
了解V8
何为揭秘八股文
常规操作:
如果你是面试官: 打开网站直接搜索面试题,背下来直接问
如果你是求职者: 打开网站直接搜索面试题,背下来直接回答
加分操作:
本文将从V8出发从原理到面试题进行一个串联,帮助你形成一个比较好的体系。
为什么要了解V8
计算机技术日益精进,随着底层优化,原来的答案或许早已过时,同时我们也应该了解一些更细枝末节的东西,它有助于我们形成知识体系,更能让我们在解释知识点的时候让他 人眼前一亮。
我们知道的这些内容,大多都说是JS里的特性,这可能只是一个笼统模糊的回答,第一个重点:V8 和 宿主 的功能傻傻分不清楚。
介绍一下V8
V8 是由谷歌收购并使用C++开发并开源的javascript虚拟机引擎,运用于Chrome浏览器,还有我们熟知的node,所以我们写的 JavaScript 应用,大都跑在 V8 上。
| 浏览器 | 引擎 | Firefox | SpiderMonkey | Safari | JavascriptCore | IE、Edge | Chakra |
|---|
V8底层
V8运行环境
因为 V8 并不是一个完整的系统,所以宿主和V8共用同一套内存空间,在执行时,它要依赖于由宿主提供的基础环境(类似于寄生关系),大致包含了我们熟悉的全局执行上下文、事件循环系统、堆栈空间、宿主环境特殊定制的API等。除了需要宿主提供的一些基础环境之外,V8 自身会使用创建好的堆和栈并提供 JavaScript 的核心功能(Object、Function、String)以及垃圾回收(GC)。
流程: 宿主启动主进程(浏览器渲染进程、node进程) -> 宿主初始化并启动V8
V8执行代码
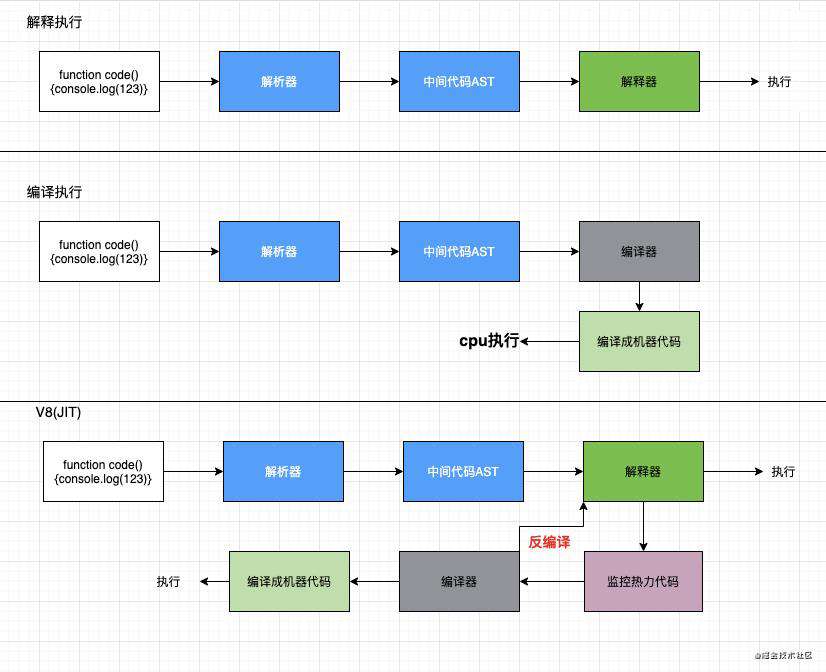
解释执行:需要先将输入的源代码通过解析器编译成中间代码,之后直接使用解释器解释执行中间代码,然后直接输出结果。
代码 → 解析器转码中间代码AST → 解释器 -> 执行
编译执行:先将源代码转换为中间代码,然后我们的编译器再将中间代码编译成机器代码。
代码 → 解析器转码中间代码AST → 编译器 → 二进制机器码 -> 执行
Tips: 机器代码是以二进制文件形式存储的,还可将机器代码保存在内存中并直接执行内存中的二进制代码。
| 类型 | 启动速度 | 执行速度 | 解释执行 | 快 | 慢 | 编译执行 | 慢 | 快 |
|---|
即时编译(Just-in-time compilation):长话短说,先走解释执行,在解释器对代码进行监控,对重复执行频率高的代码打上tag,成为可优化的热点代码,之后流向编译执行的模式,对可优化的代码进行一个编译转成二进制机器码并存储,之后就地复用二进制码减少解释器和机器的压力再执行。
代码 → 解析器转码中间代码AST → 解释器 → 执行
↓ ↑ 反编译
监控热力代码 → 编译器 → 二进制机器码 → 执行
function add(a, b) {
return a + b;
}
for(let i=0;i<100;i++){
// 结构稳定类型稳定,打tag走编译执行二进制入内存优化
add(250, 520);
}
// 我曹,吃了动态类型的亏啊,返回给解释器,我不接这个锅
add(250, '520');
Tips:Java因为是静态/强类型所以在JIT优化上会与JS(动态/弱类型)有所区别,也在转为机器代码之后更稳定,效率有更多提升。
字节码、解释器、编译器
V8 JIT最为核心的因素!

