在 node 中可以通过 v8.getHeapSnapshot 来获取应用当前的堆快照信息,该调用会生成一份 .heapsnapshot 文件,官方并没有对该文件的内容有一个详细的解释,本文将主要对该文件内容进行解析,并演示了一个了解文件内容后可以做的有趣的事情
v8.getHeapSnapshot
首先简单回顾下 v8.getHeapSnapshot 是如何使用的:
// test.js
const { writeHeapSnapshot } = require("v8");
class HugeObj {
constructor() {
this.hugeData = Buffer.alloc((1 << 20) * 50, 0);
}
}
// 注意下面的用法在实际应用中通常是 anti-pattern,
// 这里只是为了方便演示,才将对象挂到 module 上以防止被 GC 释放
module.exports.data = new HugeObj();
writeHeapSnapshot();
将上面的代码保存到 test.js 中,然后运行 node test.js,会生成文件名类似 Heap.20210228.154141.9320.0.001.heapsnapshot 的文件,该文件可以使用 Chrome Dev Tools 进行查看
当我们将 .heapsnapshot 文件导入到 Chrome Dev Tools 之后,我们会看到类似下面的内容:
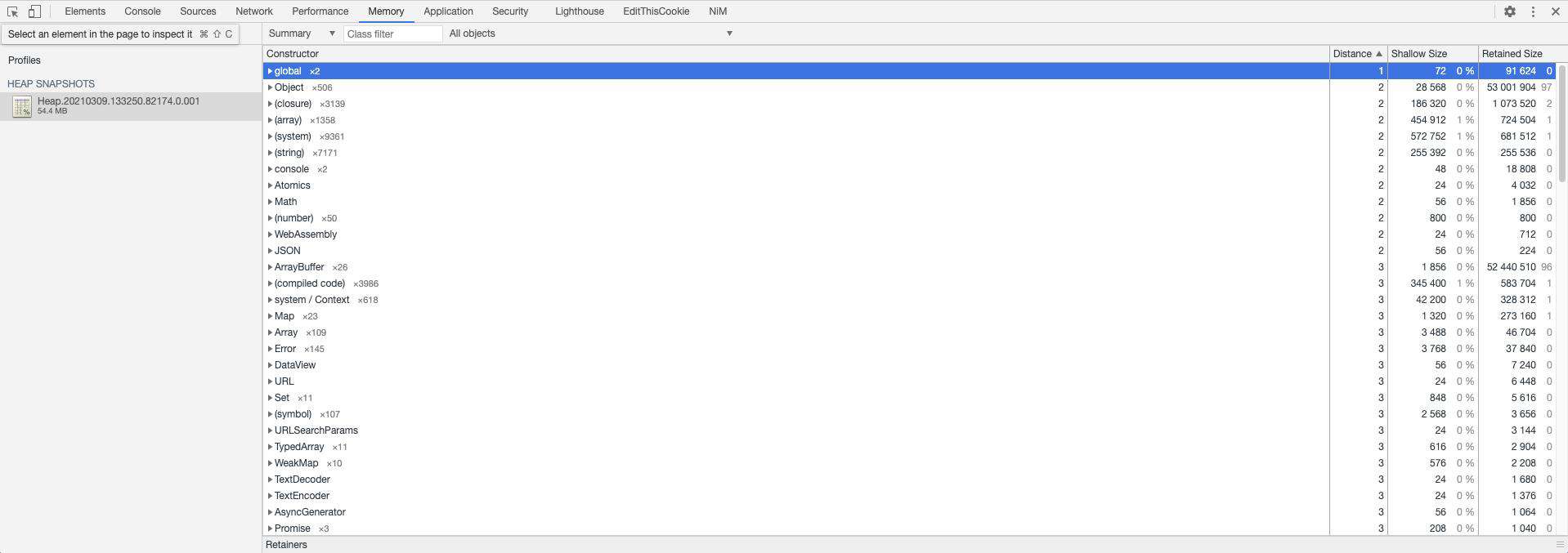
上图表格列出了当前堆中的所有对象,其中列的含义是:
-
Constructor,表示对象是使用该函数构造而来
-
Constructor 对应的实例的数量,在 Constructor 后面的
x2中显示 -
Shallow size,对象自身大小(单位是 Byte),比如上面的
HugeObj,它的实例的 Shallow size 就是自身占用的内存大小,比如,对象内部为了维护属性和值的对应关系所占用的内存,并不包含持有对象的大小比如
hugeData属性引用的Buffer对象的大小,并不会计算在HugeObj实例的 Shallow size 中 -
Retained size,对象自身大小加上它依赖链路上的所有对象的自身大小(Shallow size)之和
-
Distance,表示从根节点(Roots)到达该对象经过的最短路径的长度
heapsnapshot 文件
Chrome Dev Tools 只是 .heapsnapshot 文件的一种展现形式,如果我们希望最大程度利用这些信息,则需要进一步了解其文件格式
我们可以使用任意的文本编辑器打开该文件,可以发现文件内容其实是 JSON 格式的:
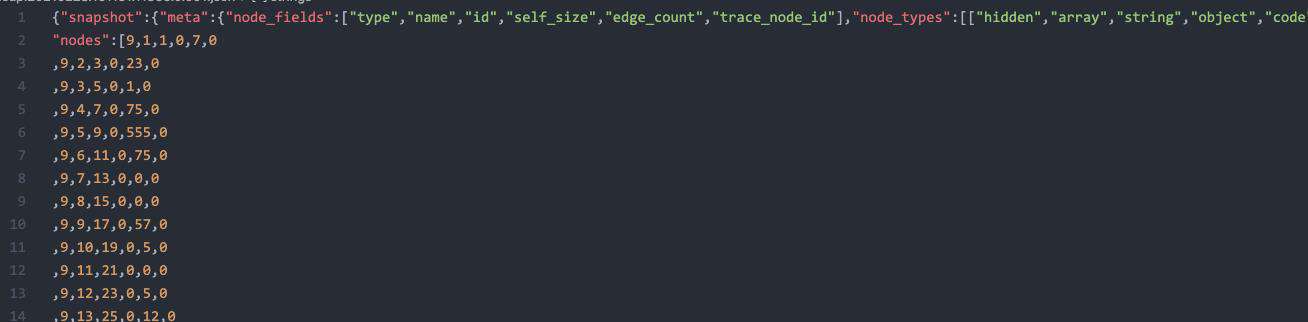
因为目前没有具体的说明文档,后面的内容我们将结合源码来分析该文件的内容
文件内容概览
在原始输出的文件内容中,可以发现 snapshot 字段部分是去除空白的,而 nodes 和 edges 字段的内容都是有换行分隔的,整体文件有非常多的行数
为了方便理解,我们可以将节点折叠,这样可以看出该文件的整体内容:
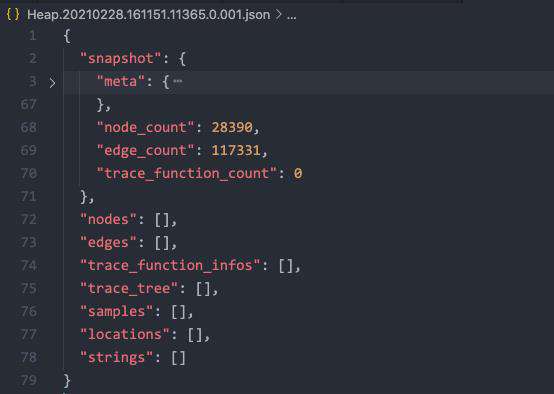
