之前写过一篇类似的文章( 非科班前端注意了! 计算机组成原理知识已送到你嘴边! ),但是已经是1年前的事了,今年我觉得自己又成长了很多,再次总结一次,其内容丰富程度远超上篇文章!废话不多说!上车吧!

前言 - 计算机基础到底有多重要
就拿我们马上要讲的计算机组成原理来说,我们马上的迭代任务,有一个同学的任务是写类似javascript计算器,并且带有很多特定业务的公式计算任务,其实这个任务有很多细节问题,需要懂javascript的数字基本原理才行,比如说:javascript使用的 IEEE 754标准的64位浮点数,那么64位浮点数天生就会有一些问题出来:
- 64位浮点数的支持的最大整数是多少?这个需要跟产品说清楚,为啥你支持不了更大的整数运算,其实也就是javascript支持的最大整数,是2的53次方减一,为啥呢?不学计算机组成原理是理解不了的
- JavaScript中常被诟病的
0.3 - 0.2 == 0.1原因是什么?这个需要跟产品说清楚,精度问题怎么处理, 不了解小数在浮点数中的表示和如何转化10进制是不理解的 - JavaScript的数字小数位有多少位,为什么是这么多位,也要跟产品说清楚
计算机的简略发展史
大家别小看这个发展史,对我们来说也很重要,比如后面讲到I/O设备,其实I/O设备的演进就是计算机发展史的一个缩影,对我们理解I/O设备的演进是很有帮助的,你是在一个大的框架下理解一些更细节的概念。
电子管时代
- 当时的背景:为了军方的计算要求,比如弹道轨迹计算,人们的需要一个能代替人脑的计算装置。
- 具体的产出:第一台电子数字计算机:ENIAC(1946)当时就这这个背景下产生
-
大概是如何进行计算的呢?当时的计算机会有很多逻辑处理元件,它们在高低电压(可以表示01的二进制)下用线路连接起来实现计算的功能。
-
当时的主要逻辑元件是电子管,电子管有我们半个手掌那么大,同时也意味着这个机器的体积是很大的,电子管耗电,计算机的耗电量也很高,而且此时的计算机只能识别0101的二进制数,所以只能用机器语言来编程,此时程序员编程是在一个纸袋上的,如下图,有孔代表0,没孔代表1
-

- 产生的问题:耗电量高,体积大,并且启动和关闭时常常会有逻辑元件损坏,稳定性极差
晶体管时代
如下图:最右边的是电子管,挨着的是晶体管和集成电路,我们可以看到晶体管比电子管小很多

- 当时的背景:希望计算机体积、耗电量、计算能力等方面比上个时代更出色
- 具体的产出:晶体管的电气特性可以替代电子管,而且晶体管的体积比电子管小很多,这也意味着此时的计算机要小很多
- 并且出现了面向过程的程序设计语言和操作系统的雏形,制造一台计算机大概需要几万到几十万的晶体管,并且需要用手工的方式把晶体管焊接到电路板上,就非常容易出错
中小规模集成电路时代
- 具体的产出:集成电路的技术让我们计算机变得越来越小,同时功耗更低,可靠性也比手动焊接的晶体管更高,此时的计算机主要用于科学计算,一些高级语言同时产生,并出现分时操作系统
超大规模集成电路时代
- 随着集成电路工艺的不断提升,出现了大规模和超大规模集成电路,此时开始出现微处理和微型计算机,也就是我们现在家用的计算机,就拿苹果的A13处理器来说,每一个逻辑元件在其中不超过7纳米,一个指甲盖大小的cpu就集成了85亿个晶体管。

计算机硬件的基本组成
冯诺依曼体系
-
因为早期的计算机比如ENIAC,每一步的计算,需要执行的指令都需要程序员手动去操作,也就是手工就浪费了大量的时间
-
为了解决这个问题,冯诺依曼就提出了
存储程序的概念,就是指,将指令以二进制代码的形式事先输入到计算机的内存里,然后内存根据里面存储的指令从首地址也就是第一条指令开始按顺序一条一条的执行,直到程序执行结束,这种自动执行的机制比人工操作使计算机的计算效率大大提升 -
冯诺依曼体系是以运算器为核心的,我们现代的计算机是以存储器为核心,我们这里了解冯诺依曼体系如何以运算器为核心的价值不大,所以就直接介绍以存储器为核心的现代计算机涉及的部件吧
首先,计算机最基本的5大组成部分如下图,分别为:输入设备(比如键盘), 存储器(比如内存), 运算器(cpu), 控制器(cpu), 输出设备(显示器),我们看一下这些基本的硬件设备是如何处理数据的
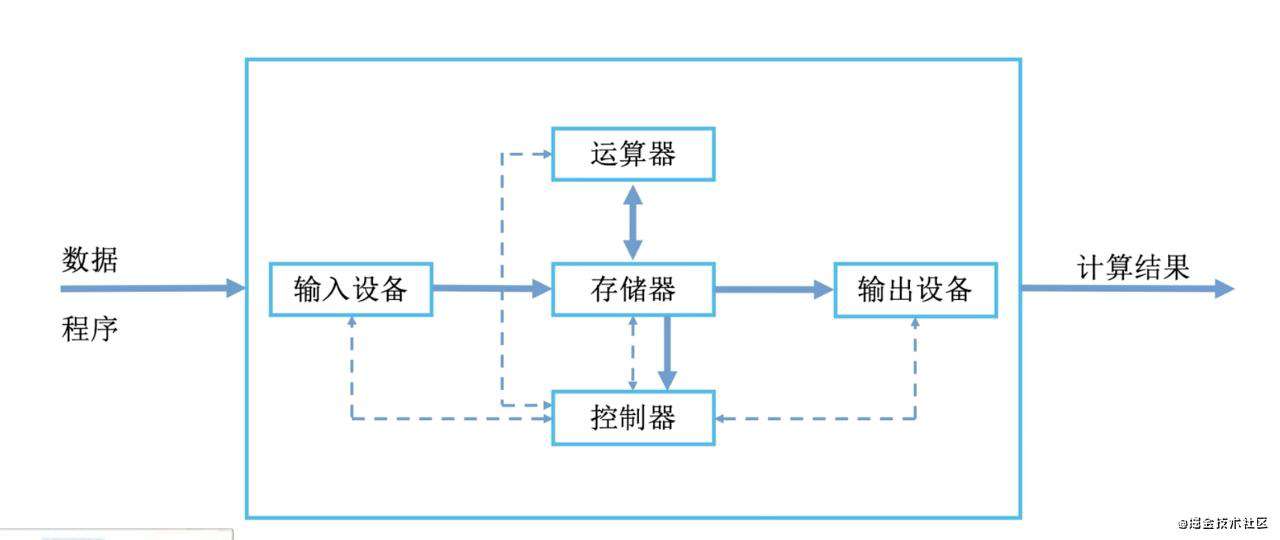
上图的实线是数据线,是数据交换的通路,虚线是控制线和反馈线,是传递命令的通路
-
首先我们的数据通过输入设备会被加工程计算机能够识别的
0101的形式,我们直接输入的代码计算机是不认识的。 -
然后经过输入设备处理的数据,先存到了
存储器里(控制器控制输入设备),存储器可以存放数据和程序指令 -
然后
控制器可以直接从存储器里取得所需要执行的程序指令,取得指令后,控制器会分析指令要做什么(指令分为操作码和地址码),分析的就是操作码,到底要干嘛 -
假设分析出来是
读取数据的操作,也就是从存储器中取一个数据给运算器,那么读取数据的地址就在写在地址码里面,这时运算器就去就告诉存储器要取数据的地址,然后存储器直接把数据传递给运算器 -
最后运算结束,运算结果会返回存储器,存储器可以直接把结果返回给
输出设备(在控制器的控制下) -
最后输出设备,比如
显示器上就看到我们想要的数据
接下来又是干巴巴的文字,太枯燥了,休息5分钟,我们先吃个鸡腿,继续吧!

上面是基本的计算机运算的过程,我们拿一个实际的javascript代码来举例:
假设在我们的JS代码里,运行代码 let a = 1 + 1,此时上述的5大计算机部件如何处理的呢?
`
-
首先键盘输入代码
let a = 1 + 1将被解析为2进制代码,在控制器的控制下放入了内存 -
然后内存存储完毕,
CPU的控制器开始从内存里取出指令,分析出指令是一个加法操作(先让 1+1运算,后面才会把1+1运算的结果赋值给变量a) -
然后控制器控制运算器,运算器直接从内存里取出数据两个1,做一个加法运算得出结果,并返回给存储器,存储到一个内存的地址里
-
然后控制器接着执行第二条指令(let a = 2),因为之前2已经被算出来了,第二条指令是赋值操作了(把
1+1的值赋给变量a,a其实就是一个内存地址而已) -
此时CPU的控制将控制CPU的运算器做
1+1的加法运算,并得出结果2 -
最后执行指令完毕,如果我们要打印console.log(a)的话,a因为本质上是一个内存地址,cpu会根据内存地址,找到这个地址里存放的值,也就是console.log显示的值
-
获取到要显示的值后,存储器直接将数据传给显示器,这样我们就可以在屏幕上看到2这个结果了
计算机编程语言
通过下图,我们简单介绍一下类似javascript、Python这种解释型语言和c, c++这种编译型语言的区别。理解为什么解释性语言通常都比编译型语言运算速度慢。
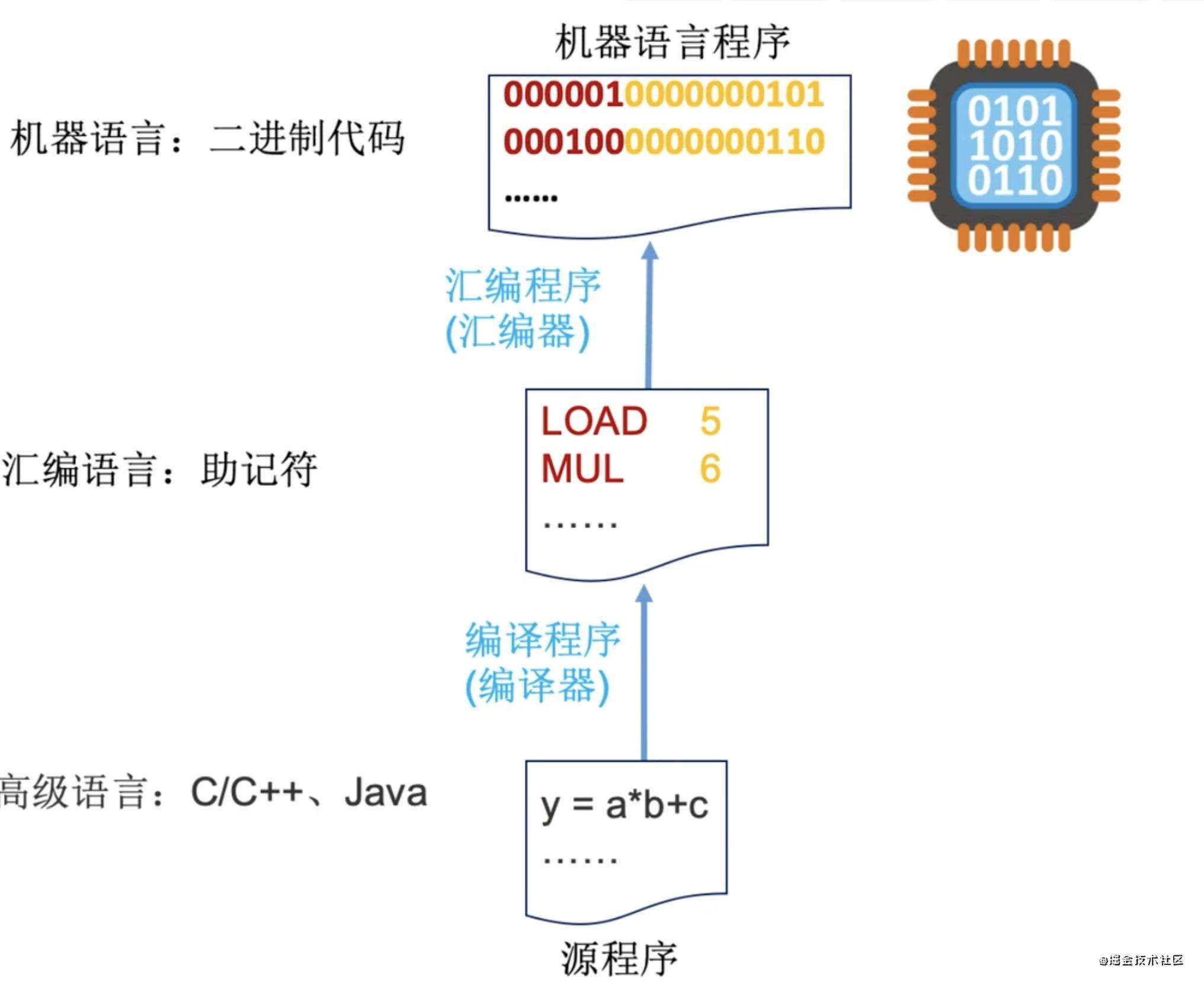
高级语言一般有两种方式转换为机器语言
- 一种是直接借助
编译器,将高级语言转换为二进制代码,比如c,这样c运行起来就特别快,因为编译后是机器语言,直接就能在系统上跑,如上图,但问题是,编译的速度可能会比较慢。 - 一种是解释性的,比如
js,是将代码翻译一行成机器语言(中间可能会先翻译为汇编代码或者字节码),解释一行,执行一行
需要注意的是,按照第一种将大量的高级代码翻译为机器语言,这其中就有很大的空间给编译器做代码优化,解释性语言就很难做这种优化,但是在v8引擎中,js还是要被优化的,在编译阶段(代码分编译和执行两个阶段)会对代码做一些优化,编译后立即执行的方式通常被称为 JIT (Just In Time) Comipler
进位计数制(重点)
这章主要介绍进制转换,比如10进制转2进制怎么转,2进制转10进制怎么转。
掌握这些事必要的,比如leetcode有一道简单题叫excel序号,本质就是26进制转10进制,不了解进制转换就不容易做出来这道题。
任意进制如何转化为十进制
例如2进制101.1如何转化为10进制。(有些同学觉得可以用parseInt('101.1', 2),这个是不行的,因为parseInt返回整数)
转化方法如下(按权相加法): 2进制的 101.1 = 1 x 22 + 0 x 21 + 1 x 20 + 1 x 2-1
规律就是二进制的每个数去乘以2的相应次方,注意小数点后是乘以它的负相应次方。