上图中的中间代码AST即为字节码。
为什么要用字节码呢?

怎么做的呢?
-
字节码允许被解释器直接执行。
-
热力代码被优化,从字节码编译成二进制代码执行(字节码与二进制码的执行过程接近,所以编译能提效)。
-
因为移动端兴起,所以采用了比二进制占用空间小的字节码,这样可以被浏览器缓存(内存),被机器缓存(硬盘)。
-
字节码被解释器编译的速度更快增加了启动速度,同时直接执行只不过执行速度比机器代码慢。
-
不同cpu处理器因平台不同所以机器代码不同,字节码与机器代码执行流程接近因此降低了编译器将字节码转换机器代码的时间。
V8优化
V8变量提升(面试)
console.log(yyz)
var yyz = 'handsomeBoy'
打印:undefined
这个东西太常见了,变量提升嘛
但是,面试官问你是什么原因造成的呢?
首先我们要区分什么是表达式什么是语句。
var yyz = 'handsomeBoy' 中等号左边是表达式,右边是语句。
表达式:var yyz = undefined 是表示值的式子
语句:yyz = 'handsomeBoy'是操作值的式子
上面代码在编译阶段是这么处理的:
————————————————————————————————————————— 编译阶段
var yyz = undefined // 被提升
————————————————————————————————————————— 执行阶段
console.log(yyz) //打印:undefined
yyz = 'handsomeBoy'
调整顺序即可达到目的:
var yyz = 'handsomeBoy'
console.log(yyz)
————————————————————————————————————————— 编译阶段
var yyz = undefined // 被提升
————————————————————————————————————————— 执行阶段
yyz = 'handsomeBoy'
console.log(yyz)
打印:handsomeBoy
V8函数
函数表达式和声明式
首先了解函数表达式和函数声明式
// 函数表达式
handsomeBoy();
var handsomeBoy = function(){
console.log(`yyz is 18 years old`);
}
打印:VM1959:1 Uncaught TypeError: handsomeBoy is not a function
at <anonymous>:1:1
聪明的你一定能发现可以和上面的内容串起来。
函数表达式也是声明表达式,被变量提升,然后赋值为undeinfed, 所以执行阶段handsomeBoy()当做函数执行会报错。
// 函数声明式
handsomeBoy();
function handsomeBoy(){
console.log(`yyz is 18 years old`);
}
打印:`yyz is 18 years old`
// 编译阶段
function handsomeBoy(){
console.log(`yyz is 18 years old`);
}
handsomeBoy();
还有一个矛盾点:函数声明不是一个表达式,而是一个语句,之前不是说语句只有在执行阶段才触发吗,那岂不是没有被提升?
