Hi~ 我是前端学徒业枫(@Malpor),今天为大家带来一篇硬核前端智能化教程,真·手把手教你用机器学习打造一个纯前端运行的图标智能识别工具。并附上完整代码,一起来体验前端智能化的魅力吧~
背景
目前的前端组件库都使用 Iconfont 来管理图标,随着时间推移,图标越来越多,图标的命名也五花八门,很难约束。开发者还原设计稿时,经常要人肉从几百个图标中寻找对应的图标。有时候连设计师都找不到,导致重复添加图标。
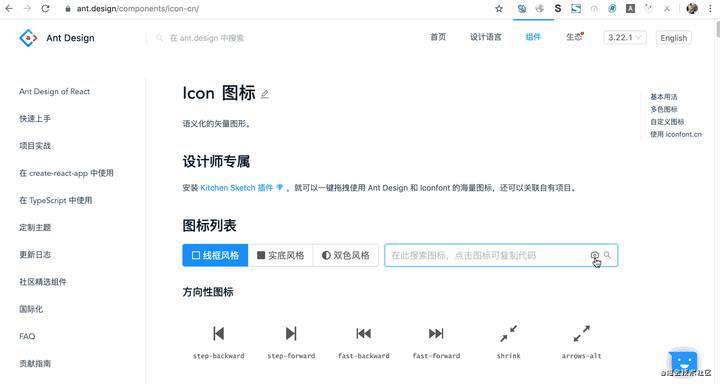
最近发现在 AntDesign 官网有以图搜图标的功能,用户对设计稿或任意图片中的图标截图,点击/拖拽/粘贴上传,就可以搜索到匹配度最高的几个图标:AntDesign Icon ,功能开发者文章
这个功能很好的解决了上面提到的问题,但还有些不足:
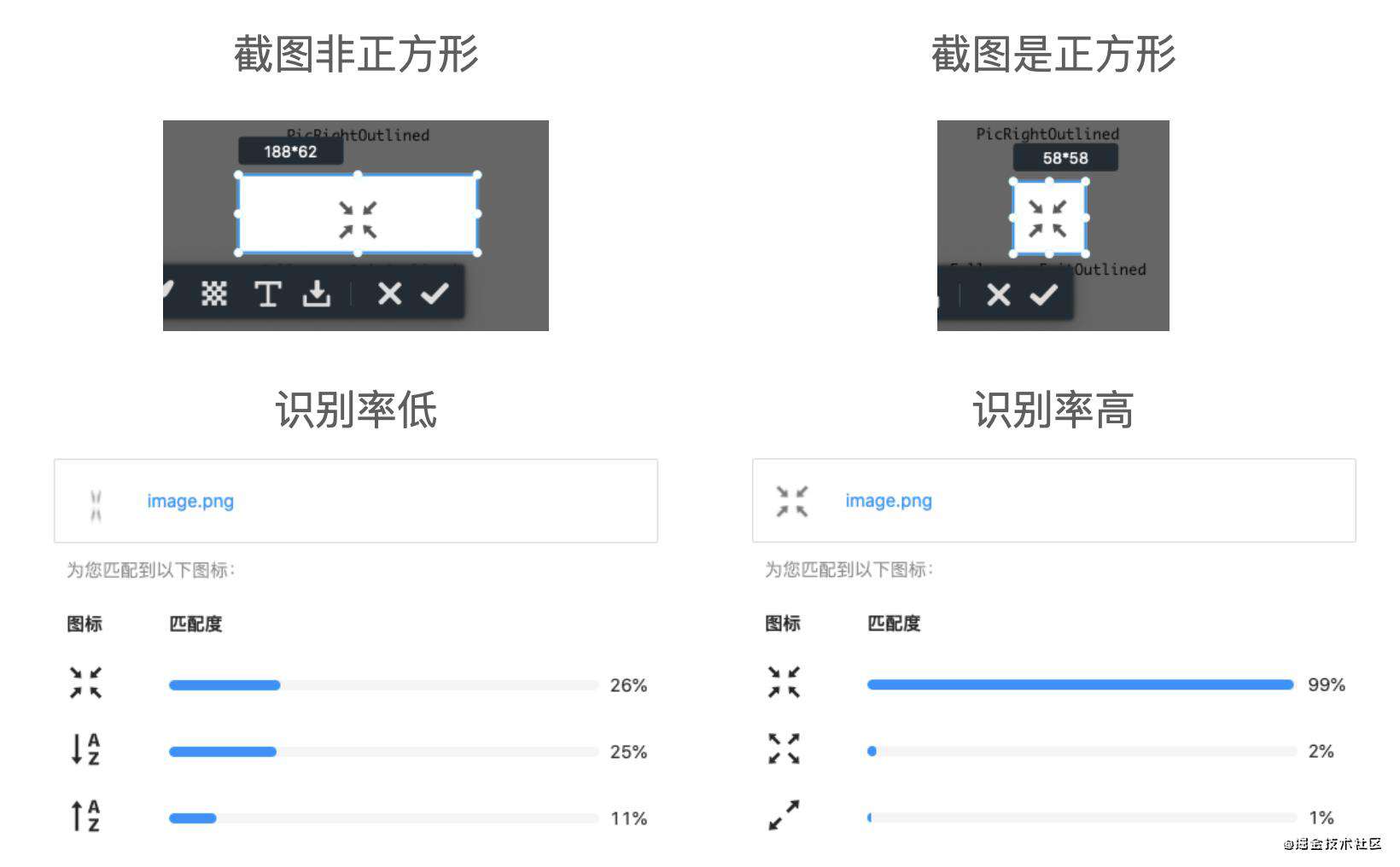
- 截图最好是正方形的,否则拉伸后识别率会下降(后面会解释)。
- 只能识别 AntDesign 的图标。
为了解决这些问题,我们决定自己打造一个前端图标识别工具。下面将以我们团队的开源组件库 Cloud Design 为例,手把手教你打造纯前端的专属图标识别工具。(完整代码放在文末)
术语简介
简单介绍几个术语,了解的同学可以直接跳过。
机器学习
机器学习包含:线性回归、贝叶斯、聚类、决策树、深度学习等等。前面 AntDesign 的模型是通过深度学习的代表算法 CNN 训练得到的。
CNN 卷积神经网络
CNN 能有效的将大数据量图片降维到小数据量,且保留图像特征,非常适合处理图像数据。即使图像翻转、旋转或变换位置也能有效识别,常用来解决:图像分类检索、目标定位监测、人脸识别等等。
开始行动吧
我们要对图标进行识别,属于机器学习中经典的“图像分类”问题。CNN(卷积神经网络) 可以有效的识别图标,但是无法适应拉伸变形的场景。因为模型输入时要先把图像变换为正方形尺寸,截图尺寸不对会导致图像拉伸变形,降低识别率,甚至识别错误。