到这里我出一个思考题,unicode码,第一个平面的也就是能包含字符范围是 0000 - FFFF(16进制),请问16进制的FFFF是10进制的多少?
十进制整数转为任意进制
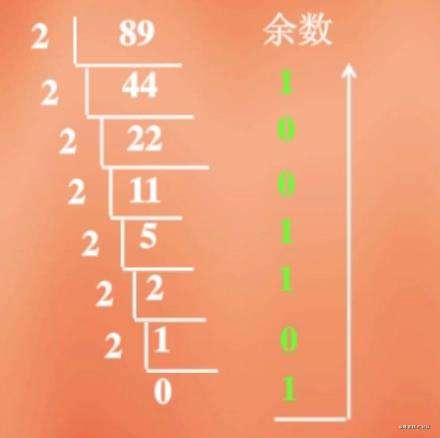
方法是除商取余法:比如10进制转2进制
例如: 把89化为二进制的数
把89化为二进制的数
89÷2=44 余1
44÷2=22 余0
22÷2=11 余0
11÷2=5 余1
5÷2=2 余1
2÷2=1 余0
1÷2=0 余1
然后把余数由下往上排序
1011001
这样就把89化为二进制的数了
十进制小数转为n进制
我们还是以2进制为例,方式是采用“乘2取整,顺序排列”法。具体做法是:
- 用2乘十进制小数,可以得到积,将积的整数部分取出-
- 再用2乘余下的小数部分,又得到一个积,再将积的整数部分取出-
- 如此进行,直到积中的小数部分为零,或者达到所要求的精度为止
所以n进制是一个道理
我们具体举一个例子
如: 十进制 0.25 转为二进制
0.25 * 2 = 0.5取出整数部分:00.5 * 2 = 1.0取出整数部分1
即十进制0.25的二进制为 0.01 ( 第一次所得到为最高位,最后一次得到为最低位)
此时我们可以试试十进制0.1和0.2如何转为二进制,就知道为啥0.1 + 0.2不等于0.3了
0.1(十进制) = 0.0001100110011001(二进制)
十进制数0.1转二进制计算过程:
0.1*2=0.2……0——整数部分为“0”。整数部分“0”清零后为“0”,用“0.2”接着计算。
0.2*2=0.4……0——整数部分为“0”。整数部分“0”清零后为“0”,用“0.4”接着计算。
0.4*2=0.8……0——整数部分为“0”。整数部分“0”清零后为“0”,用“0.8”接着计算。
0.8*2=1.6……1——整数部分为“1”。整数部分“1”清零后为“0”,用“0.6”接着计算。
0.6*2=1.2……1——整数部分为“1”。整数部分“1”清零后为“0”,用“0.2”接着计算。
0.2*2=0.4……0——整数部分为“0”。整数部分“0”清零后为“0”,用“0.4”接着计算。
0.4*2=0.8……0——整数部分为“0”。整数部分“0”清零后为“0”,用“0.8”接着计算。
0.8*2=1.6……1——整数部分为“1”。整数部分“1”清零后为“0”,用“0.6”接着计算。
0.6*2=1.2……1——整数部分为“1”。整数部分“1”清零后为“0”,用“0.2”接着计算。
0.2*2=0.4……0——整数部分为“0”。整数部分“0”清零后为“0”,用“0.4”接着计算。
0.4*2=0.8……0——整数部分为“0”。整数部分“0”清零后为“0”,用“0.2”接着计算。
0.8*2=1.6……1——整数部分为“1”。整数部分“1”清零后为“0”,用“0.2”接着计算。
……
……
所以,得到的整数依次是:“0”,“0”,“0”,“1”,“1”,“0”,“0”,“1”,“1”,“0”,“0”,“1”……。
由此,大家肯定能看出来,整数部分出现了无限循环。
接下来看0.2
0.2化二进制是
0.2*2=0.4,整数位为0
0.4*2=0.8,整数位为0
0.8*2=1.6,整数位为1,去掉整数位得0.6
0.6*2=1.2,整数位为1,去掉整数位得0.2
0.2*2=0.4,整数位为0
0.4*2=0.8.整数位为0
就这样推下去!小数*2整,一直下去就行
这个数整不断
0.0011001
所以0.1和0.2都无法完美转化为二进制,所以它们相加当然不是0.3了
真值和机器数
例如:
+15 => 01111(2进制)
-8 => 11000(2进制)
真值是我们平时生活中用到的数字形式,比如+15,-8,机器数是存到机器里的形式,也就是2进制的形式,其中01111,第一个0是代表正数的意思,1111是保存的数值,转换成10进制就是15
所以合起来就是+15
字符编码
字节
- 计算机内部,所有信息最终都是一个二进制值
- 每一个二进制位(bit)有0和1两种状态,因此八个二进制位就可以组合出256种状态,这被称为一个字节(byte)
单位
- 8位 = 1字节
- 1024字节 = 1K
- 1024K = 1M
- 1024M = 1G
- 1024G = 1T
JavaScript中的进制
进制表示
let a = 0b10100;//二进制
let b = 0o24;//八进制
let c = 20;//十进制
let d = 0x14;//十六进制
console.log(a == b);
console.log(b == c);
console.log(c == d);
进制转换
-
10进制转任意进制 10进制数.toString(目标进制)
console.log(c.toString(2)); 复制代码 -
任意进制转十进制 parseInt('任意进制字符串', 原始进制),小数部分会被截断;
console.log(parseInt('10100', 2)); 复制代码
ASCII
最开始计算机只在美国用,八位的字节可以组合出256种不同状态。0-32种状态规定了特殊用途,一旦终端、打印机遇上约定好的这些字节被传过来时,就要做一些约定的动作,如:
- 遇上0×10, 终端就换行;
- 遇上0×07, 终端就向人们嘟嘟叫;
又把所有的空格、标点符号、数字、大小写字母分别用连续的字节状态表示,一直编到了第 127 号,这样计算机就可以用不同字节来存储英语的文字了
这128个符号(包括32个不能打印出来的控制符号),只占用了一个字节的后面7位,最前面的一位统一规定为0
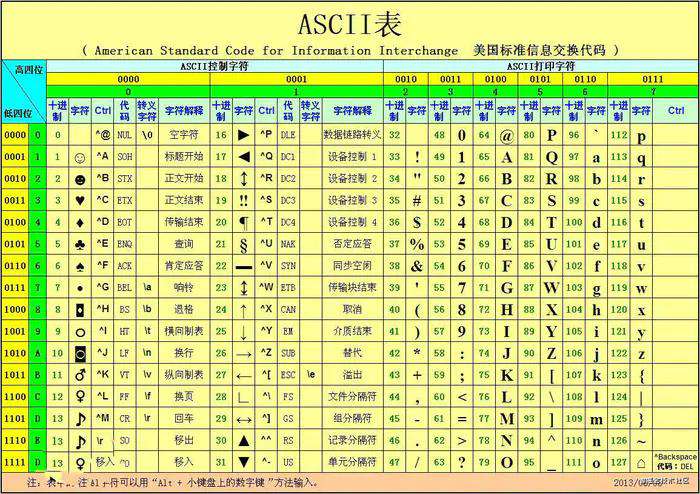
这个方案叫做 ASCII 编码
GB2312
后来西欧一些国家用的不是英文,它们的字母在ASCII里没有为了可以保存他们的文字,他们使用127号这后的空位来保存新的字母,一直编到了最后一位255。比如法语中的é的编码为130。当然了不同国家表示的符号也不一样,比如,130在法语编码中代表了é,在希伯来语编码中却代表了字母Gimel (ג)。
中国为了表示汉字,把127号之后的符号取消了,规定
- 一个小于127的字符的意义与原来相同,但两个大于 127 的字符连在一起时,就表示一个汉字;
- 前面的一个字节(他称之为高字节)从
0xA1用到0xF7,后面一个字节(低字节)从0xA1到0xFE; - 这样我们就可以组合出大约7000多个(247-161)*(254-161)=(7998)简体汉字了。
- 还把数学符号、日文假名和ASCII里原来就有的数字、标点和字母都重新编成两个字长的编码。这就是全角字符,127以下那些就叫半角字符。
- 把这种汉字方案叫做 GB2312。GB2312 是对 ASCII 的中文扩展
GBK
后来还是不够用,于是干脆不再要求低字节一定是 127 号之后的内码,只要第一个字节是大于 127 就固定表示这是一个汉字的开始,又增加了近 20000 个新的汉字(包括繁体字)和符号。
各个国家都像中国这样搞出一套自己的编码标准,结果互相之间谁也不懂谁的编码,谁也不支持别人的编码
Unicode
ISO 的国际组织废了所有的地区性编码方案,重新搞一个包括了地球上所有文化、所有字母和符 的编码! Unicode 当然是一个很大的集合,现在的规模可以容纳100多万个符号。
- International Organization for Standardization:国际标准化组织。
- Universal Multiple-Octet Coded Character Set,简称 UCS,俗称 Unicode
ISO 就直接规定必须用两个字节,也就是 16 位来统一表示所有的字符,对于 ASCII 里的那些 半角字符,Unicode 保持其原编码不变,只是将其长度由原来的 8 位扩展为16 位,而其他文化和语言的字符则全部重新统一编码。
从 Unicode 开始,无论是半角的英文字母,还是全角的汉字,它们都是统一的一个字符!同时,也都是统一的 两个字节
- 字节是一个8位的物理存贮单元,
- 而字符则是一个文化相关的符号。
平面(Plane)
Unicode 使用的数字是从 0 到 0x10ffff,这些数字都对有相对应的字符(当然,有的还没有编好,有的用作私人自定义)。每一个数字,就是一个代码点(Code Point)。
这些代码点,分为 17 个平面(Plane)。其实就是17 组,只是名字高大上而已
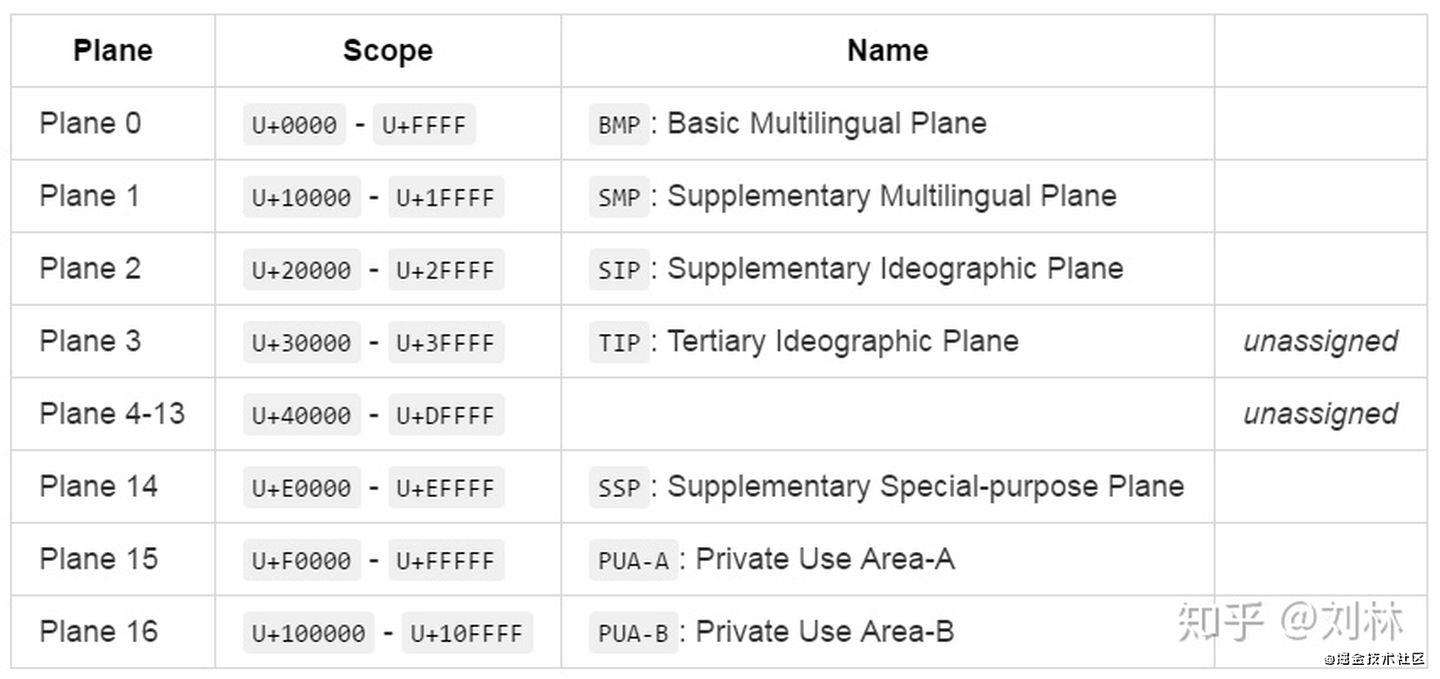
Plane 3 到 Plane 14 还没有使用,TIP(Plane 3) 准备用来映射甲骨文、金文、小篆等表意文字。PUA-A, PUA-B 为私人使用区,是用来给大家自己玩儿的——存储自定义的一些字符。
Plane 0,习惯上称作基本平面(Basic Plane);剩余的称作扩展平面(Supplementary Plane)。
utf 32
UTF-32 使用四个字节来表示存储代码点:把代码点转换为 32 位二进制,位数不够的左边充 0。
4个字节就是4 * 8 = 32位,就能表示2的32次方个数字,这些数字可以对应2的32次方个字符,但其实我们常用的是 0 - 2的16次方的字符,可以看到utf32编码特别浪费空间
utf 16
UTF-16 用二个字节来表示基本平面,用四个字节来表示扩展平面。也就是说,UTF-16的编码长度要么是2个字节(U+0000到U+FFFF),要么是4个字节(U+010000到U+10FFFF)
UTF-8
UTF-8是一种变长的编码方法,字符长度从1个字节到4个字节不等。 越是常用的字符,字节越短,最前面的128个字符,只使用1个字节表示,与ASCII码完全相同。
| 编号范围 | 字节 | 0x0000 - 0x007F | 1 | 0x0080 - 0x07FF | 2 | 0x0800 - 0xFFFF | 3 | 0x010000 - 0x10FFFF | 4 |
|---|
中文在unicode里面的范围
| 4E00~9FA5 | 中日韩统一表意文字 | 2E80-A4CF | 中日朝部首补充、康熙部首、表意文字描述符、中日朝符号和标点、日文平假名、 日文片假名、注音字母、谚文兼容字母、象形字注释标志、注音字母扩展、 中日朝笔画、日文片假名语音扩展、带圈中日朝字母和月份、中日朝兼容、 中日朝统一表意文字扩展A、易经六十四卦符号、 中日韩统一表意文字、彝文音节、彝文字根 | F900-FAFF | 中日朝兼容表意文字 | FE30-FE4F | 中日朝兼容形式 | FF00-FFEF | 全角ASCII、全角中英文标点、半宽片假名、半宽平假名、半宽韩文字母 |
|---|
一般用4E00-9FA5已经可以,如果要更广,则用2E80-A4CF || F900-FAFF || FE30-FE4F
看到了吧,4E00-9FA5 就是一般正则表达式匹配中文的范围。为什么来的,这下知道原理了吧
在javascript中,如何转utf8呢?
可以使用encodeURIComponent
encodeURIComponent('张')
"%E5%BC%A0"
而且,平时我们说中文是两个字节表示的,这个是错误的,几个字节表示完全是看编码,比如utf8和utf16有可能同样的unicode码,编码出来的字节数是不一样的。
我们平时的页面都是utf8编码的,其实在底层2进制上,中文通常是3个字节表示的。
JavaScript 如何在内部使用 Unicode
虽然 JavaScript 源文件可以有任何类型的编码,但 JavaScript 会在执行之前在内部将其转换为 UTF-16。
JavaScript 字符串都是 UTF-16 序列,正如 ECMAScript 标准所说:
定点数(重点)
定点数和浮点数