随后我们在源码中,以该 v8.getHeapSnapshot 的 binding 着手,定位到该文件内容是方法 HeapSnapshotGenerator::GenerateSnapshot 的运行结果
并且我们知道对象在内存中的拓扑形式需要使用 Graph 数据结构 来表示,因此输出文件中有 nodes 和 edges 字段分别用于表示堆中的对象,以及对象间的连接关系:
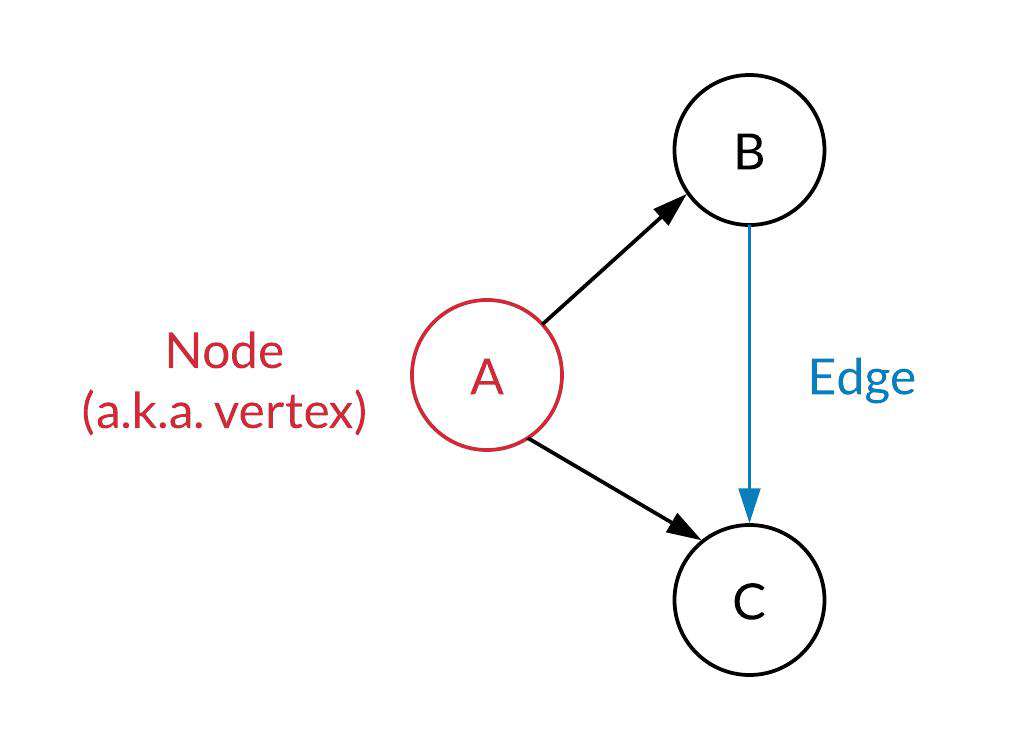
](guides.codepath.com/compsci/Gra…)
不过 nodes 和 edges 中并没有直接存储对象的信息,而都是一连串数字,我们需要进一步分析其中的内容
nodes
nodes 中的每一个 Node 的序列化方法是:HeapSnapshotJSONSerializer::SerializeNode
从源码来看,每输出完 node 的所有属性值后,会跟着输出 \n\0,这也是输出结果中 nodes 数组是一行行数字的原因。不过我们知道 \n\0 在 JSON 反序列化的时候因为会因为自身符合空白的定义而被忽略掉,所以这样的换行可以理解是为了方便直接查看源文件
我们来看一个例子,比如:
{
"nodes":[9,1,1,0,10,0 // 第一行
,9,2,3,0,23,0 // 第二行
}
上面的内容,每行分别表示一个 node,每一行都是对象的属性的 value(我们先不用考虑为什么 value 都是数值)。而属性的 name 我们通过源码中输出的顺序可以整理出来:
0. type
1. name
2. id
3. self_size
4. edge_count
5. trace_node_id
因为 value 的输出顺序和上面的 name 是对应的,所以我们可以根据属性 name 的顺序作为索引,去关联其 value 的值
不过实际上并不能省略属性名称列表的输出,因为属性的内容是可能在后续的 node 版本中变化的(主要是跟随 v8 的变化),为了和对应的数据消费端解耦,文件中会将属性 name 列出输出,保存在 snapshot.meta.node_fields 中
Field Type
接下来我们来看为什么 nodes 数组保存的属性 value 都是数值
还是上面的例子,因为我们已经知道了,属性名称和属性值是按索引顺序对应上的,那么对于上面第一个 node 的 propertyName(propertyValue) 列表可以表示为:
0. type(9)
1. name(1)
2. id(1)
3. self_size(0)
4. edge_count(10)
5. trace_node_id(0)
比如第 1 号属性 name,它就是对象的名称,不过根据对象的类型不同,该值也会有不同的取值方式。比如对于一般对象而言,它的内容就是其构造函数的名称,对于 Regexp 对象而言,它的值就是 pattern 字符串,更多得可以参考 V8HeapExplorer::AddEntry
假如我们直接保存属性的值,那么如果堆中有 1000 个由 HugeObj 构造的对象,HugeObj 字符串就要保存 1000 个拷贝
因为 heapdump 顾名思义,输出大小几乎就和当前 Node 应用所占内存大小一致(并不完全一致,这里 heapdump 只包含受 GC 管理的内容),为了让输出的结果尽可能的紧凑,v8 在输出属性值的时候,按一定的规则进行了压缩,压缩的秘诀是:
-
增加一条记录
snapshot.meta.node_types,来存放属性的类型,和snapshot.meta.node_fields类似,它们和属性值之间也是通过索引(顺序)关联的 -
nodes中只存放属性值,我们需要计算一下偏移量(下面会讲到),来确定属性的类型:- 如果是数值类型,那么该值就是本身的内容
- 如果是数组,则 value 对应数组中的索引
- 如果是字符串,则 value 对应
strings数组的内容
我们可以用下面的图来表示三者之间的关系:
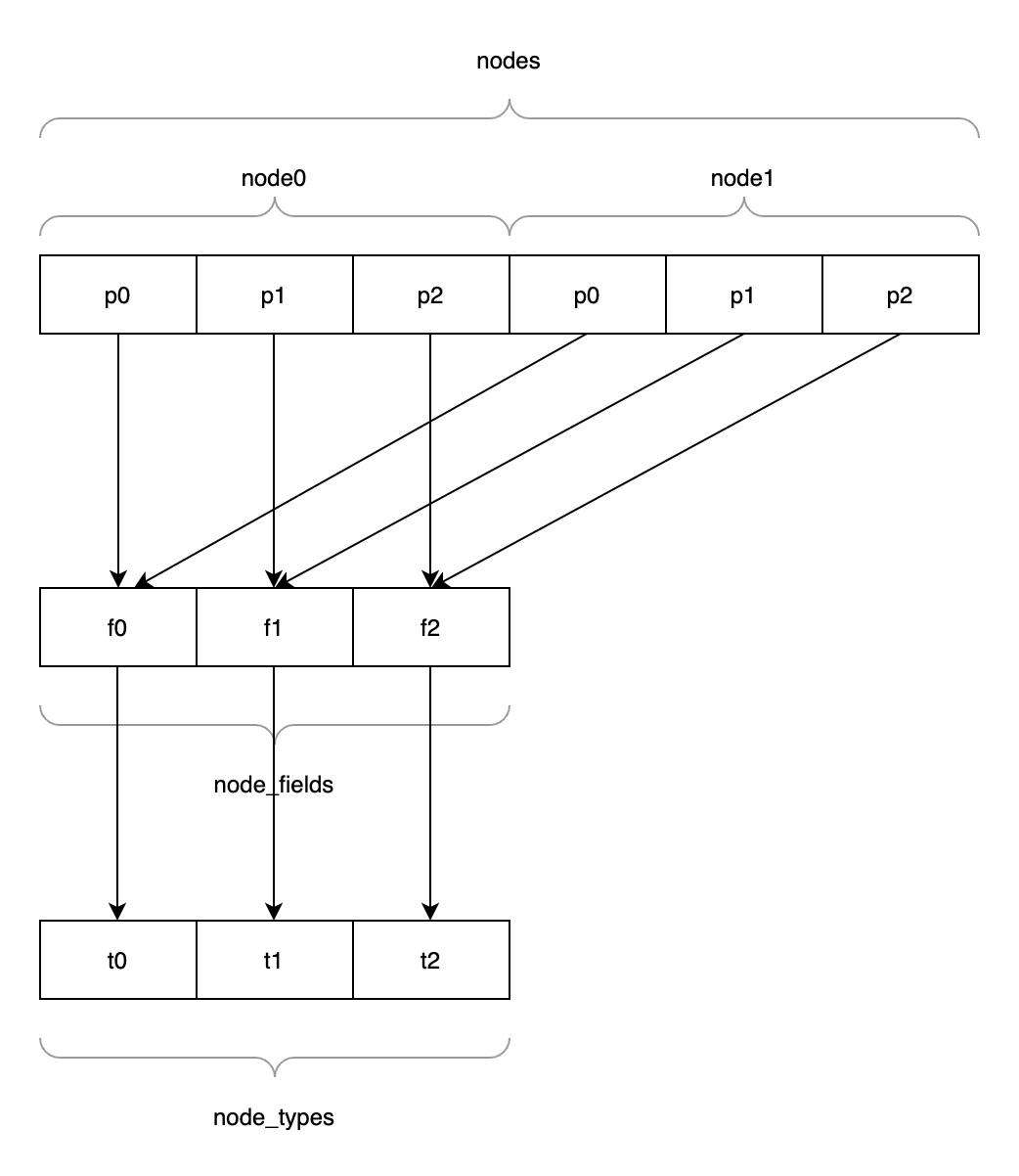
我们通过一个例子来串联上面的内容。比如我们要看索引为 1000 的对象(注意区别 id 属性)的 name 属性的值,使用下面的方式:
- 取
name属性在snapshot.meta.node_fields中的索引为1 - 取
snapshot.meta.node_fields数组的长度为6 - 则索引为 1000 的对象的起始索引为:
1000 * 6(因为对象属性的数量是固定的) - 加上
name属性的偏移量1,则name在nodes数组中的索引为6001 = 1000 * 6 + 1 - 取
name属性在snapshot.meta.node_types中的类型,即snapshot.meta.node_types[1],在这个例子中是string - 则
strings[6001]的内容就是name属性值的最终内容
其余一些字段的含义是:
- id,对象的 id,v8 会确保该对象在本次应用生命周期中的多次的 dump 下中保持相同的 id
- self_size,也就是上文提到的 shallow size
- edge_count,就是从该对象出去的边的条数,也就是子对象的数量
- trace_node_id,可以暂时不去考虑,只有在同时使用
node --track-heap-objects启动应用的情况下,该内容才不会为0。它可以结合trace_tree和trace_function_infos一起知道对象是在什么调用栈下被创建的,换句话说就是知道经过一系列什么调用创了该对象。文本不会讨论这部分内容,或许会在以后的章节中展开
edges
edges 中的 Edge 的序列化方式是:HeapSnapshotJSONSerializer::SerializeEdge
字段内容分别是:
0. type
1. edge_name_or_index(idx or stringId)
2. to
和上面的 nodes 数组类似,edges 数组也是都存的属性的值,因此在取最终值的时候,需要结合 snapshot.meta.edge_fields snapshot.meta.edge_types 来操作
唯一的问题在于,我们知道 Edge 表示的对象之间的关系,而且这里是有向图,那么一定有 From 和 To 两个字段,而上面的字段内容只有 To,那么 nodes 和 edges 是如何对应的呢?
Node 和 Edge 的对应关系
从头以 HeapSnapshotGenerator::GenerateSnapshot 方法开始分析,看看 nodes 和 edges 是如何产生的,下面是该方法中的相关主要内容:
bool HeapSnapshotGenerator::GenerateSnapshot() {
// ...