惰性解析、闭包(面试)
起因:函数代码内容较多解析和编译时间较长、缓存内存占用量大,因此V8进行了惰性解析的优化。
经过:
function handsomeBoy(name,age) {
console.log(`${name} is ${age} years old`);
}
handsomeBoy('yyz', 18)
V8 在解析阶段只会把函数对象分成俩块内容,name和code
// handsomeBoy Function Object
{
name: handsomeBoy,
code: `console.log(${name} is ${age} years old)`,
}
结果: 解析器在解析中如果遇到了函数声明式,会忽略内部代码code,直接解析并编译顶层函数字节码。而在执行函数时会通过handsomeBoy函数对象,解析编译内部的code内容(你可以理解为执行时期异步编译具体函数内部代码)。
当然也有特殊情况:
- 闭包(函数内部嵌套函数,同时允许查找函数外部变量作用域)。
- 函数语法错误(错误的函数语法没必要再进行惰性解析)
此时预解析器就登场了,主要作用当然是为了解决上面的问题,先对上面的code进行一个粗略的预解析:
- 遇到语法错误就抛出。
- 遇到闭包会把外部变量从栈复制到堆中,下次直接使用堆中引用(以防执行先后顺序导致闭包引用的变量已经出栈被回收)
在聊闭包的时候可以尝试从这个角度去说明。
栈溢出(面试)
function fac(n) {
if (n === 1) return 1;
return n * fac(n - 1);
}
fac(5) // 120
栈是内存中连续的一块存储空间,主要负责函数调用,先进后出(FILO)的结构。
V8对栈空间进行了大小限制,所以会有栈溢出报错
VM68:1 Uncaught RangeError: Maximum call stack size exceeded
如果 V8 使用不当,比如不规范的代码触发了频繁的垃圾回收,或者某个函数执行时间过久,这些都会占用宿主环境的主线程,从而影响到程序的执行效率,甚至导致宿主环境的卡死。