无符号数
就是整个机器字长(机器字长是指计算机进行一次整数运算所能处理的二进制数据的位数,比如我们常说32位机器,64位机器)的全部二进制位均为数值位,没有符号位,相当于都是正数。
比如8位无符号整数的范围就是 二进制: 00000000 - 11111111
转化为10进制就是0 - 255
注意我们说的无符号数都是针对整数,没有小数
有符号数的定点表示
先来看看定点整数和定点小数如何在计算机里表示。
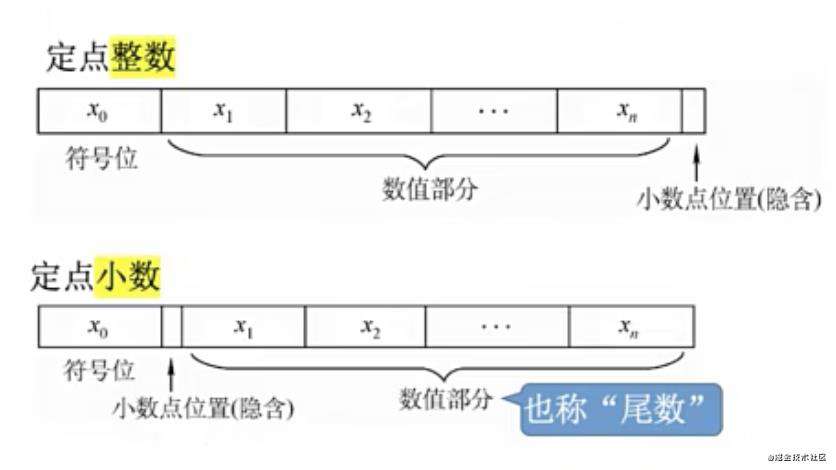
- 定点整数:符号位在第一位,通常0表示正数,1表示负数,小数点默认在最后一位,是隐藏的
- 定点小数:符号位在第一位,通常0表示正数,1表示负数,小数点隐藏在符号位后面,小数的数值部分也可以叫尾数,这个我们在浮点数介绍的时候会出现这个名词(数值部分 = 尾数)
定点数整数和小数都可以用原码,反码,补码表示,整数还可以用移码表示,具体什么意思我们稍后介绍。
原码
原码就是用尾数表示真值的绝对值,符号位0表示正数,1表示负数,假设我们机器字长为8位
我们拿 +19和 -19来解释一下
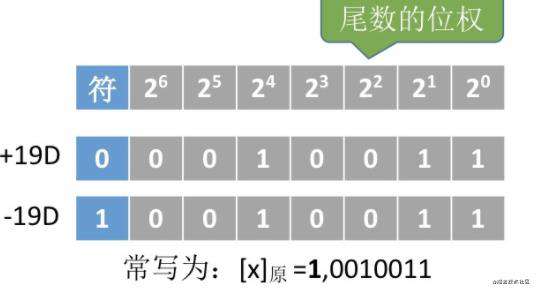
+19表示为:0,0010011 -19表示为: 1,0010011
下面是定点小数的表示,同理

