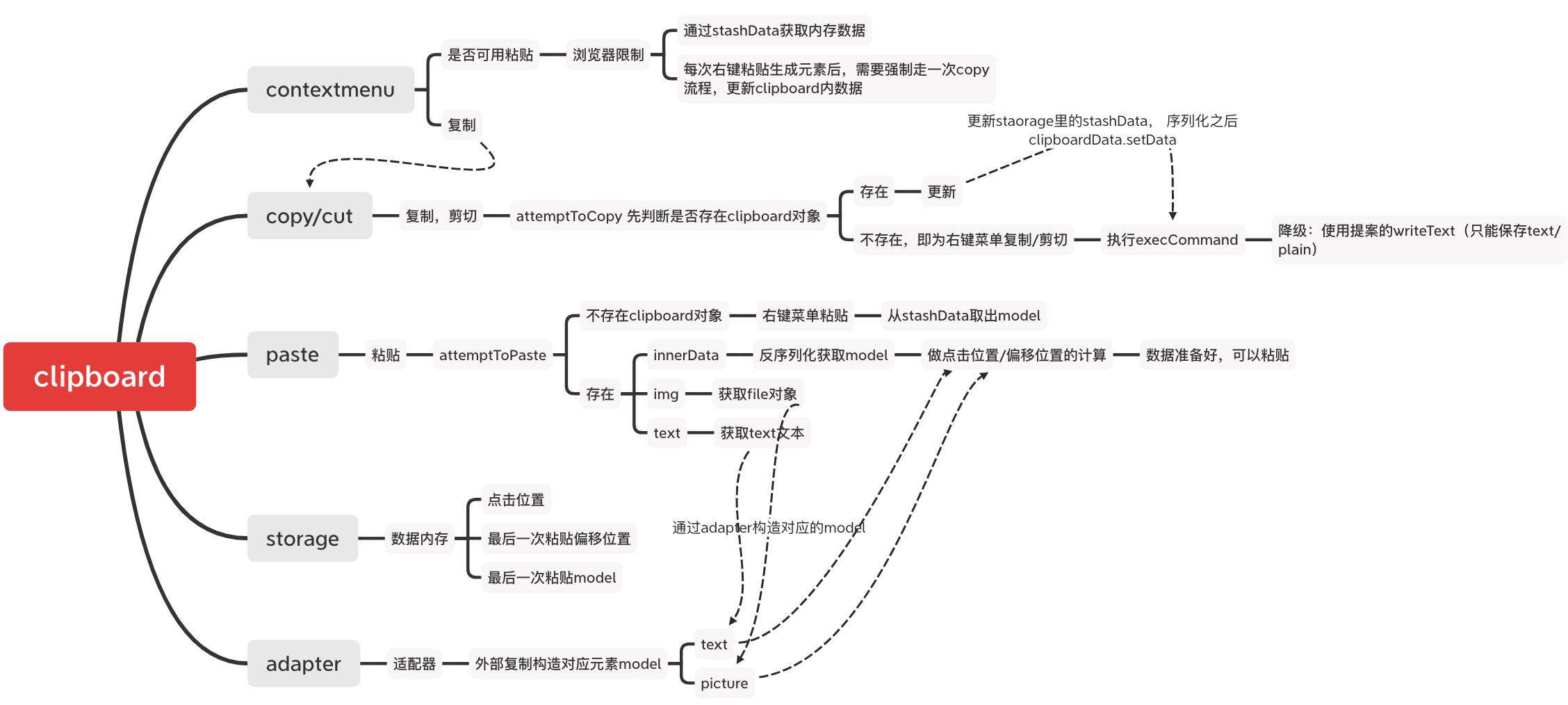
事实上,整个的复制粘贴并无法做到完美,在浏览器的各种限制下,会有很多无法保持一致性的问题存在,只能在夹缝中生存。倘若原来需要复制粘贴的内容是符合html规范的,那么处理起来就会很简单;若是跟我遇到的场景一样,数据基本都为JSON,那么势必需要花大精力去处理数据之间的转换和处理一些边界问题。
参考文章
- www.alloyteam.com/2015/04/how…
常见问题FAQ
- 免费下载或者VIP会员专享资源能否直接商用?
- 本站所有资源版权均属于原作者所有,这里所提供资源均只能用于参考学习用,请勿直接商用。若由于商用引起版权纠纷,一切责任均由使用者承担。更多说明请参考 VIP介绍。
- 提示下载完但解压或打开不了?
- 找不到素材资源介绍文章里的示例图片?
- 模板不会安装或需要功能定制以及二次开发?



发表评论
还没有评论,快来抢沙发吧!