// 加入 Root 节点,作为活动对象的起点
snapshot_->AddSyntheticRootEntries();
// 即 HeapSnapshotGenerator::FillReferences 方法,nodes 和 edges
// 都是由该方法构建的,这里的 nodes 和 edges 指的是 HeapSnapshot 的
// 数据成员 `entries_` 和 `edges_`
if (!FillReferences()) return false;
// 输出文件中的 edges 实际是通过 `FillChildren` 重新组织顺序的,
// 重新组织后的内容保存在 HeapSnapshot 的数据成员 children_ 中
snapshot_->FillChildren();
snapshot_->RememberLastJSObjectId();
progress_counter_ = progress_total_;
if (!ProgressReport(true)) return false;
// ...
}
可以暂时不去深入了解 Node 和 Edge 是如何生成的,看一下 HeapSnapshot::FillChildren 方法是如何重新组织输出的 edges 内容的:
void HeapSnapshot::FillChildren() {
// ...
int children_index = 0;
for (HeapEntry& entry : entries()) {
children_index = entry.set_children_index(children_index);
}
// ...
children().resize(edges().size());
for (HeapGraphEdge& edge : edges()) {
edge.from()->add_child(&edge);
}
}
其中 entry.set_children_index 和 edge.from()->add_child 方法内容分别是:
int HeapEntry::set_children_index(int index) {
// Note: children_count_ and children_end_index_ are parts of a union.
int next_index = index + children_count_;
