前言
在计算机内部,无论是一张图片,还是一段视频,又或是一篇文章,本质上都是由海量的“0”和“1”所表示的。计算机在读取一段从网络传来的文字时,会在网口上接收到若干个高电平和低电平以特定规律交替出现的信号,正是这些信号表示了这段文字。我们有人可能会想过这样的问题:当手机上的微信接收到朋友发来的一段文字信息时,这些高低电平构成的“0”和“1”,是如何被计算机所识别,然后呈现在我们的屏幕上的呢?事实上,字符编码在其中扮演了主要角色。
此外,在笔者所在的高校的计算机院里,很少有课程会讲述有关计算机文字编码的知识。大多数课程的教授们都是假设各个同学已经知道了什么是字符编码。但是,当你用 VSCode 打开了一位教授提供的汇编原文件,却发现文件里本该显示的中文注释变成了一堆乱码,这时候就不得不恶补一些有关字符编码的知识了。与此同时,在笔者所主攻的前端领域,由于近期 Emoji 在网页中的使用变得越来越频繁,而 Emoji 在各个系统之间的兼容性存在一些需要注意的问题,所以懂得一些有关 Unicode 字符编码的知识也变得越来越重要了。
因此,本文将以时间为顺序,列举在2021年的今天一个程序员(尤其是前端程序员)所必须要知道的一系列字符编码知识点。涵盖了 ASCII、GBK、UTF-8 和 Emoji 等主题,以及另外一些值得一提的有趣知识点。本文主要参考、引用了维基百科和 Emojipedia 上的相关页面的文字,如果对笔者的阐释有任何疑问,除了发表评论外还可以前往维基百科和 Emojipedia 查找相关资料。
概念
在正式开始介绍字符编码之前,我们需要先理清除有关字符编码的一些概念。
什么是字符集
字符集(Charset)是一系列字符(Character)构成的集合。一个**字符(Character)表示一段文字里具有语义价值的最小单元。**在中文里,一个字符指的就是一个汉字,例如“我”;在英文里,一个字符指的就是一个字母,例如“a”。
什么是码点
码点(Code point)表示一个字符在字符集中所处的位置。简单来说,它就是一种编号,表示“这是字符集里的第几个字符”。字符编码本质上做的事情就是使用一种合适的方法使用0和1表示出这些码点,进而就能表示出字符了。有人也许会说,直接将编号转换为二进制不就可以实现编码了吗?在一定程度上这种做法是对的,许多字符编码规范就是使用这样的思路,因此人们为了方便会将它们同时归类为字符集和编码规范。但是,在一些复杂的情况下这种方法行不通,具体会在后文提到。
什么是字符编码
字符编码(Character encoding)指的是用于将一系列用0和1表示的数字关联到某个特定字符的关系集合。 例如,我们可以使用数字0表示英文字母“a”,使用数字1表示汉字“我”,同时规定:我们使用一个比特表示数字,二进制0就表示数字0,二进制1就表示1。这样我们的一个比特就编码到了一个字符。当计算机接收到0001时,就是接收到了“aaa我”。