常用的解法有两种:
1、纯机器学习:通过增加不同拉伸状态的样本,让模型适应变形的图像。
2、机器学习 + 图像处理:用图像处理算法对数据进行裁剪,保证图像接近正方形。
第一种方法需要生成大量的训练数据,训练速度变慢,而且拉伸变形的情况很难遍历。第二种方法只需要进行简单的图像处理就可以有效提高识别率,所以我选择了它。那最终工作流应该是这样的:
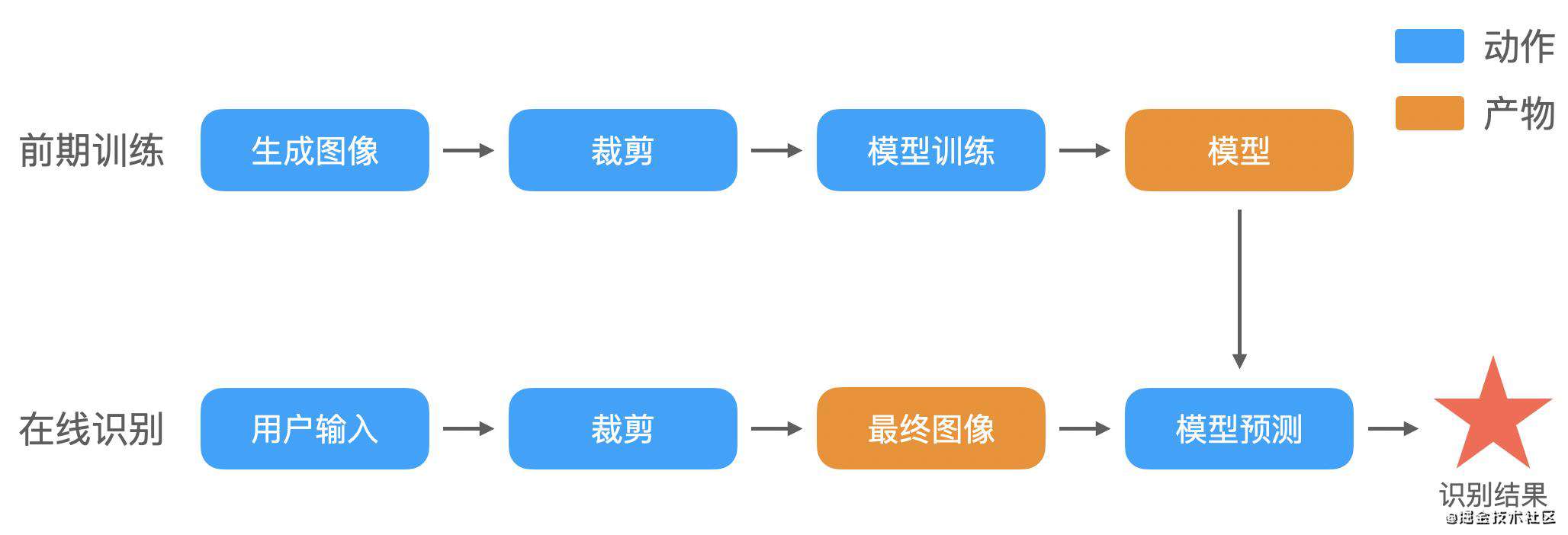
接下来我会从 样本生成、模型训练、模型使用 三部分来介绍完整的过程。
样本生成
图像分类的训练样本都是图片,我们的图标则是 iconfont 渲染在页面中的。可以自然想到用 样本页面 + Puppeteer 截图来生成样本。但截图速度很慢,我也不想用 Faas 服务,于是想了个本地生成的方法:
首先人工把图标库的css部分转为js:

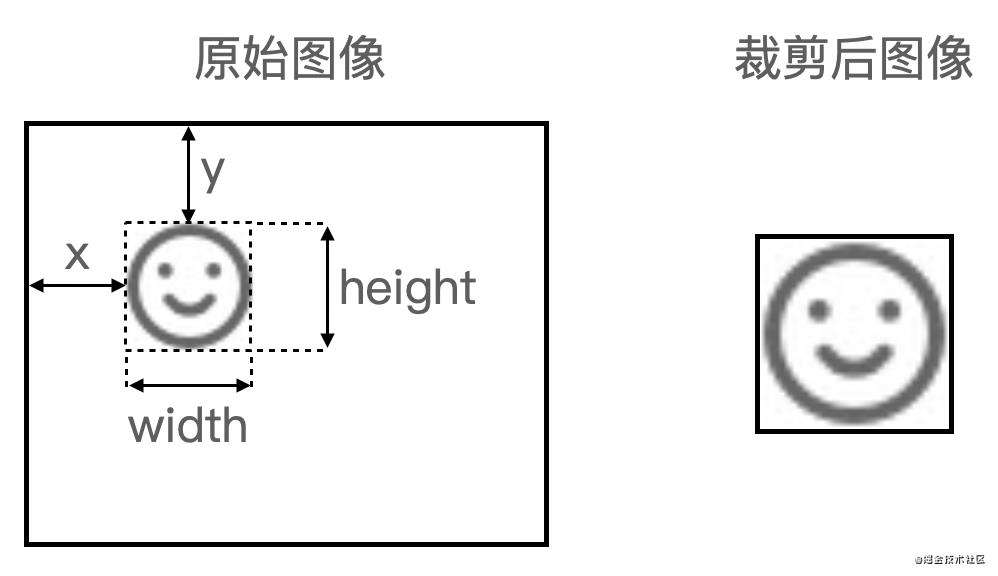
这样就能把图标当作文本绘制在 canvas 上,并用图像算法裁剪四周的空白区域:
// 用离屏 canvas 绘制图标
offscreenCtx.font = `20px NextIcon`;
offscreenCtx.fillText(labelMap[labelName]);
// 用 getImageData 获取图片数据,计算需裁剪的坐标
const { x, y, width: w, height: h } = getCutPosition(canvasSize, canvasSize, offscreenCtx.getImageData(0, 0, canvasSize, canvasSize).data);
// 计算需裁剪的坐标
function getCutPosition(width, height, imgData) {