为了解决栈溢出的问题,我们可以使用异步队列中的宏微任务,例如setTimeout将要执行的函数放到其他的任务中去执行,也可以使用 Promise 来改变栈的调用方式,主要还是因为异步队列来是区别与同步调用栈的执行顺序。当然如果采用了微任务递归调用会导致页面不报错缺类似于卡死的状态,因为需要将微任务全部执行完毕,所以页面上的I/O,用户操作都会排队,等微任务执行完。
最可靠的方案是尾递归优化用来删除调用栈外层无用的调用桢,只保留内层函数的调用桢,来节省浏览器的内存。即在递归的最后返回一个纯函数,因为如果是一个表达式或语句将不会弹出调用栈。
function fac(n, total) {
if (n === 1) return total;
return fac(n - 1, n * total);
}
fac(5, 1) // 120
Tips:
- 如果要使用外层函数的变量,可以通过参数的形式传到内层函数中
- 尾调用优化只在严格模式下开启,非严格模式是无效的。
- 如果环境不支持“尾调用优化”,代码还可以正常运行,是无害的
V8对象属性访问(面试)
请说出顺序
function yyz(){
this['A']='A'
this[0]='2'
this['1']=3
this[2]='4'
this['handsome']=5
this[7.7]=7.7
this[888]='6'
this['B']='B'
};
const handsomeBoy = new yyz()
for (let key in handsomeBoy) {
console.log(`${key}:${handsomeBoy[key]}`);
};
打印(谷歌V8)
0:2
1:3
2:4
888:6
A:A
-1:1
handsome:5
7.7:7.7
B:8
why?为什么不按顺序来?
从浏览器的Memory中搜索yyz这个对象
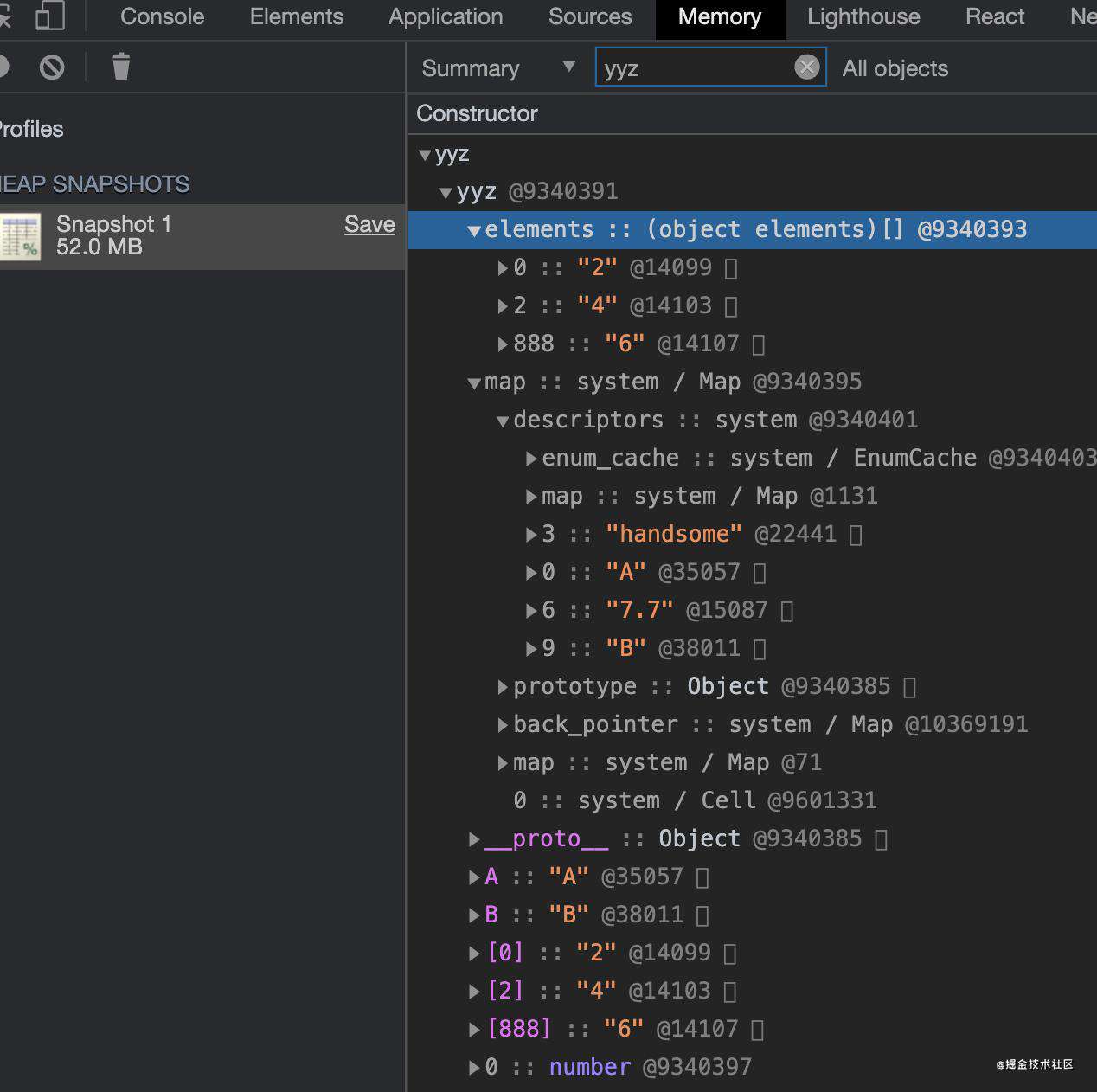
在V8的对象中有分俩种属性,排序属性以(elements)及常规属性(properties),数字被分类为排序属性,字符串属性就被称为常规属性,其中排序属性按照数字大小升序而常规属性按照创建升序,执行顺序也是先查elements再查找properties。