反码
若符号位为0,则反码和原码一致
若符号位为1,则数值位全部取反
补码
补码分为:
正数的补码 = 原码
负数的补码 = 反码末尾 + 1
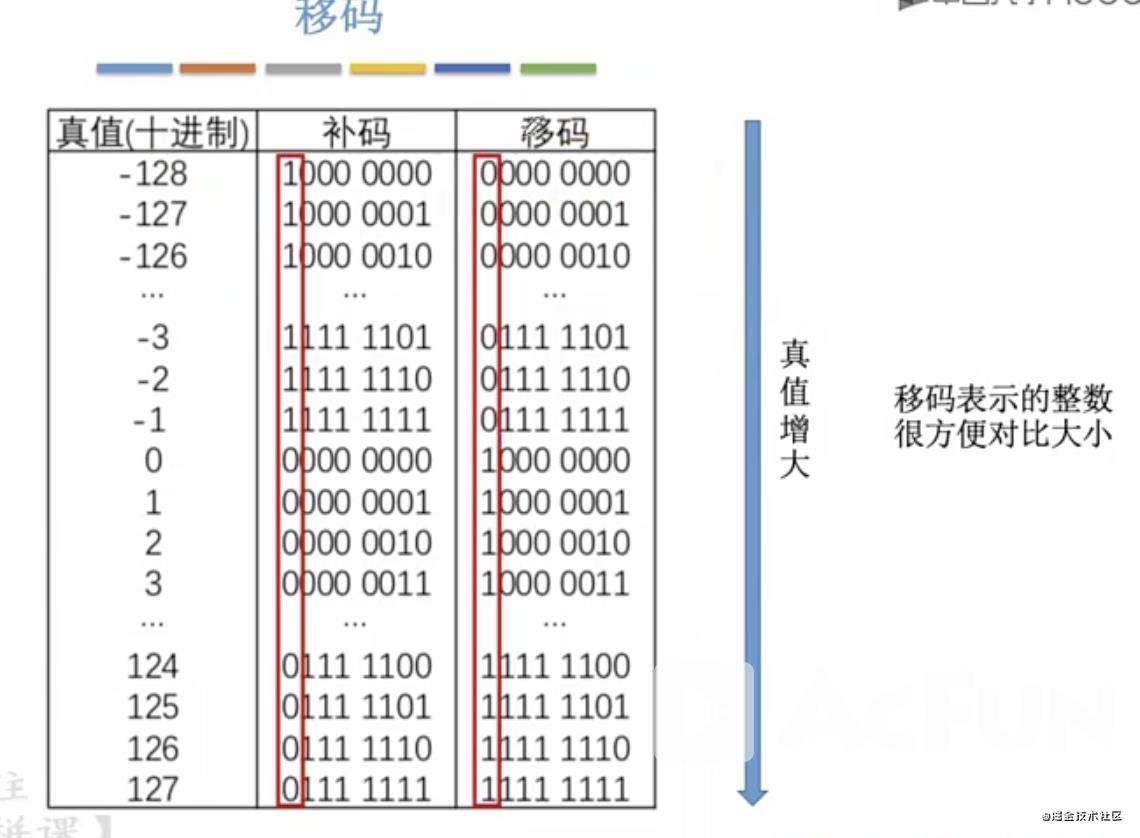
移码
补码的基础上符号位取反,只能表示整数。为什么需要移码,移码可以非常方便的判断两个数的大小。如下图:
我们会发现移码从左往右,只要先有1就更大,如果都有1,就往后面比,先出来1的就更大
为什么需要这些什么补码移码
为什么原码有问题呢,比如我们做一个运算 14 + (-14)
按道理应该等于0,但是我们把它们转为2进制,定点数的加法就出现问题了,居然不等于0,如下图
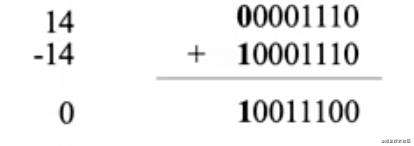
那该怎么办呢,原码的加法需要变为减法也就是14-14,这样就对了,但是这意味我们的计算机既要设计一个加法器又要设计一个减法器,减法器的复杂度是很高的,为了方便运算,一些聪明的人实现了让加法代替减法,这就需要我们之前讲的补码知识了。
14 + (-14)怎么才能计算正确呢?
我们可以让14的原码 加上 -14的补码,这时候就是
00001110 + 11110010(这个是-14的补码) = 100000000,因为机器字长是8位,也就是最多容纳8位2进制,最左边的1会被机器天然丢弃,这样最终结果就是00000000.
浮点数
为什么需要浮点数,主要是定点数对于很大的数字是特别浪费空间的,举个例子,比如说浮点数1.2 x 10的20次方,我们知道是10进制,就只需要存1.2和20这些数据就能表示这个数,但是定点数一个数字占一个坑,肯定没有浮点数在更小的空间表示更大的数。
我们举一个例子来理解浮点数的表示,比如数字+302657264526,这是定点整数的表示方法,如果是科学计数法,我们表示为:+3.026 * 1011 ,而其中的10是不是固定不变的呢,所以如果要保存这个科学技术法表示的数字,我们可以不看10这个基数,只需要保存+11 和 +3.026就能推出这个数字的科学技术法,从而得到这个数字
我们可以给+11 和 +3.026取两个名字,在浮点数里分别叫阶码和尾数,如下图
注意阶码分为了阶符和阶码的数值部分,尾数分为数符合尾数的数值部分。
阶符是正表示小数点往后移,为负表示小数点往前移动。阶码表示小数点移动多少位。
数符表示数值的正负性,尾数表示数字精度。
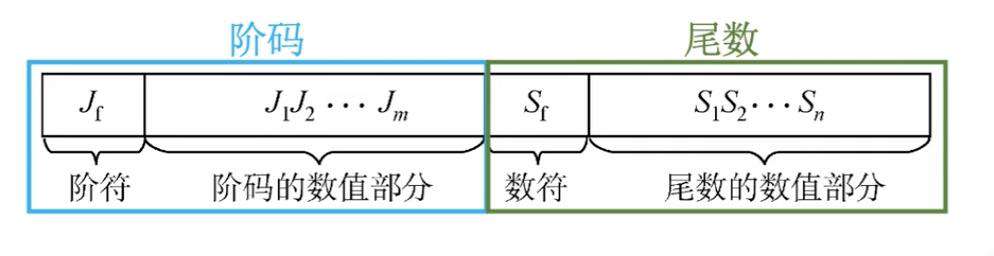
其中, 阶码反映数值的大小,尾数反应数值的精度,为什么这么说呢,比如之前举的例子中,+11表示小数点要右移多少位,是不是越大,移动的位数越多,数字就越大呢,对于尾数,比如+3.0265748是不是同样右移5位比+3.026表示的数字更精确呢
在二进制表示的计算机内,阶码常用补码或者移码表示的定点整数,尾数常用原码或者补码表示的定点小数。
浮点数的表示为 N = rE * M , r相当于底数,是2(跟10进制科学计数法是10意思是一样的),E代表阶码,M代表尾数。
IEEE 754标准的双精度浮点数
常见的IEEE 754标准分为单精度浮点数float和双精度浮点数double,我们可以看一下它的区别(阶码也可以称为指数)
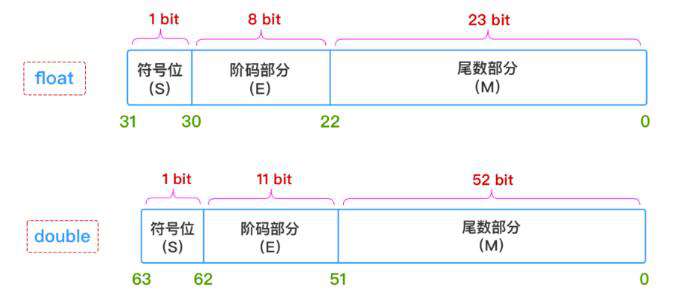
因为javascript的数字就是双精度浮点数,所以我们只介绍这一种。在双精度浮点数的尾数是52位,其实是可以表示53位,为什么呢,我们知道科学计数法,但二进制只能表示0和1,0不符合科学计数法,所以52位最前面有一个省略的数字是1,默认存在,但是不显示在52位中。
并且尾数用原码表示。
现在我们讲一下阶码需要注意的点。阶码是用的无符号定点整数表示,为[0,2047](2的11次方减一)但这就有一个问题了,不能表示负数,为了表示负数一般可以引入符号位,但是符号位定点数减法运算又要引入补码,就很麻烦,所以采取一种取巧的方式,将阶码部分统一减去1023,就变成[-1023, 1024]
又因为阶码的全0和全1有特殊用途,所以-1023和1024的移码就是全1和全0,所以阶码的范围变为[-1022, 1023]。那如果阶码是0和1有什么特殊用途呢?
当阶码E全为0,尾数M不全为0时,此时尾数隐藏的首位1.xxx的1变为0
当阶码E全为0,尾数M全为0时,表示真值正负0
当阶码E全为1,尾数M全为0时,表示无穷大
当阶码E全为1,尾数M不全为0时,表示NaN
指令系统(了解)
指令的格式
首先什么是指令呢?是指计算机执行某种操作的命令,是计算机运行的最小功能单位。一台计算机的所有指令的集合构成该机的指令系统,也称为指令集。比如著名的x86架构(intel的pc)和ARM架构(手机)的指令集是不同的。
比如之前有新闻说,苹果开发了基于ARM架构(精简指令集)的自己的芯片,放弃了之前采用复杂指令集的intel芯片。
一条指令就是机器语言的一个语句,它是一组有意义的二进制代码。一条指令通常包括操作码(OP) + 地址码(A)
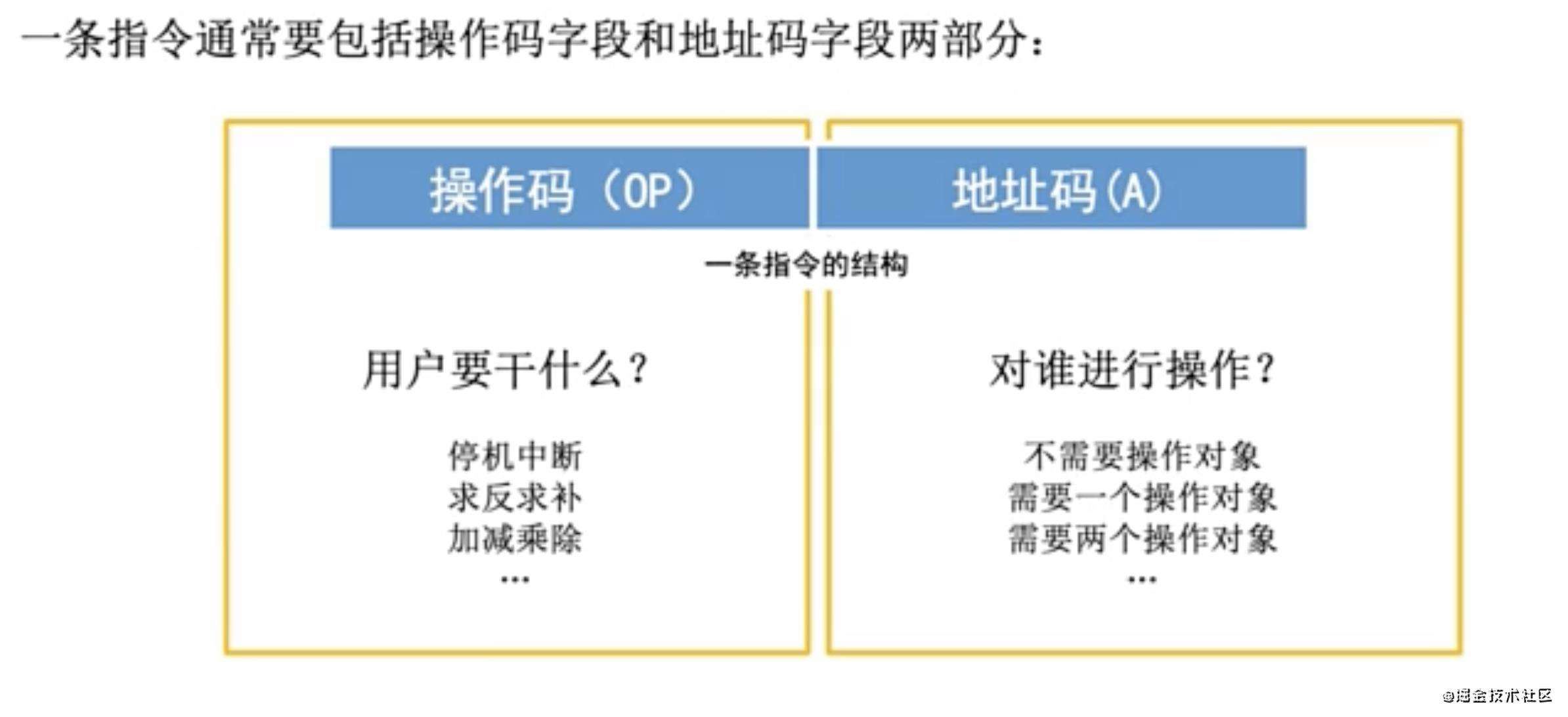
- 操作码简单来说就是我要进行什么操作,比如我要实现1+1,加法操作,停机操作等等
- 地址码就是比如实现加法操作的数据地址在哪,通常是内存地址。
根据指令中操作数地址码的数目不同,可将指令分成以下几种格式。我们举几个例子(没有覆盖全部)让大家感受一下,尤其注意三地址指令,就能理解指令的大致格式了
1、零地址指令