let lOffset = width; let rOffset = 0; let tOffset = height; let bOffset = 0;
// 遍历像素,获取最小的非空白矩形区域
for (let i = 0; i < width; i++) {
for (let j = 0; j < height; j++) {
const pos = (i + width * j) * 4;
if (notEmpty(imgData[pos], imgData[pos + 1], imgData[pos + 2], imgData[pos + 3])) {
// 调整 lOffset、rOffset、tOffset、bOffset
// 略
}
}
}
// 如果形状不是正方形,将其扩展为正方形
const r = (rOffset - lOffset) / (bOffset - tOffset);
if (r !== 1) {
// 略
}
return { x: lOffset, y: tOffset, width: rOffset - lOffset, height: bOffset - tOffset };
}
// 阈值 0 - 255
const d = 5;
// 判断是否非空白像素
function notEmpty(r, g, b, a) {
return r < 255 - d && g < 255 - d && b < 255 - d;
}
// 用 canvas 裁剪 & 缩放图像,导出为 base64
ctx.drawImage(offscreenCanvas, x, y, w, h, 0, 0, 96, 96);
canvas.toDataURL('image/jpeg');
生成一张图片的逻辑就写完了。改造一下,遍历不同图标、不同字号,可以得到全量的样本:
const fontStep = 1;
const fontSize = [20, 96];
labels.map((labelName) => {
// 遍历不同的字号绘制图标