ps.图中对象内属性没拉满(达到上限)所以没有properties,下文会说
对象内属性
function yyz() {}
var yyz1 = new yyz()
var yyz2 = new yyz()
var yyz3 = new yyz()
for (var i = 0; i < 10; i ++) {
yyz1[new Array(i+2).join('a')] = 'aaa'
}
for (var i = 0; i < 12; i ++) {
yyz2[new Array(i+2).join('b')] = 'bbb'
}
for (var i = 0; i < 30; i ++) {
yyz3[new Array(i+2).join('c')] = 'ccc'
}
但是每次查找某个属性的时候都需要多查找一次,yyz->properties->a,感觉很麻烦于是对象内属性就诞生了。
小于10个
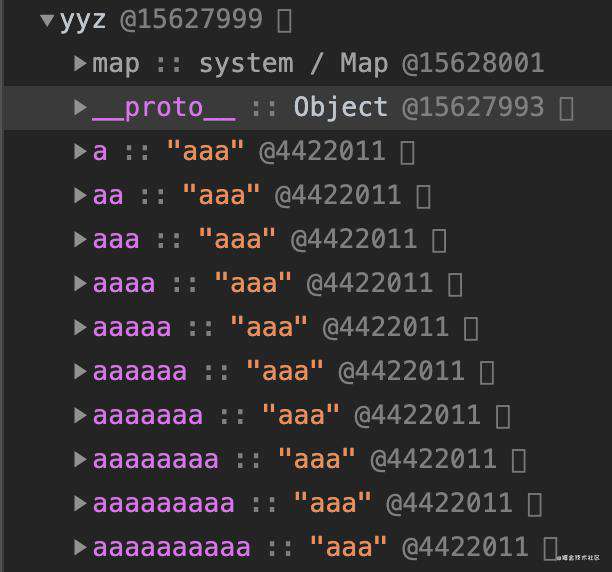
如图,并没有properties属性 而是直接保存在对象内的,为了减少查找这些属性查找流程,在对象内直接生成映射,快速查找,但是最多10个。
大于10个
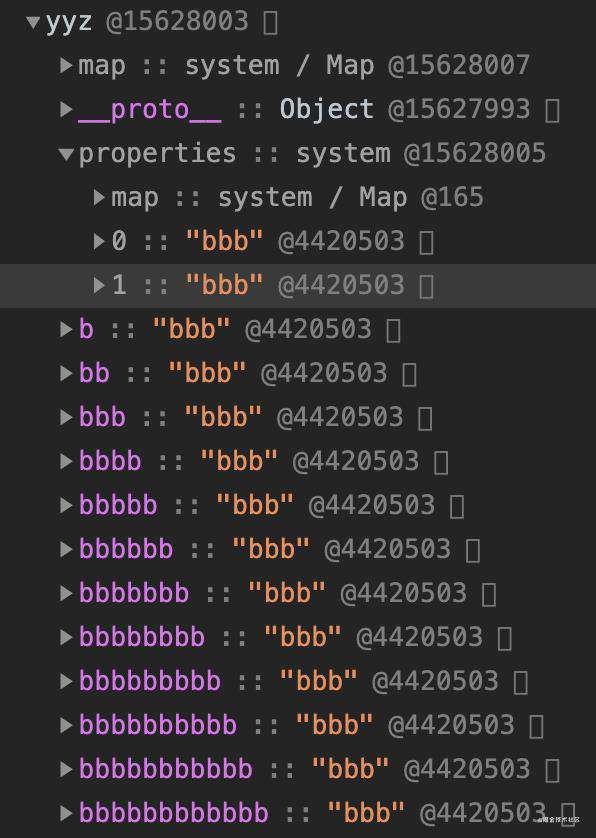
如图,当对象内属性放满之后,会以快属性的方式,在 properties 下按创建顺序存放(0、1)。相较于对象内属性,快属性需要额外多一次 properties 的寻址时间,之后便是与对象内属性一致的线性查找(properties的属性是有规律的类似数组、链表存放)。
大于20个
快、慢属性
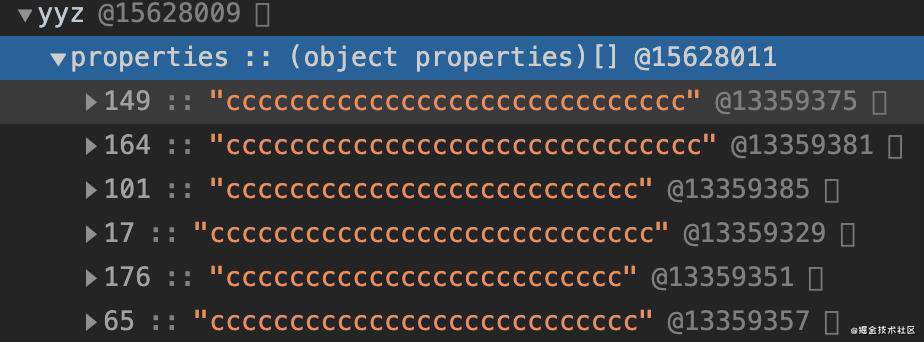
当我们数据量大起来以后,在properties里的属性已经不线性(149、164),此时已经使用了散列表(哈希-分离链路)来存储。
V8采用了俩种结构来处理数据量大小的问题
| 结构 | 数据类型 | 执行速度 | 线性结构 | 数组、链表 | 快 | 非线性解构 | 哈希Map(分离链路) | 慢 |
|---|
分离链路是哈希key+链表value的结构,就不具体展开了可以自行搜索。
为什么不直接用快属性?