上面的例子就是一套简单的字符编码了。当然,只能编码两个字符其实没有什么用,我们往往会需要一些能够对应上几万个汉字字符的字符编码,这样才能承载人们的日常交流。这里还需要强调一下:**字符集不是字符编码,它们有联系,但不是同一个概念。**我们会在下文里结合讨论反复强调这一点。
ASCII
介绍
对于各个科班出身的程序员来说,ASCII 可能是在大一上学期时就接触到了。它是美国在上世纪60年代推出的字符编码,它囊括了英文26个字母的大小写形式、以及一些标点符号和特殊的控制字符(Control codes),如下图所示:
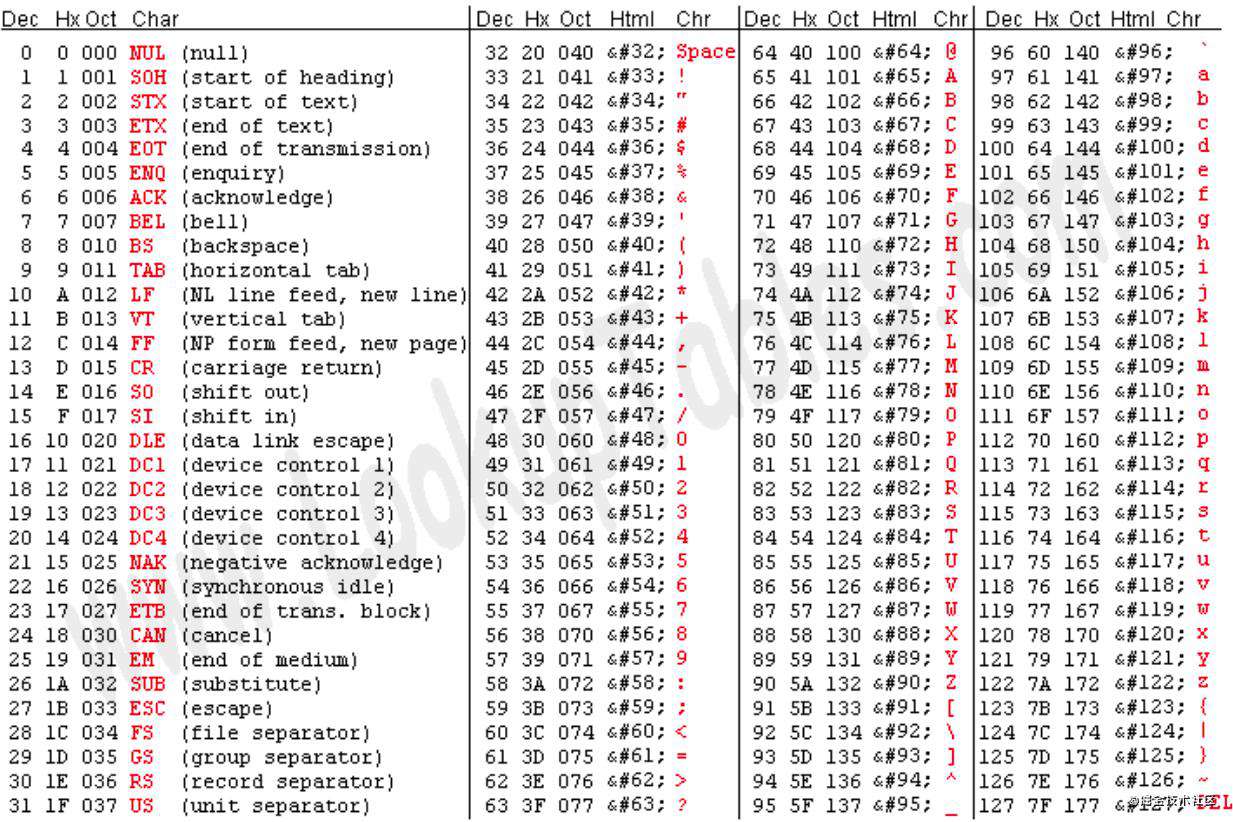 图片来自 lookuptables.com
图片来自 lookuptables.com
它使用了7个比特对上述字符进行编码,例如二进制1100001对应十进制数字97,对应小写字母“a”。使用 ASCII 编码读取一个内容为“11010001100101110110011011001101111”的文本文件,可以得到“hello”。
在 ASCII 被提出以后,它几乎成为了当时计算机的通用字符编码。但是,ASCII 只能编码英文字母和标点符号,对于那些非英语国家例如德国来说就造成了很大的麻烦。随着计算机的发展,使用8个比特(即1个字节)存储字符变得越来越常见。通过简单的数学运算可以知道,如果使用8个比特存储一个字符对应的 ASCII 编码,那么其实会有1个被闲置的比特,它一般会在最高位,值为0。如果能够将这个比特利用起来,我们就能够在使用8个比特存储 ASCII 字符的同时,还能再放下 128 个额外的字符。
基于这个思想,美国以外的其他国家选择在 ASCII 的基础上加入新的字符构成自己国家内通行的字符编码。下面要介绍的 ISO/IEC 8859 编码集就是一个例子。
控制字符
在上世纪 60 年代,计算机主要的输出手段是通过操作电传打字机(Teletypewriter)在纸上打出各种文字,直到后来显示器的兴起才逐步转移到使用显示器进行输出。其实在 UNIX 中,所谓“TTY”的概念指的就是电传打字机,后来当显示器开始被使用时,人们使用软件的手段模拟电传打字机的操作,进而使得现有的针对电传打字机的软件能够正常工作。这里要介绍的控制字符和电传打字机有着密切的关系。
控制字符(Control codes)是 ASCII 中定义的一些有着特殊用途的字符。当计算机遇到这些字符时,它会控制电传打字机的针头做出一些特殊的操作。例如我们非常熟悉的换行符“\n”,计算机遇到这个字符时会控制针头向下移动一行。再结合回车符“\r”让针头移动到一行的开头,于是我们使用“\r\n”就可以进行一次换行操作了,后续输出的其他文字会从新的一行开始打印。在 ASCII 中,“\r”和“\n”也分别被缩写为 CR 和 LF。