for (let i = fontSize[0]; i <= fontSize[1]; i += fontStep) {
// ...before
offscreenCtx.font = `${i}px NextIcon`;
// 其它逻辑
}
});
通过 Blob 将数据作为一个 json 下载:
const resultData = /* 生成全量数据 */;
const aLink = document.createElement('a');
const blob = new Blob([JSON.stringify(resultData, null, 2)], { type : 'application/json' });
aLink.download = 'icon.json';
aLink.href = URL.createObjectURL(blob);
aLink.click();
这样就得到了包含几万张(350个图标,每个分类约70张图)样本图片的大 json,大概长这样:
[
{
"name": "smile",
"data": [
{
"url": "data:image/jpeg;base64,/9j/4AA...IkB//9k=",
"size": 20
},
{
"url": "data:image/jpeg;base64,/9j/4AA...JAf//Z",
"size": 21
},
...
]
},
]
最后写一个简单的 node 程序,把每个分类的样本按照训练集70%,验证集20%,测试集10%的比例拆分打散并存储为图片文件。
--- train
|-- smile
|-- smile_3.jpg
|-- smile_7.jpg
|-- cry
|-- cry_2.jpg
|-- cry_8.jpg
...
--- validation
|-- smile
|-- cry
...
--- test
|-- smile
|-- cry
...