children_end_index_ = index;
return next_index;
}
void HeapEntry::add_child(HeapGraphEdge* edge) {
snapshot_->children()[children_end_index_++] = edge;
}
所以对于每个 entry(即 node)都有一个属性 children_index,它表示 entry 的 children 在 children_ 数组中的起始索引(上面注释中已经提到,heapsnapshot 文件中的 edges 数组的内容就是根据 children_ 数组输出的)
综合来看,edges 数组的内容和 nodes 之间的对应关系大致是:
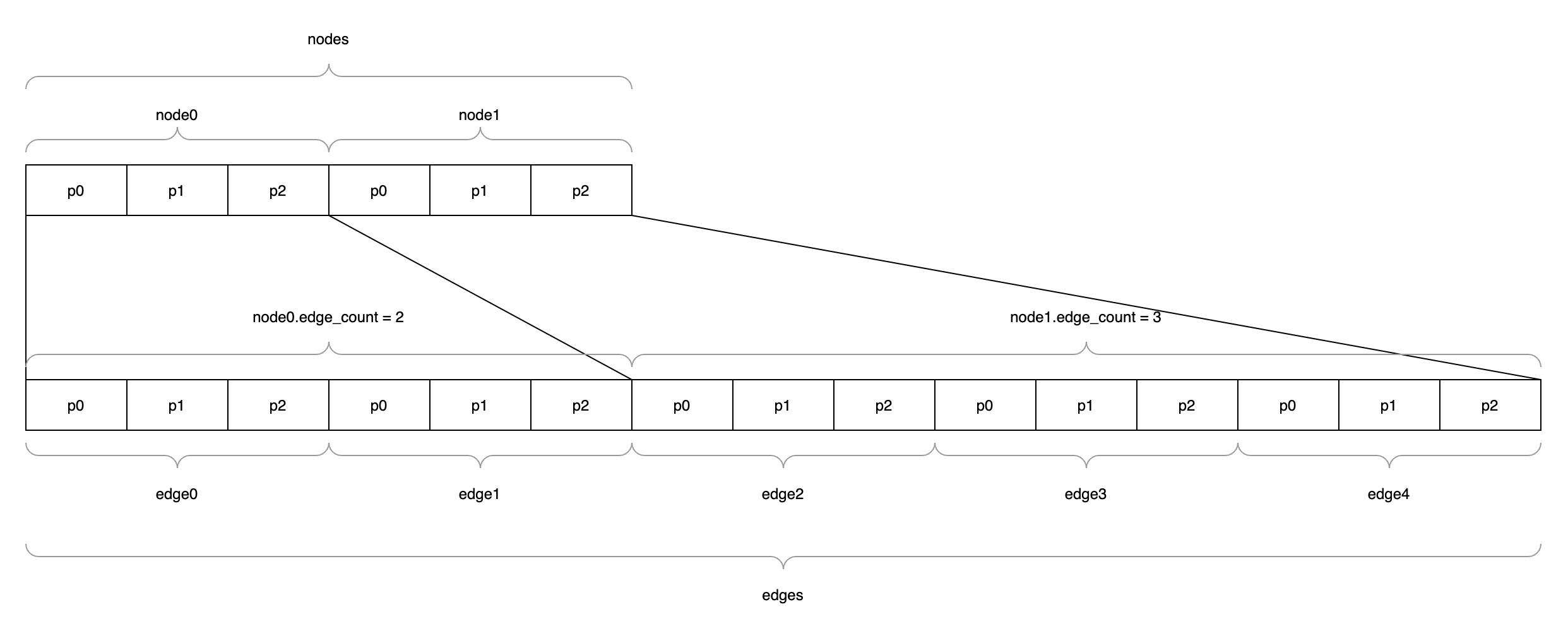
比如上面 edge0 的 From 就是 nodes[0 + 2],其中:
nodes表示 nodes 数组0的位置表示该 node 在nodes数组中的索引,这里也就是第一个元素2表示id属性在snapshot.meta.node_fields数组中的偏移量
node0 的 edge_count 可以表示成 nodes[0 + 4]:
- 其中
4表示edge_count属性在snapshot.meta.node_fields数组中的偏移量 - 其他部分同上
所以 edges 数组中,从 0 开始的 node0.edge_count 个 edge 的 From 都是 node0.id
因为 node[n].edge_count 是变量,所以我们无法快速根据索引定位到某个 edge 的 From,我们必须从索引 0 开始,然后步进 node[n].edge_count 次(n 从 0 开始),步进次数内的 edge 的 From 都为 node[n].id,步进结束后对 n = n + 1 ,进而在下一次迭代中关联下一个 node 的 edges
heapquery
我们开头说了解文件内容可以做一些有趣的事情,接下来我们将演示一个小程序 heapquery(Rust 劝入版),它可以将 .heapsnapshot 文件的内容导入到 sqlite 中,然后我们就可以通过 SQL 来查询自己感兴趣的内容了(虽然远没有 osquery 高级,但是直接通过 SQL 来查询堆上的内容,想想都会很有趣吧)