总结:
- 排序顺序数字按大小排序->字符串按先后执行顺序排序
- 数字存储在排序属性字符串存储在常规属性->10个及10个以内会在内部生成属性-> 大于十个在properties里线性存储 -> 数量大的情况改为散列表存储
GC(面试)
关于辣鸡变量回收GC,可以看我司这位小姐姐的文章,非常详细点我
隐藏类
我们先来看一下TS中的interface。
interface Post {
name : string
content: string
}
interface定义了数据结构和包含的属性。
如上面,Java、C++ 这样的静态语言,类型一旦创建变不可更改,属性可以通过固定的偏移量进行访问,而V8为了优化属性的查找创建了隐藏类不仅提升存取速度还节省了空间。
const post = {
name:'yyz',
content:'handsome'
}
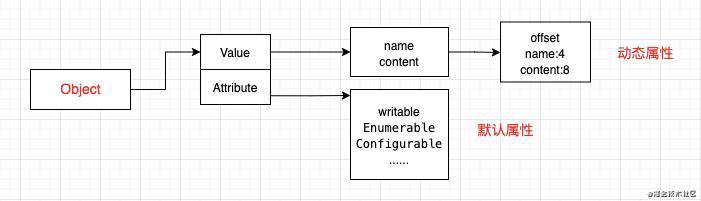
我们创建对象的时候隐藏类会存储属性在内存空间的偏移量,如上图的offset,访问post.name会直接通过隐藏类的偏移量查找属性。
复用对象的Attribute,每次新增、删除一个属性就会创建新的隐藏类。
当读取到post.content属性的时候会创建新的隐藏类其中包含了name、content俩个属性,而其中的name属性指针指向之前创建好的post.name的隐藏类引用(类似于堆的指针引用),用漂移减少了重新创建的开销。
const post = {
}
post.name = 'yyz'
post.content = 'handsome'
这段代码先创建空对象再赋值与上文直接创建含属性的对象虽然结果相同,但是隐藏类地址是不一样的,是因为第一步是单独创建空对象这一步。
因此在同一个隐藏类的两次成功的调用之后,V8 省略了隐藏类的查找,并简单地将该属性的偏移量添加到对象指针本身。对于该方法的所有下一次调用,V8 引擎都假定隐藏的类没有更改,并使用从以前的查找存储的偏移量直接跳转到特定属性的内存地址。这大大提高了执行速度。
内联缓存
gzip和http2是怎么进行压缩的?
说白了就是复用重复内容,拼装不重复内容。
V8对于对象读写也进行了缓存。
例子:对于post.name这个语句如果在一个循环中执行(一定规律执行多次),V8还会继续做优化,针对这个动作语句(代码)存储偏移量,缩短对象属性的查找路径,从而提升执行效率。
删除属性
delete post.name
删除对象中的属性容易导致稀疏索引退化成哈希存储,说人话就是会造成负优化,从快属性变成了慢属性。
极致优化对象写方法
- 保证相同顺序相同属性赋值
const post1={
name:'yyz',
content:'handsome'
}
const post2={
content:'handsome',
name:'yyz'
}
-
如上面的post案例,避免空对象,尽量一次性初始化属性
-
减少delete
结语
V8内容远不止这些,例如Array.sort在数组长度上采用了不同排序算法的优化(小于10插排,大于10快排),研究这些相对生僻的内容对于提升自身能力有很大的帮助,在梳理底层的过程中不仅对底层有了更深的认识同时对于一些面试八股文有了新的见解,希望阅读完本文能够帮助你打开视野。
看完别忘记对我素质四连,点赞、关注、转发、评论

推荐阅读
- 高性能 JavaScript 引擎 V8 - 垃圾回收

常见问题FAQ
- 免费下载或者VIP会员专享资源能否直接商用?
- 本站所有资源版权均属于原作者所有,这里所提供资源均只能用于参考学习用,请勿直接商用。若由于商用引起版权纠纷,一切责任均由使用者承担。更多说明请参考 VIP介绍。
- 提示下载完但解压或打开不了?
- 找不到素材资源介绍文章里的示例图片?
- 模板不会安装或需要功能定制以及二次开发?





发表评论
还没有评论,快来抢沙发吧!