这样我们就得到了完整的训练样本,而且生成速度很快,运行一遍只要1分钟左右。然后把三个目录一起打包成一个 zip 文件即可,因为下一步训练只支持 zip 格式。
模型训练
机器学习工具有很多种,作为一个前端,我最终选择使用 Pipcook 来训练。
Pipcook 的安装和教程看官网(链接)即可,要注意目前只支持 Mac & Linux,Windows 暂时无法使用(Windows 可以使用 Tensorflow.js 训练)。
写一份 pipcook 的配置项:
{
"plugins": {
"dataCollect": {
"package": "@pipcook/plugins-image-classification-data-collect",
"params": {
"url": "file://绝对路径,指向上一步打包的文件.zip"
}
},
"dataAccess": {
"package": "@pipcook/plugins-pascalvoc-data-access"
},
"dataProcess": {
"package": "@pipcook/plugins-tfjs-image-classification-process",
"params": {
"resize": [224, 224]
}
},
"modelDefine": {
"package": "@pipcook/plugins-tfjs-mobilenet-model-define",
"params": {}
},
"modelTrain": {
"package": "@pipcook/plugins-image-classification-tfjs-model-train",
"params": {
"batchSize": 64,
"epochs": 12
}
},
"modelEvaluate": {
"package": "@pipcook/plugins-image-classification-tfjs-model-evaluate"
}
}
}
使用 Pipcook 配套的 Cli 工具开始训练:
$ pipcook run 上面写的配置项.json
看到出现 Epochs 和 Iteration 字样说明训练成功开始了。
...
ℹ [job] running modelTrain start
ℹ start loading plugin @pipcook/plugins-image-classification-tfjs-model-train
ℹ @pipcook/plugins-image-classification-tfjs-model-train plugin is loaded
ℹ Epoch 0/12 start
ℹ Iteration 0/303 result --- loss: 5.969481468200684 accuracy: 0
ℹ Iteration 30/303 result --- loss: 5.65574312210083 accuracy: 0.015625
ℹ Iteration 60/303 result --- loss: 5.293442726135254 accuracy: 0.0625
ℹ Iteration 90/303 result --- loss: 4.970404624938965 accuracy: 0.03125
...
两万多张样本以上面的参数在我的 Mac 上训练大约需要两个小时,期间电脑的 cpu 资源都会被占用,所以要找好空闲的时间训练。如果中途要停下来,用 control + c 是没用的,需要先用 pipcook job list 查看任务列表,再用 pipcook job stop <jobId> 来停止训练。
训练的时长与:样本的数据量、epochs 和 batchSize 有关。
/* =============== 两个小时后... =============== */
训练完成,能看到最终的损失率(越低越好)和准确率(越高越好):
...
ℹ [job] running modelEvaluate start
ℹ start loading plugin @pipcook/plugins-image-classification-tfjs-model-evaluate
ℹ @pipcook/plugins-image-classification-tfjs-model-evaluate plugin is loaded
ℹ Evaluate Result: loss: 0.05339580587460659 accuracy: 0.9850694444444444
...