只给出操作码OP,没有显式地址。这种指令有两种可能:
- 不需要操作数的指令,如空操作指令、停机指令等
2、三地址指令

指令的含义:(A1)OP(A2)->A3
它表示从A1和A2地址上取出数据,然后进行OP操作,最后存放到A3地址上。
寻址方式
寻址寻什么呢?我们计算机里无非保存的是指令和数据,寻的就是上面这两个家伙。
指令寻址
指令寻址方式有两种:一种是顺序寻址方式,另一种是跳跃寻址方式。
1、顺序寻址可通过程序计数器PC加1,也就是按照在内存的顺序依次执行指令

2、跳跃寻址通过转移类指令实现,跳跃,就是不按照程序计数器自动加一的方式(不是按顺序执行指令)给出下调指令地址,而是由本条指令给出的下条指令格式
数据寻址
确定本条指令的地址码指明的真实地址。大致有10种寻址方式,我们只介绍其中3种,因为这部分内容都是以了解为主。
直接寻址
直接寻址是,在指令中的地址码指向的内存地址就是操作数的有效地址,如下图
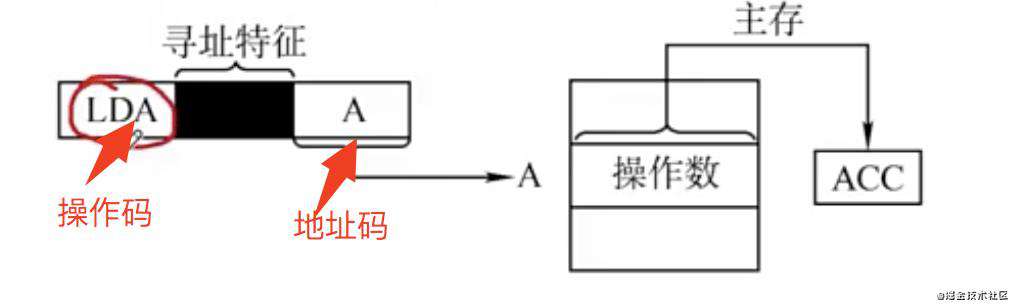
如上图,地址码A对应的就是我们要的操作数
间接寻址
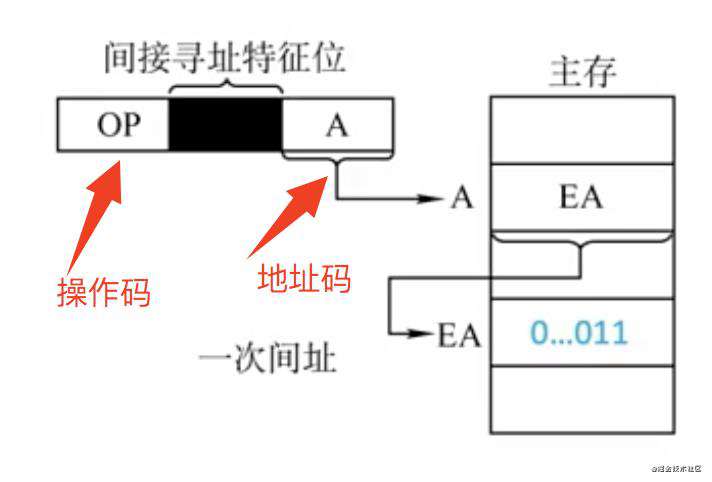
如上图,地址码A对应的不是操作数,而是另一个地址,这个地址指向的地址才是操作数
基址寻址
意思是寻到的地址,并不是我们要去内存寻找的真正地址,而是需要加上一个基础地址,相当于偏移量。如下图:
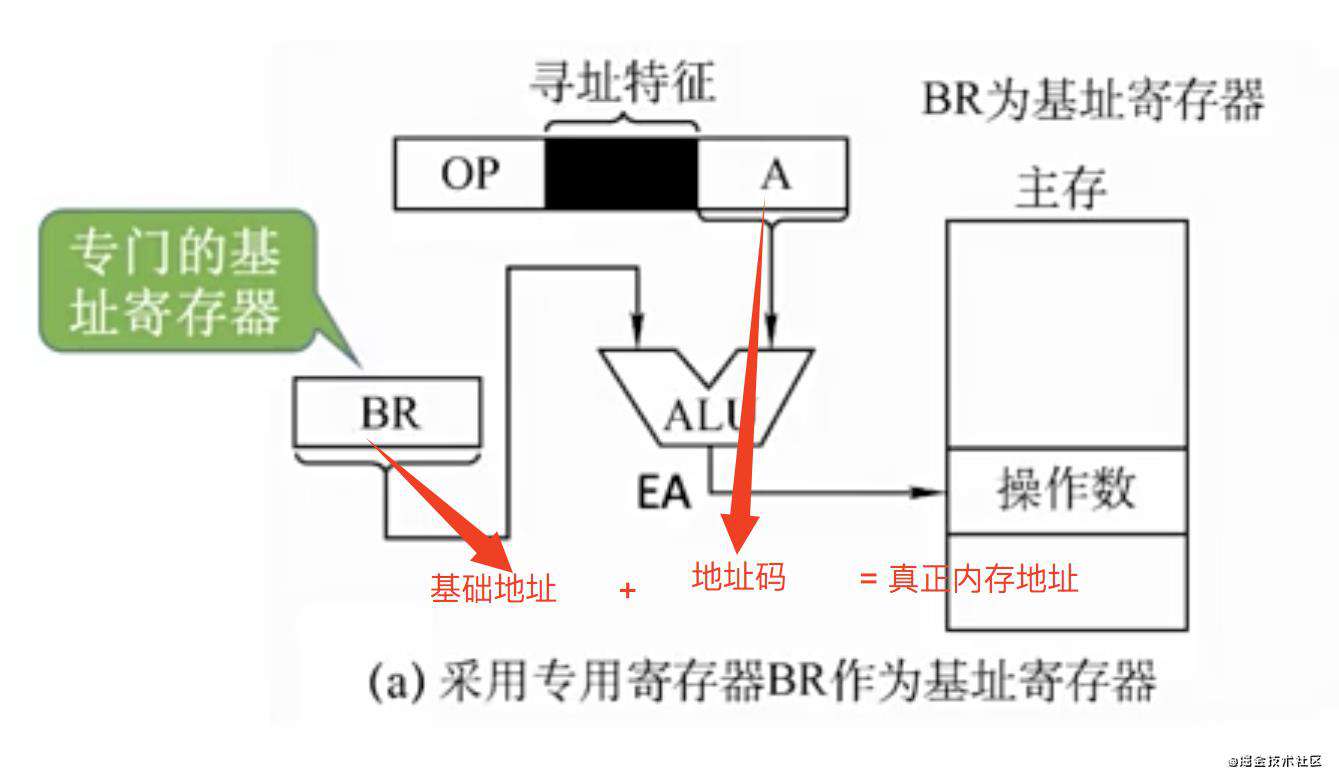
CISC和RISC
-
CISC (复杂指令系统计算机):一条指令完成一个复杂的基本功能。比如x86架构的计算机,主要用于笔记本和台式电脑。计算机的指令系统比较丰富,有专用指令来完成特定的功能。因此,处理特殊任务效率较高。
-
RISC (精简指令系统计算机):一条指令完成一个基本"动作";多条指令组合完成一个复杂的基本功能。比如ARM架构,主要用于手机,平板等。设计者把主要精力放在那些经常使用的指令上,尽量使它们具有简单高效的特色。对不常用的功能,常通过组合指令来完成。因此,在RISC 机器上实现特殊功能时,效率可能较低。
中央处理器 + GPU (了解)
- 因为我们在第一章已经了解过cpu和内存在执行指令的大致过程,其实学好第一章,就已经差不多了,所以大家可以回看一下第一节。
我这里补充一些cpu内部细节
CPU中比较重要的两个部件是运算器和控制器,我们先来看看运算器的主要作用
2.1 运算器主要部件
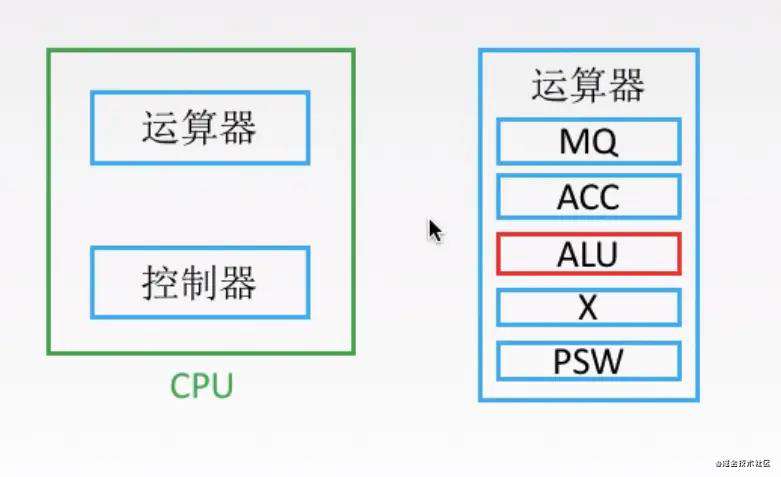
如上图,运算器里最重要的部件是ALU,中文叫算术逻辑单元,用来进行算术和逻辑运算的。其它的MQ,ACC这些我们不用管了,是一些寄存器。
2.2 控制器主要部件