除此以外,它还可以:
- 验证上文对 heapsnapshot 文件格式的分析
- 对上文的文字描述提供一个可运行的代码的补充解释
因为 heapquery 的程序内容非常简单(仅仅是解析格式并导入而已),所以就不赘述了。只简单看一下涉及的表结构,因为仅仅是演示用,到最后其实只有两张表:
Node 表
CREATE TABLE IF NOT EXISTS node (
id INTEGER PRIMARY KEY, /* 对象 id */
name VARCHAR(50), /* 对象所属类型名称 */
type VARCHAR(50), /* 对象所属类型枚举,取自 `snapshot.meta.node_types` */
self_size INTEGER, /* 对象自身大小 */
edge_count INTEGER, /* 对象持有的子对象数量 */
trace_node_id INTEGER
);
Edge 表
CREATE TABLE IF NOT EXISTS edge (
from_node INTEGER, /* 父对象 id */
to_node INTEGER, /* 子对象 id */
type VARCHAR(50), /* 关系类型,取自 `snapshot.meta.edge_types` */
name_or_index VARCHAR(50) /* 关系名称,属性名称或者索引 */
);
小演练
在本文开头的位置,我们定义了一个 HugeObj 类,在实例化该类的时候,会创建一个大小为 50M 的 Buffer 对象,并关联到其属性 hugeData 上
接下来我们将进行一个小演练,假设我们事先并不知道 HugeObj,我们如何通过可能的内存异常现象反推定位到它
首先我们需要将 .heapsnapshot 导入到 sqlite 中:
npx heapquery path_to_your_heapdump.heapsnapshot
命令运行完成后,会在当前目录下生成 path_to_your_heapdump.db 文件,我们可以选择自己喜欢的 sqlite browser 打开它,比如这里使用的 DB Browser for SQLite
然后我们执行一条 SQL 语句,将 node 按 self_size 倒序排列后输出:
SELECT * FROM node ORDER By self_size DESC
我们会得到类似下面的结果:
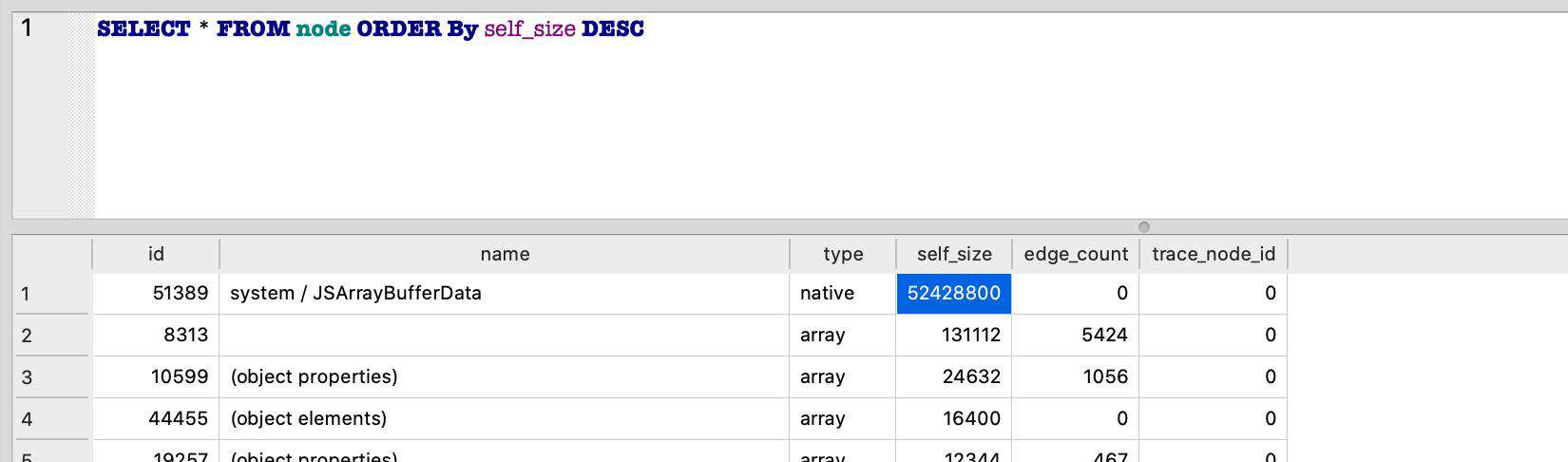
我们接着从大小可疑的对象入手,当然这里就是先看截图中 id 为 51389 的这条数据了
接下来我们再执行一条 SQL 语句,看看是哪个对象持有了对象 51389
SELECT from_node, B.name AS from_node_name
FROM edge AS A
JOIN node AS B ON A.from_node = B.id
WHERE A.to_node = 51389
我们会得到类似下面的输出:
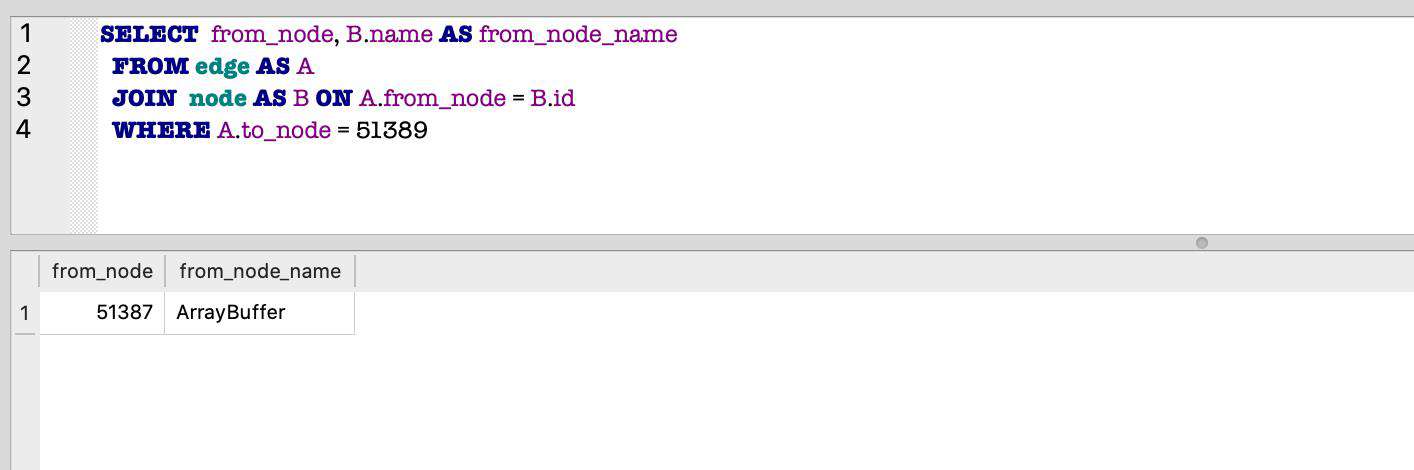
上面的输出中,我们知道持有 51389 的对象是 51387,并且该对象的类型是 ArrayBuffer
因为 ArrayBuffer 是环境内置的类,我们并不能看出什么问题,因此需要利用上面的 SQL,继续查看 51387 是被哪个对象持有的:
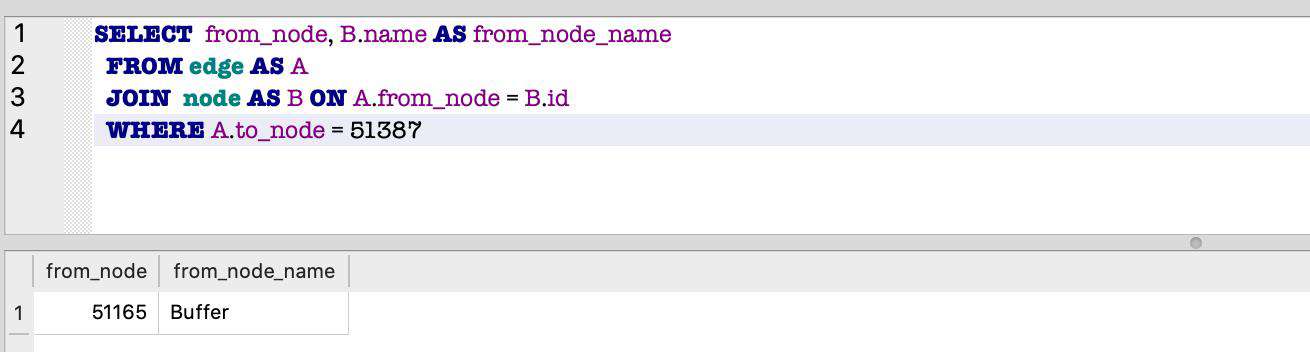
和上面的输出类似,这次的 Buffer 依然是内置对象,所以我们继续重复上面的步骤:
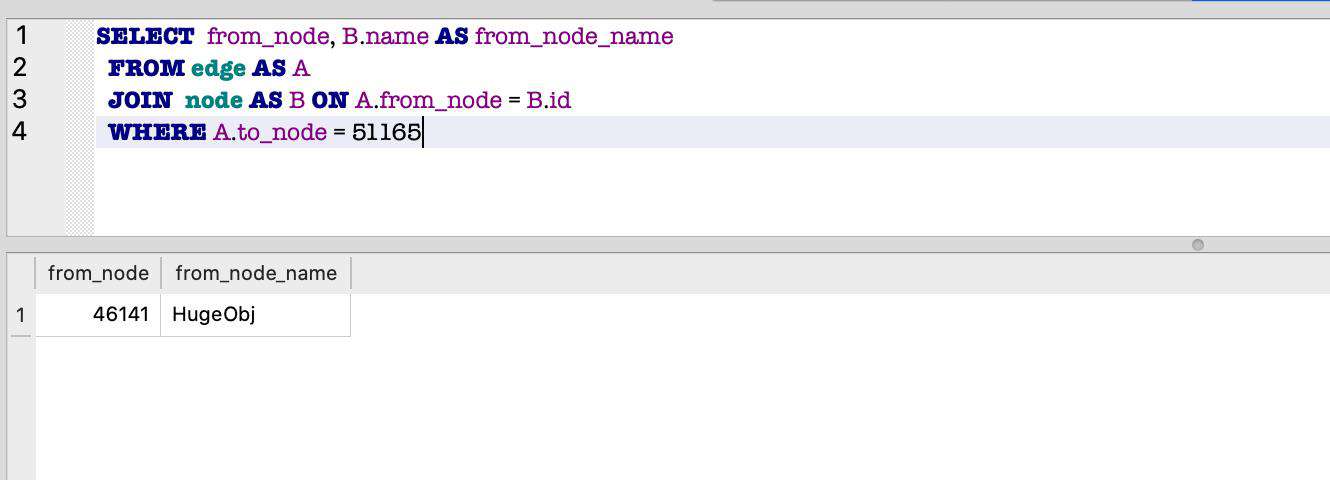
这次我们得到了一个业务对象 HugeObj,我们看看它是在哪里定义的。对象的定义就是它的构造函数,因此我们需要找到它的 constructor,为此我们先列出对象的所有属性:
SELECT * FROM edge WHERE from_node = 46141 AND `type` = "property"
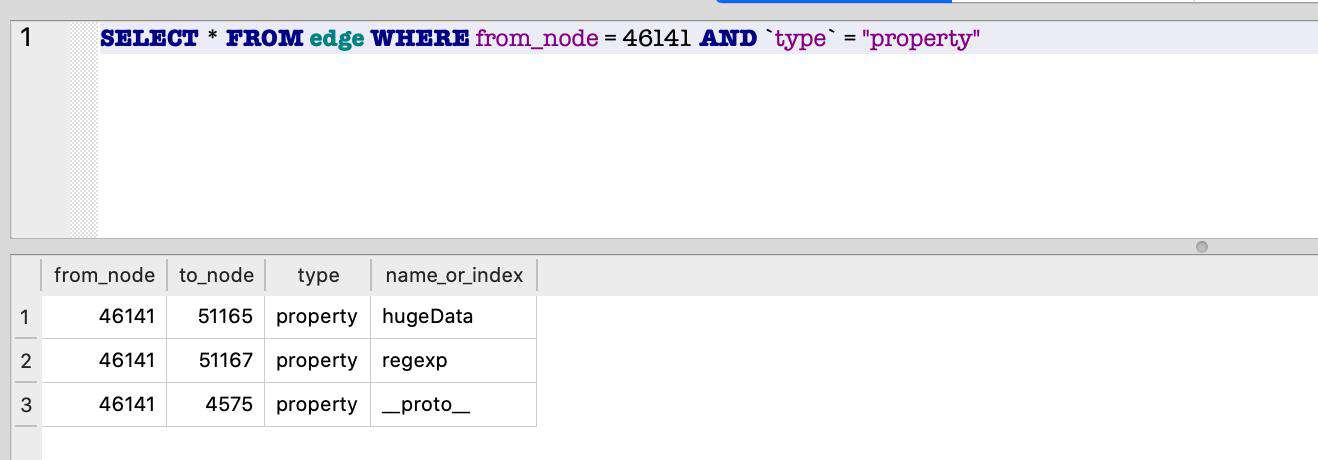
接着我们在原型中继续查找:
SELECT * FROM edge WHERE from_node = 4575 AND `type` = "property"
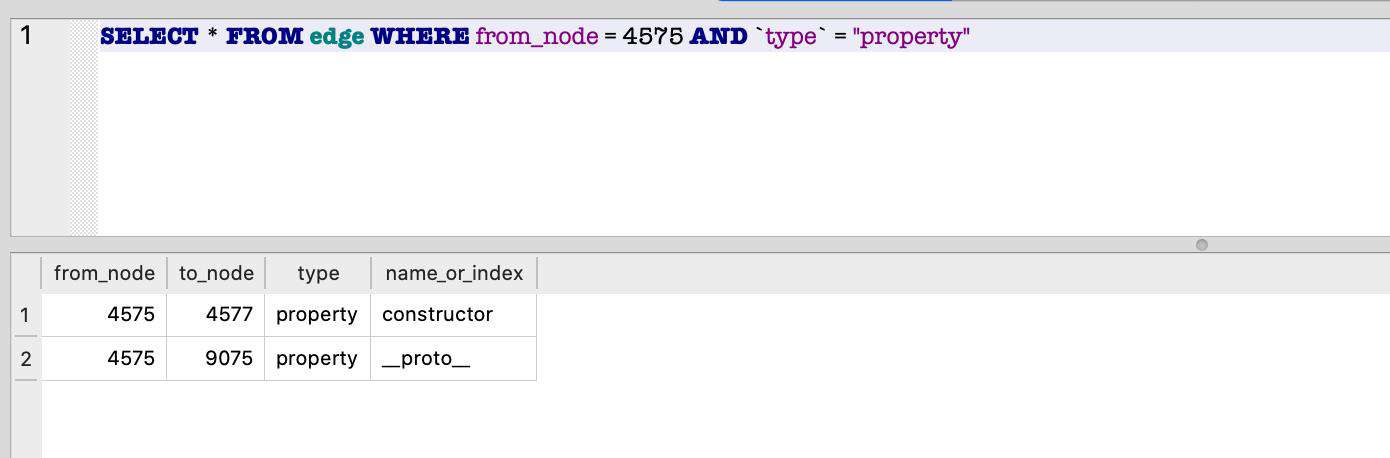
我们找到了 constructor 对象 4577,接着我们来找到它的 shared 内部属性:
SELECT * FROM edge WHERE from_node = 4577 AND name_or_index = "shared"
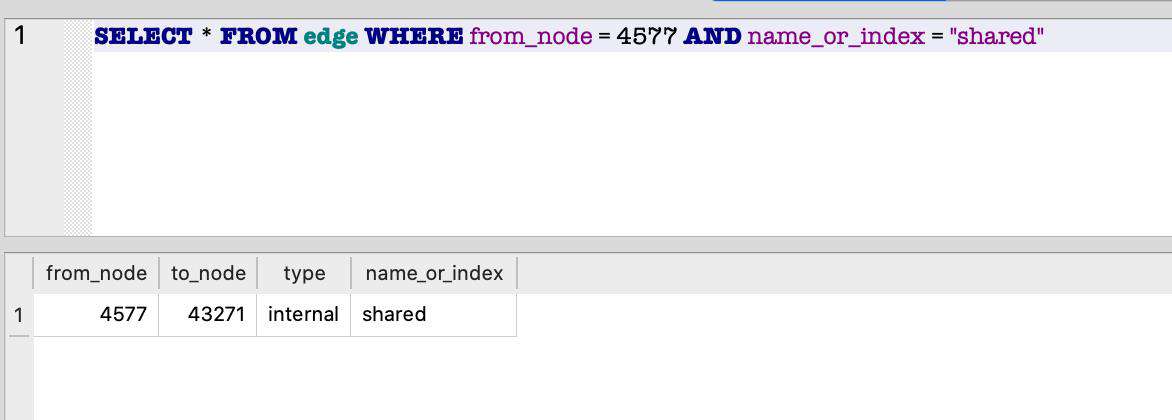
我们简单解释一下 shared 属性的作用是什么。首先,通常函数包含的信息有:
- 定义所在的源文件位置
- 原始代码(在具有 JIT 的运行时中用于 Deoptimize)
- 一组在业务上可复用的指令(Opcode or JITed)
- PC 寄存器信息,表示当然执行到内部哪一个指令,并在未来恢复时可以继续执行
- BP 寄存器信息,表示当前调用栈帧在栈上的起始地址
- 函数对象创建时对应的闭包引用
其中「定义所在的源文件位置」、「原始代码」、「一组在业务上可复用的指令(Opcode or JITed)」是没有必要制造出多份拷贝的,因此类似这样的内容,在 v8 中就会放到 shared 对象中
接下来我们可以输出 shared 对象 43271 的属性:
SELECT * FROM edge WHERE from_node = 43271
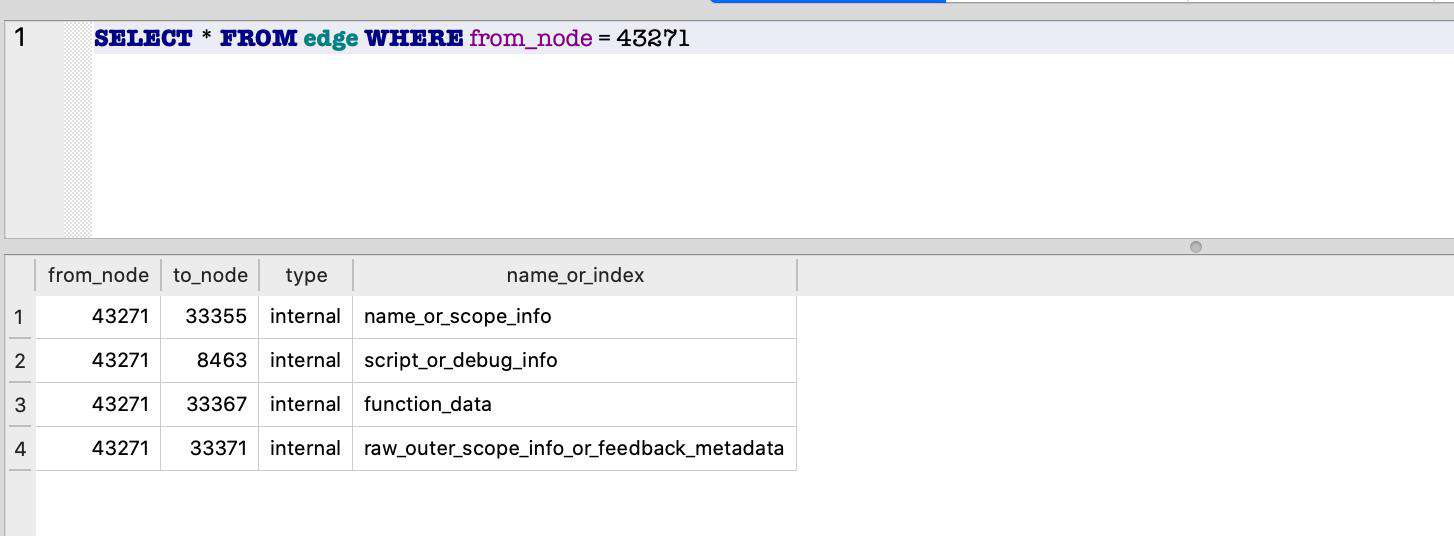
我们继续输出 script_or_debug_info 属性持有的对象 8463:
SELECT * FROM edge WHERE from_node = 8463
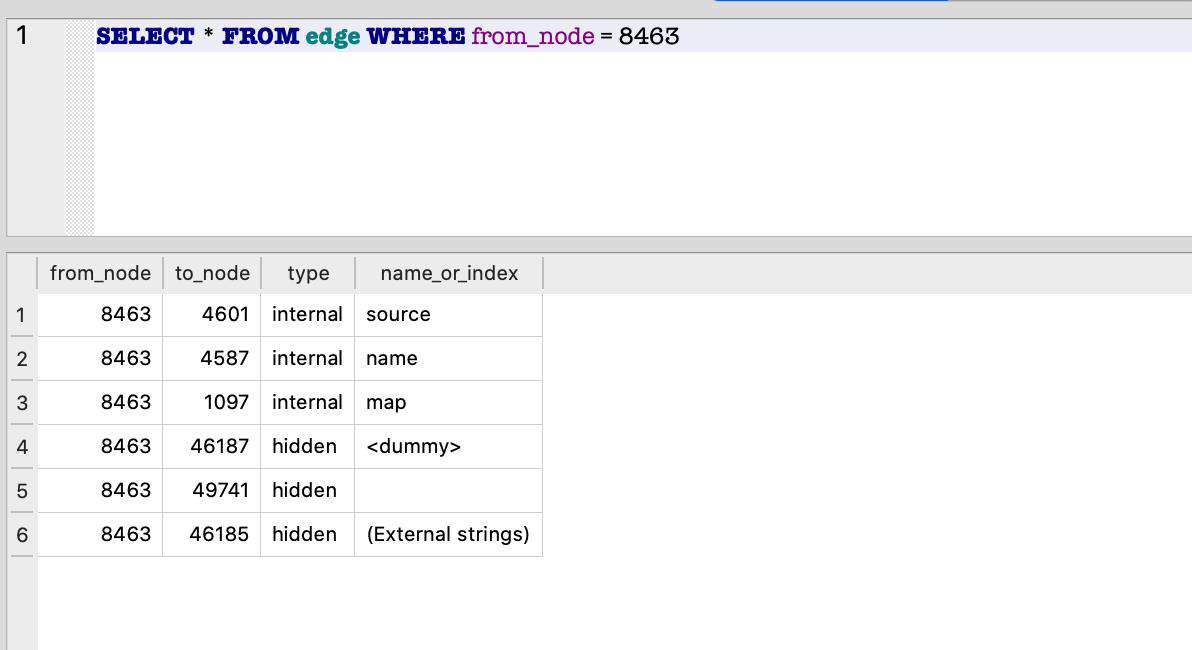
最后我们输出 name 属性持有的对象 4587:
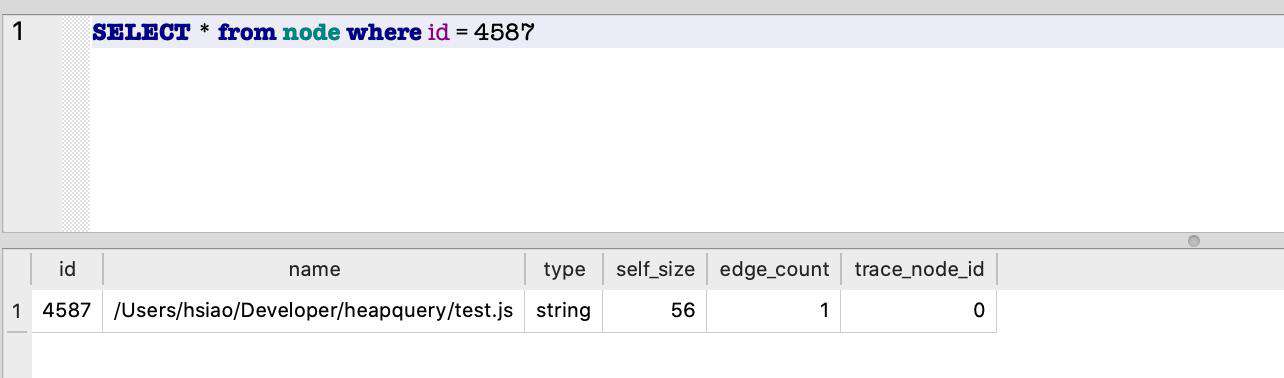
这样我们就找到了对象定义的文件,然后就可以在该文件中继续确定业务代码是否存在泄漏的可能
或许有人会对上面的步骤感到繁琐,其实不必担心,我们可以结合自己实际的查询需求,将常用的查询功能编写成子程序,这样以后只要给一个输入,就能帮助我们分析出想要的结果了
小结
本文以分析 .heapsnapshot 文件的格式为切入点,结合 node 的源码,解释了 .heapsnapshot 文件格式和其生成的方式,并提供了个 heapquery 的小程序,演示了了解其结构可以帮助我们获得不局限于现有工具的信息。最后祝大家上分愉快!
常见问题FAQ
- 免费下载或者VIP会员专享资源能否直接商用?
- 本站所有资源版权均属于原作者所有,这里所提供资源均只能用于参考学习用,请勿直接商用。若由于商用引起版权纠纷,一切责任均由使用者承担。更多说明请参考 VIP介绍。
- 提示下载完但解压或打开不了?
- 找不到素材资源介绍文章里的示例图片?
- 模板不会安装或需要功能定制以及二次开发?





发表评论
还没有评论,快来抢沙发吧!