如果损失率大于 0.2,准确率低于 0.8,那训练的效果就不太好了,需要调整参数或样本,然后重新训练。
同时 pipcook 会在配置项 json 同目录下创建一个 output 文件夹,里面包含了我们需要的模型:
output
|-- logs # 训练日志文件夹
|-- model # 模型文件夹,里面两个文件就是最终需要的产物
|-- weights.bin
|-- model.json
|-- metadata.json # 元信息
|-- package.json # 项目信息
|-- index.js # 默认入口文件
|-- boapkg.js # 辅助文件
模型使用
因为用的 Pipcook 插件底层调用 Tensorflow.js 进行训练,所以模型可以直接在前端页面运行。
我们先把生成的 model.json 和 weights.bin 放在同一目录下存好。然后找到 metadata.json 中的 output.dataset 字段,是个 Json 字符串,反序列化后找到的 labelArray 属性的值并且存下来:
// 目前这个顺序是随机生成的,和样本生成时的顺序不一样,不要混淆了
const labelArray = ["col-before","h1","solidDown","add-test",...];
准备就绪,只要再写一些 Tensorflow.js 代码就可以进行识别了。
import * as tf from '@tensorflow/tfjs';
const modelUrl = 'model.json 的访问地址';
// 加载模型
model = await tf.loadLayersModel(modelUrl);
// 对输入图像裁剪
const { x, y, width: w, height: h } = getCutPosition(imgW, imgH, offscreenCtx.getImageData(0, 0, imgW, imgH).data, 'white');
ctx.drawImage(offscreenCanvas, x, y, w, h, 0, 0, cutSize, cutSize);
// 图像转化为 tensor
const imgTensor = tf.image
.resizeBilinear(tf.browser.fromPixels(canvas), [224, 224])
.reshape([1, 224, 224, 3]);
// 模型识别
const pred = model.predict(imgTensor).arraySync()[0];
// 找出相似度最高的 5 项
const result = pred.map((score, i) => ({ score, label: labelArray[i] }))
.sort((a, b) => b.score - a.score)
.slice(0, 5);
大功告成
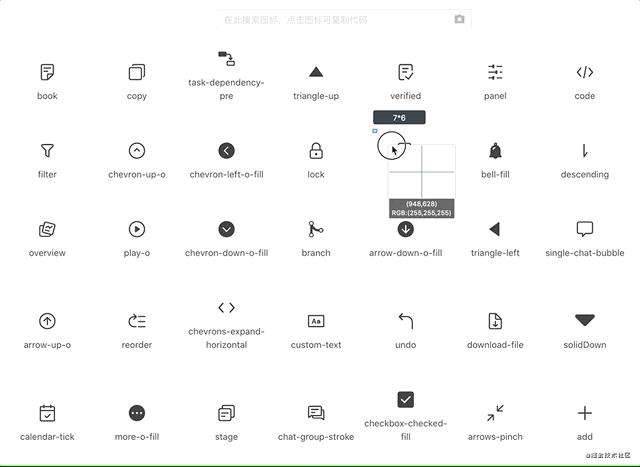
现在可以开始体验图标识别的能力,享受机器学习带来的便利了。这是一个纯前端工具,无需额外后端服务,可以在静态网站上部署,非常适合在组件库网站中查找图标的场景。团队有自己的图标库也完全没问题,只要按照步骤走,就能训练出专属的模型。
完整代码见:github.com/maplor/icon…
总结
从开始写代码到模型能用花了一个周末加两个晚上,而搭建环境和训练模型的时间占了很大比例。Pipcook 虽然使用简单,省去了很多工作,但入门也有不少坑:文档稀少,插件的参数只有看源码才明白,运行过程有一些潜规则需要不断试错。希望 Pipcook 的文档能及时更新和维护。
如果有什么疑问可以在评论指出,欢迎大家体验交流~
常见问题
- 图标库如果有 新增/修改 图标怎么办?答:需要重新训练模型。
参考资料
斯坦福《机器学习》课程
《Tensorflow.js 海量图标,毫秒级识别!》
Tensorflow.js 官网
Pipcook 官网
一文看懂机器学习
一文看懂卷积神经网络 CNN
加入我们
我们是阿里云的 TXD(体验技术)团队,诚招前端和设计师,22届的实习生校招也在火热进行中,感兴趣的同学可以联系我了解更多信息:zhaoye.zzy@alibaba-inc.com

常见问题FAQ
- 免费下载或者VIP会员专享资源能否直接商用?
- 本站所有资源版权均属于原作者所有,这里所提供资源均只能用于参考学习用,请勿直接商用。若由于商用引起版权纠纷,一切责任均由使用者承担。更多说明请参考 VIP介绍。
- 提示下载完但解压或打开不了?
- 找不到素材资源介绍文章里的示例图片?
- 模板不会安装或需要功能定制以及二次开发?





发表评论
还没有评论,快来抢沙发吧!