控制器中最重要的部件是CU(控制单元),只要是分析指令,给出控制信号。
IR(指令寄存器),存放当前需要执行的指令
PC存放的指令的地址。
2.3 举例 - 取数指令执行过程
首先,是取指令的过程如下
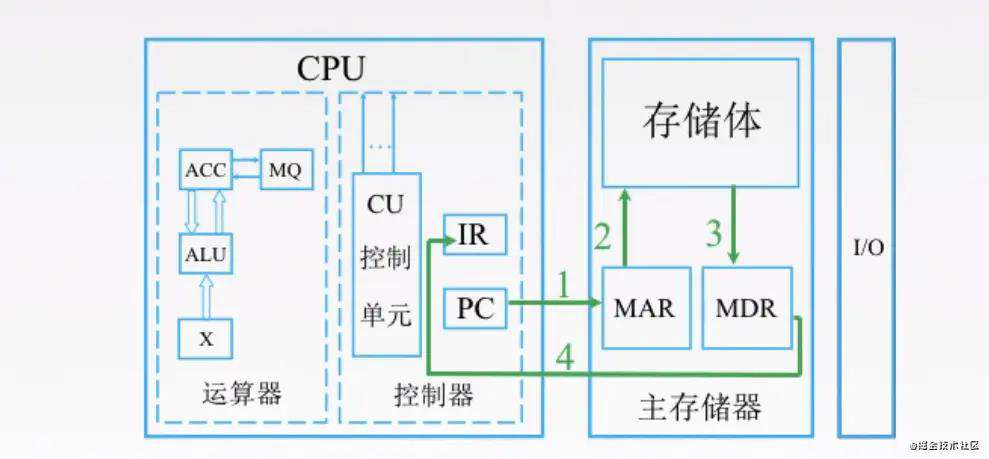
- 第一步,
PC,也就是存放指令地址的地方,我们要知道下一条指令是什么,就必须去存储器拿,CPU才知道接下来做什么。PC去了存储器的MAR拿要执行的指令地址,MAR(存储器里专门存指令地址的地方) - 第二步和第三步,
MAR去存储体内拿到指令之后,将指令地址放入MDR(存储器里专门存数据的地方) - 第四步
MDR里的数据返回到IR里面,IR是存放指令的地方,我们把刚才从存储体里拿的指令放在这里
然后,分析指令,执行指令的过程如下
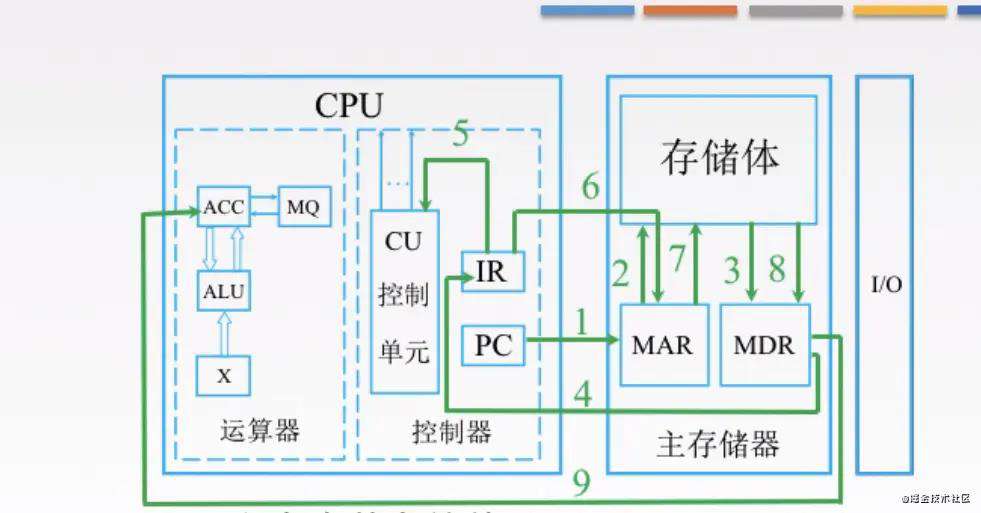
-
第五步,
IR将指令放入CU中,来分析指令,比如说分析出是一个取数指令,接着就要执行指令了(这里取数指令,其实就是一个地址码,按着这个地址去存储体取数据) -
第六步,第七步
IR就会接着去找存储体里的MAR(存储地址的地方),MAR就根据取数指令里的地址吗去存储体里去数据 -
第八步,取出的数据返回给
MDR(存放数据的地方) -
第九步,
MDR里的数据放到运算器的寄存器里,这里的取指令的过程结束了。 -
这里我们主要补充一下GPU的内容。
GPU(Graphics Processing Unit) 图形处理单元,又称图形处理器,是我们所周知的显卡的核心部件,是显卡的“心脏”。GPU是专为复杂数学运算和几何运算而设计的芯片,它的用途我们平常所周知的就是用于图形图像处理(显卡)。
CPU与GPU
我们可以看一下CPU和GPU的对比图

-
上图的一段总结非常好,CPU相当于1名老教授,奥数题和小学算术题都会,GPU相当于1000名小学生,只会小学算术题。
-
从上图我们可以知道GPU将更多的空间(晶体管)用作执行单元,而不是像CPU那样用作复杂的控制单元和缓存(CPU需要同时很好的支持并行和串行操作,需要很强的通用性来处理各种不同的数据类型,同时又要支持复杂通用的逻辑判断,这样会引入大量的分支跳转和中断的处理。
-
这些都使得CPU的内部结构异常复杂,计算单元的比重被降低了),实际来看CPU的芯片控件25%是ALU,而GPU则高达90%(GPU面对的则是类型高度统一的、相互无依赖的大规模数据和不需要被打断的纯净的计算环境。因此GPU的芯片比CPU芯片简单很多),这也就是为啥GPU运算能力超强的原因。
GPU加速在前端的应用
首先我们要知道为什么要用(开启)GPU加速(硬件加速), 然后我们才能去探讨如何以及怎么样去应用GPU加速。
-
3D 或透视变换(perspective,transform) CSS 属性
-
使用加速视频解码的video元素
-
拥有 3D (WebGL) 上下文或加速的 2D 上下文的 canvas 元素
-
混合插件(如 Flash)
-
对自己的 opacity 做 CSS 动画或使用一个动画 webkit 变换的元素
-
拥有加速 CSS 过滤器的元素
-
元素A有一个 z-index 比自己小的元素B,且元素B是一个合成层(换句话说就是该元素在复合层上面渲染),则元素A会提升为合成层
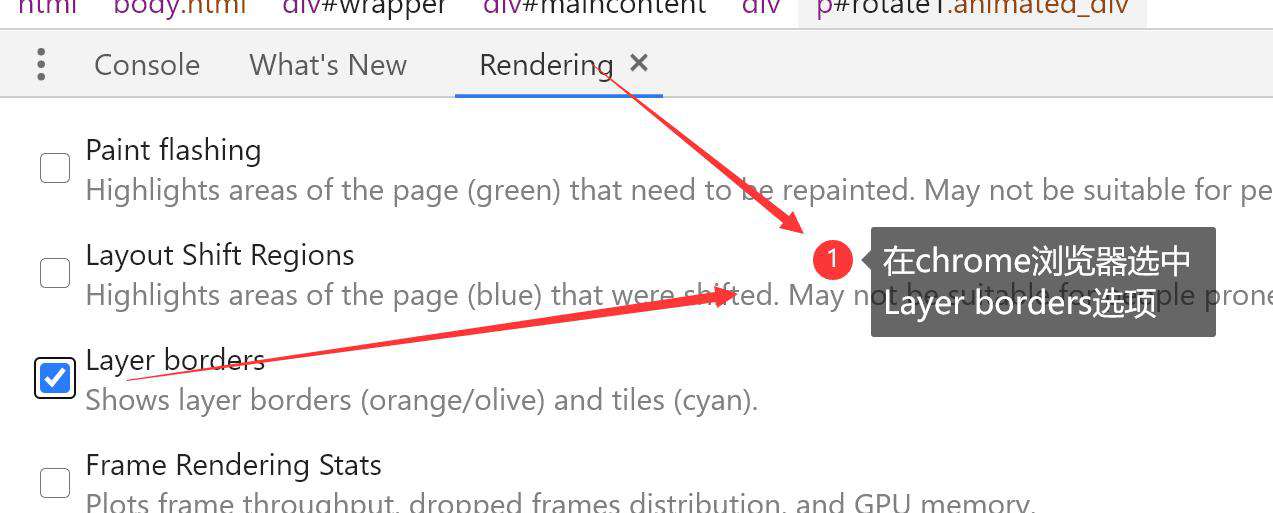
这里里面最常用的是1和7。1很好理解,就是transfrom3d属性。第七点我解释一下,你怎么来判断自己的页面是否使用了3d加速。请看下图:
首先:
然后观察这两个图层:
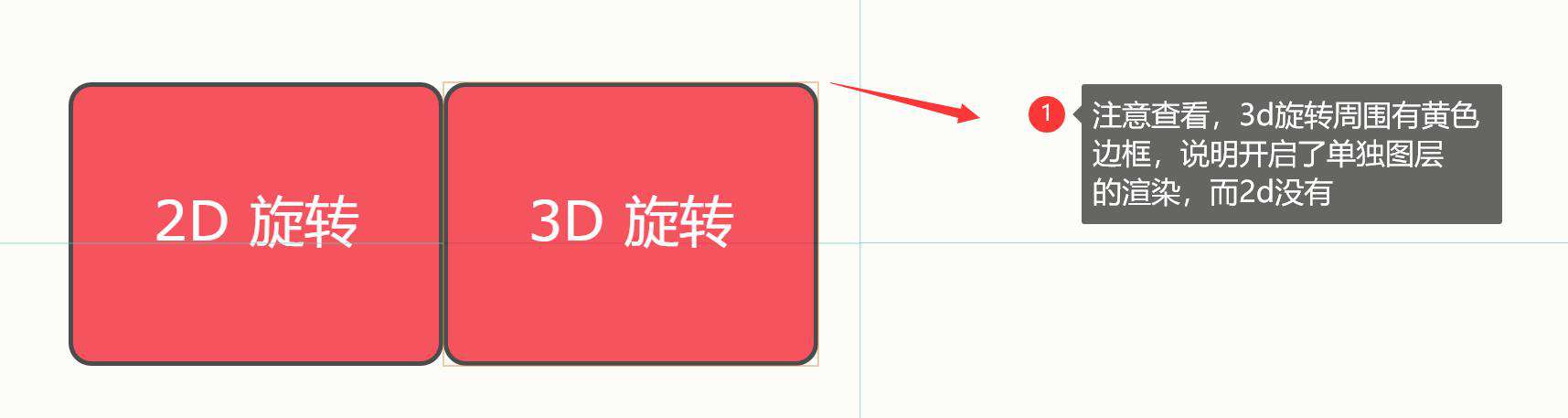
那如何让2d也能单独的图层渲染启用GPU加速呢,只需要给2d的css上加一个index之后,然后点击动画,就会出现黄色边框,大家可以用这个网址做测试:www.w3school.com.cn/css3/css3_3…
总线(了解即可)
- 总线这部分不是重点,主要了解总线的大致工作工作流程即可
总线的定义
总线是一组能为多个部件分时共享的公共信息传送线路
为什么需要总线结构
1、简化了硬件的设计。我们从计算机简史里面知道,当时的设备是分散接入计算机的,这样计算机没办法统一接口命令来控制这些设备。总线结构便于采用模块化结构设计方法,面向总线的微型计算机设计只要按照这些规定制作cpu插件、存储器插件以及I/O插件等,将它们连入总线就可工作,而不必考虑总线的详细操作。
2、系统扩充性好。一是规模扩充,规模扩充仅仅需要多插一些同类型的插件。二是功能扩充,功能扩充仅仅需要按照总线标准设计新插件,插件插入机器的位置往往没有严格的限制。
就相当于webpack的插件系统,加入功能和减少功能都是可插拔的,比把代码写死更加灵活。
总线工作的简单过程
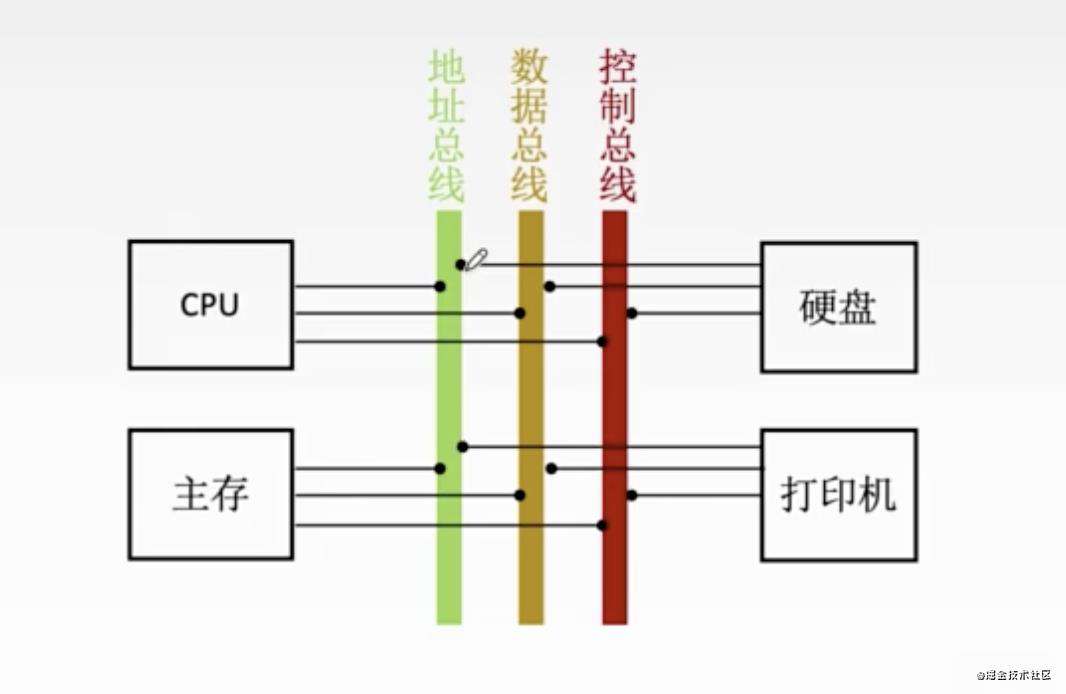
我们拿上图为例:
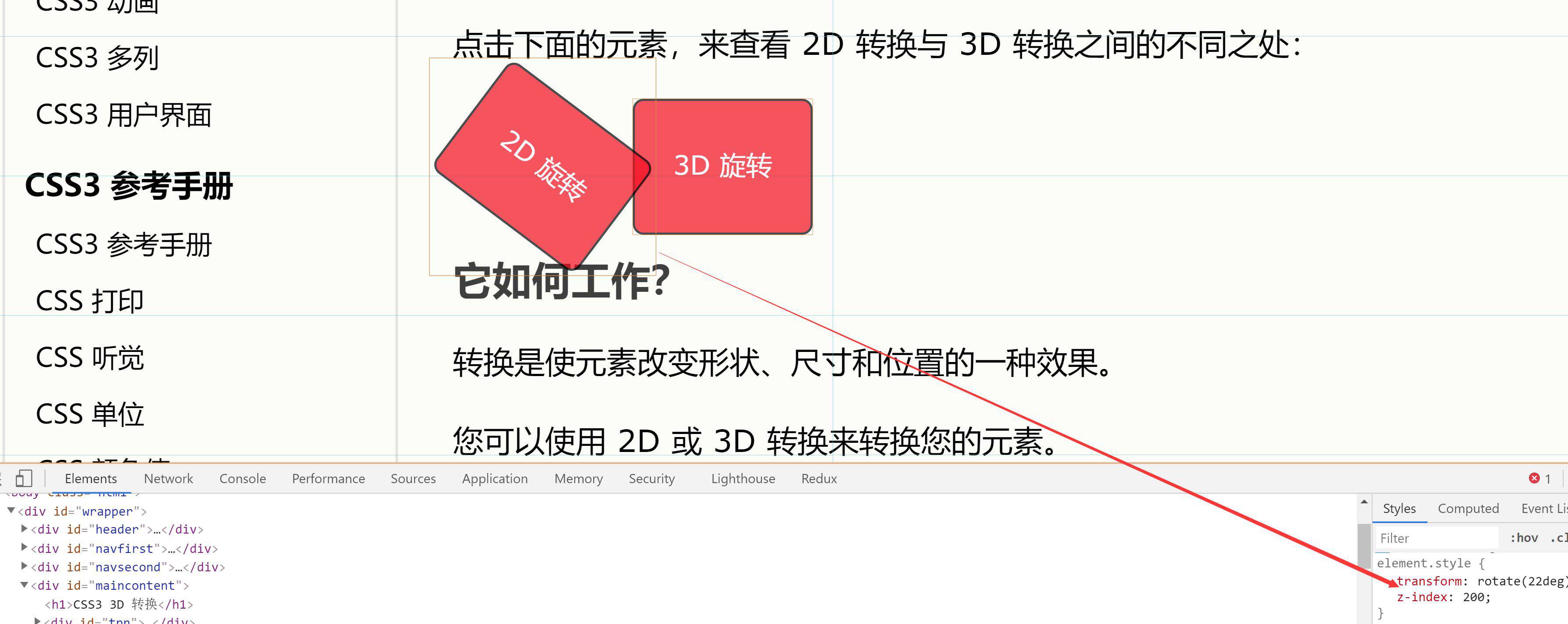
- CPU可以通过地址总线给主存、打印机或者硬盘发送地址信息。
- 同理,CPU也可以通过数据总线和控制总线去跟其他硬件设备进行数据传输或者发送控制命令
存储系统
- 本章绝对重点就是cache的基本原理(为什么需要cache, 局部性原理是什么),cache的替换算法(面试被好几次问道LRU缓存算法怎么写)
多级存储系统(了解)
为什么需要多级存储的结构呢?如下图所示,可以了解到为什么要引入cache
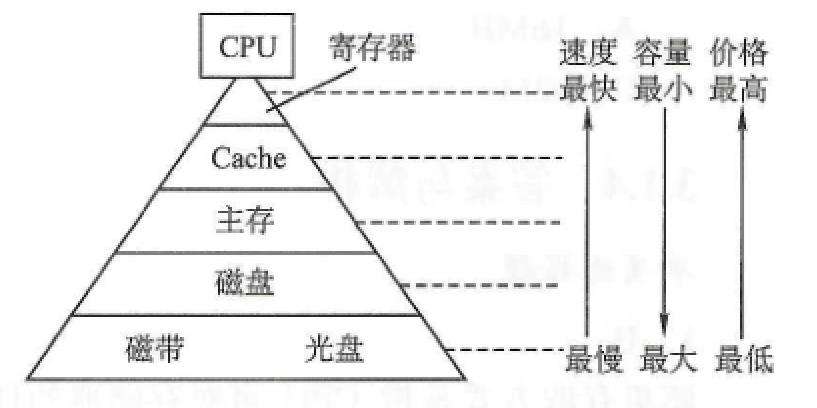
主存的执行速度相比cpu要慢很多,这会造成主存在运行的时候,cpu会等待的问题,比如cpu1秒就处理10条指,但从内存里取10条指令就需要1分钟,就很浪费cpu资源,所以为了解决这个问题,采用了cache-主存的方式,cache是高速缓冲储存器,它的速度接近于cpu。
存储器的分类 --- 按存取方式(了解)
- 随机存取存储器:读写任何一个存储单元所需要的时间都相同,与存储单元所在的物理位置无关。比如内存条。
- 顺序存取存储器:读写一个存储单元所需时间取决于存储单元所在的位置。比如磁带,你如果已经放完了磁带,想从头开始听,需要倒带到开始的位置。
RAM和ROM的特点(重点)
RAM
RAM又被称作“随机存储器”,是与CPU直接交换数据的内部存储器,也叫主存(内存)。它可以随时读写,而且速度很快,通常作为操作系统或其他正在运行中的程序的临时数据存储媒介。当电源关闭时RAM不能保留数据(掉电数据消失哦)如果需要保存数据,就必须把它们写入一个长期的存储设备中(例如硬盘)。
ROM
ROM又被称为“只读存储器”,ROM所存数据,一般是装入整机前事先写好的,整机工作过程中只能读出,而不像随机存储器那样能快速地、方便地加以改写。ROM所存数据稳定,断电后所存数据也不会改变
局部性原理(重点)
先看下图
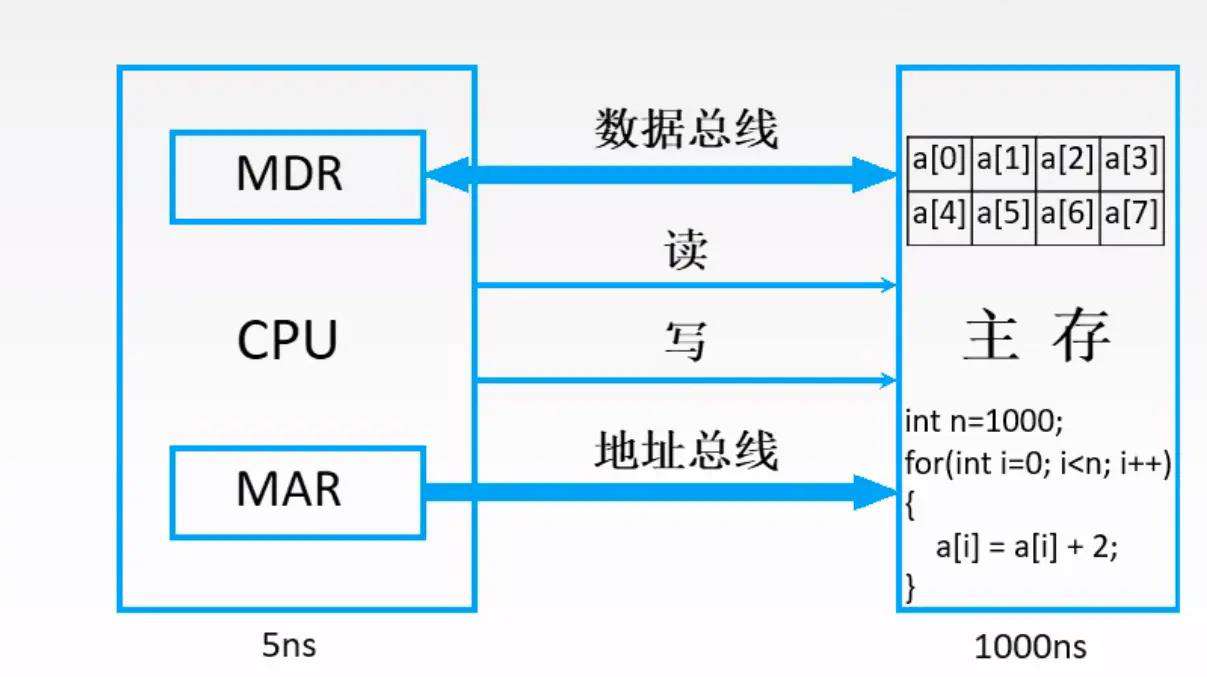
(说明一下,MDR和MAR虽然逻辑上属于主存,但是在电路实现的时候,MDR和MAR离CPU比较近)
上图是在执行一串代码,可以理解为js的for循环
const n = 1000;
const a = [1, 2, 3, 4, 5, 6, 7]
for(let i =0; i < n; i++) {
a[i] = a[i] + 2
}
我们可以发现
-
数组的数据有时候在内存是连续存储的(代码里但数组a,对应图中主存里但a[0]-a[7]的数据块)
-
如果我们要取数据,比如从内存取出a[0]的数据需要1000ns(ns是纳秒的意思),那么取出a[0]到a[7]就需要1000 * 8 = 8000 ns
-
如果我们cpu发现这是取数组数据,那么我就把就近的数据块a[0]到a[7]全部存到缓存上多好,这样只需要取一次数据,消耗1000ns
cahce就是局部性原理的一个应用
空间局部性:在最近的未来要用到的信息(指令和数据),很可能与现在正在使用的信息在存储空间上是邻近的(比如for循环用到数据在主存都是相邻存储的)时间局部性:在最近的未来要用到的信息,很可能是现在正在使用的信息
下图注意的是,cpu拿数据是先从cache里拿,如果没有才从主存里面取
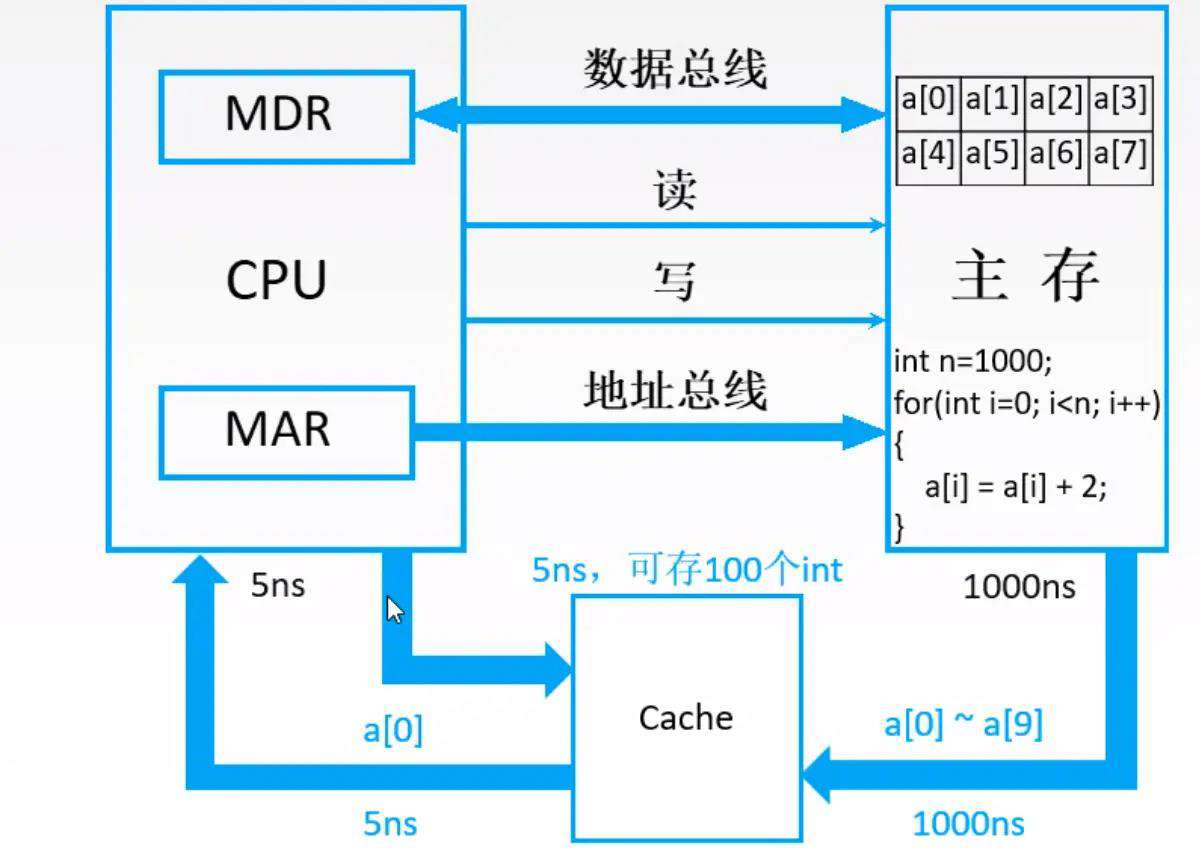
可以看到cache一次性取了a[0]到a[9]存储体上的数据,只需要1000ns,因为Cache是高速存储器,跟cpu交互速度就比cpu跟主存交互速度快很多
输入/输出系统
- I/O这部分重中之中的知识点是I/O方式,即理解马上就要讲到的I/O设备的演进过程,其它知识点作为了解就好
I/O是什么呢?
输入/输出(Input /Output ,简称I/O),指的是一切操作、程序或设备与计算机之间发生的数据传输过程。
比如文件读写操作,就是典型的I/O操作。接下来我们看一下I/O设备的演进过程
I/O设备的演进过程
关键:I/O设备的演进过程其实就是解放cpu的过程,为什么这么说呢,看完下面的介绍就知道了!

- 早期计算机主要功能就是计算,所以就以cpu为核心
- 外设连接cpu需要一套专用的线路,外设的增删就很麻烦
- cpu和外设串行工作模式
在早期的计算机里,因为cpu启动外设后,外设准备数据是需要时间的,比如读取外部传来的数据,此时cpu如何知道I/O设备已经完成任务呢?比如说怎么知道I/O设备已经读取完一个文件的数据呢?CPU会不断查询I/O设备是否已经准备好。这时,cpu就处于等待状态。也就是cpu工作的时候,I/O系统是不工作的,I/O系统工作,cpu是不工作。而且主存和外设也需要借助cpu来通信,所以留给CPU的时间又少了。
所以我来看此阶段比较明显的问题:
- 外设设备分散连接,外设的增删就很麻烦 ,我们引入了总线结构
- 高速外设跟cpu交流频繁
接着看第二阶段
- cpu启动好外设之后,就返回继续自己的工作了,外设准备好数据后,通过中断请求的方式通知cpu,cpu只需要暂停手上的工作,处理一下具体数据传输的过程,减少不断查询的时间
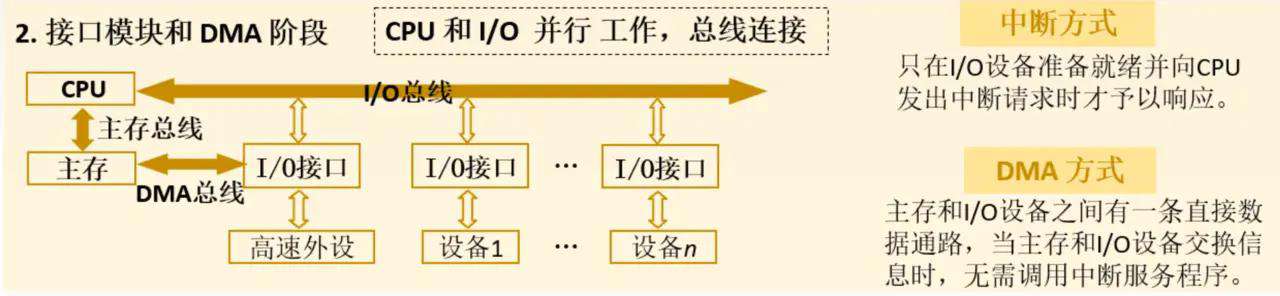
-
为了解决第一阶段
CPU要等待I/O设备,串行的工作方式,所有I/O设备通过I/O总线来跟CPU打交道,一旦某个I/O设备完成任务,就会以中断请求的方式,通过I/O总线,告诉CPU,我已经准备好了。 -
但是对于
高速外设,它们完成任务的速度很快,所以会频繁中断CPU,(举一个例子,每输入一个字符就中断CPU,是不是很影响cpu的执行呢) 为了解决这个问题,高速外设跟主存之间用一条直接数据通路,DMA总线连接,DMA控制方式只需要CPU安排最开始高速外设最初的任务,接下来的数据交换就是靠DMA控制器控制了,这样就可以防止频繁中断CPU,让CPU得到了解放
问题:
- DMA控制器的传送任务是cpu来安排的,还有dma连接外设的类型和数量是不灵活的,所以我们设置了一些专门管理外设的处理器
最后来看一下第三阶段

第三阶段,CPU通过通道控制部件来管理I/O设备,CPU不需要帮它安排任务,只需要简单的发出启动和停止类似的命令,通道部件就会自动的安排相应的I/O设备工作。为什么这种方式比DMA更好呢,因为商用的中型机、大型机可能会接上超多的I/O设备,如果都让CPU来管理,那么CPU就非常累。
通道可以理解为一种“弱鸡版的CPU”。可以识别通道指令,你可以理解为CPU告诉通道,取多少数据,数据存放到内存哪里,通道就自己去处理,不用cpu来管理这么多事情,注意看下图
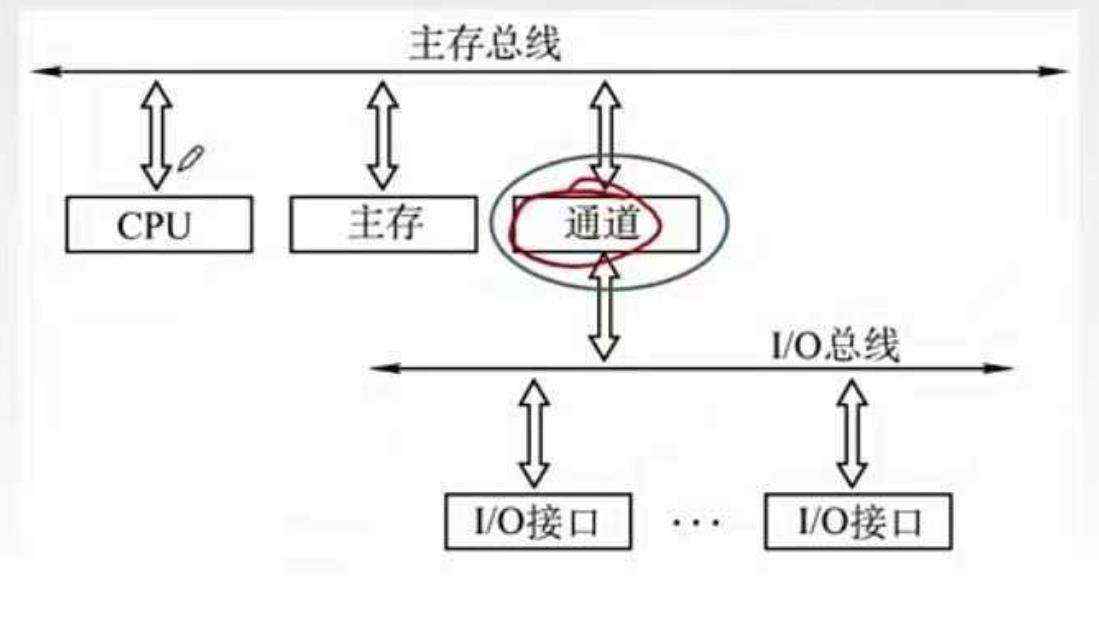
如上图,通道是跟CPU并列的,所以通道能帮CPU分担任务,此时的通道有自己的一套指令集,可以执行通道指令。
后面进一步增强了通道的功能,这里出现了跟cpu处理能力差不多的I/O处理机

补充:中断是什么(重点,操作系统课也会涉及这个概念)
之前我们讲到一个名词叫中断,这个概念非常重要,我们作为补充概念学习一下
中断的概念
程序中断是指在计算机执行现行程序的过程中,出现某些急需处理的异常情况或特殊请求,CPU暂时中止现行程序,而转去对这些异常情况或特殊请求进行处理,在处理完毕后CPU又自动返回到现行的断点处,继续执行程序。我们来举个例子就明白了。
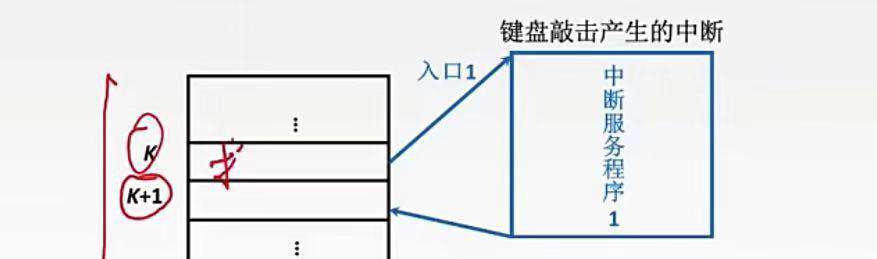
当程序执行到K的时候,键盘的敲击产生了中断(I/O中断),此时CPU会终止执行当前的指令,转而去处理中断,等中断服务程序执行完毕,继续执行k+1。
本文主要参考资料:
唐朔飞:计算机组成原理
袁春风: 计算机组成原理
王道考研:计算机组成原理
极客时间:深入浅出计算机组成原理
常见问题FAQ
- 免费下载或者VIP会员专享资源能否直接商用?
- 本站所有资源版权均属于原作者所有,这里所提供资源均只能用于参考学习用,请勿直接商用。若由于商用引起版权纠纷,一切责任均由使用者承担。更多说明请参考 VIP介绍。
- 提示下载完但解压或打开不了?
- 找不到素材资源介绍文章里的示例图片?
- 模板不会安装或需要功能定制以及二次开发?





发表评论
还没有评论,快来抢沙发吧!