单独使用“\r”也有奇妙的作用,例如下面的一段 C 代码:
printf("Hello\rWorld");
这会在控制台上输出“World”,而前面的“Hello”由于我们使用了回车符,被后续输出的“World”所覆盖了。在电传打字机上,我们可能会得到两个单词重叠打印的结果,不过在现在的终端里由于是通过软件模拟的电传打字机,可以直接将原有的文字取代。
ISO/IEC 8859
这是欧洲国家基于 ASCII 扩展出来的一系列字符编码规范,这系列规范总共有十多个,涵盖了欧洲各个国家使用的各种字符。例如,其中的 ISO/IEC 8859-1 字符编码主要包含了西欧国家(德国、法国等)所使用的字符,如下图所示:
 图片来自维基百科
图片来自维基百科
GB/T 2312-1980
简介
上面提到的 ISO/IEC 8859 之所以能够被提出,主要还是因为那多出来的128个字符的位置足以装下欧洲这些国家使用的文字的字符。然而,对于中国这样的,使用数万个汉字去传情达意的国家,ISO/IEC 8859 的方案是行不通的。在1980年,国家推出了 GB 2312 规范(“GB”是“国标”的拼音缩写,即国家标准),它涵盖了几千个常用的简体汉字、标点符号以及 ASCII 中的所有字符。
编码方案
GB 2312 主要使用了 EUC-CN 编码方案。**它将 ASCII 字符(即英文字符等)编码为1个比特,且与 ASCII 一致;而将汉字字符编码为2个比特。**例如,对于小写英文字母“a”,它会被编码为“1100001”,和 ASCII 一模一样。又如,对于汉字“坤”,它会被编码为“0xC0 0xA4”(这里使用十六进制表示)。同时,汉字编码的两个比特中的每一个的范围都必须在“0xA1”到“0xFE”之间。这样,计算机在遇到一个比“0xA1”小的比特时,就知道这代表一个 ASCII 字符;在遇到一个比“0xA1”大的字符时,就知道这个比特和后面的一个比特共同代表一个汉字字符。
这样,在使用了 GB 2312 的计算机上,我们既可以正常打开那些使用 ASCII 的计算机编写的文档,也可以正常打开使用 GB 2312 编写的文档。笔者曾在文章开头时说过,直接将码点编码为对应的二进制作为编码规范有时行不通,这里就是一个很好的例子。因为我们同时需要兼容 ASCII,又要编码几千个汉字字符,所以只能采用这种灵活的方法进行编码了。
历史
GB 2312 是一套非常经典的简体汉字编码规范,囊括了超过99%的日常使用汉字,然而并不包括那些在古汉语和许多人姓名中出现的生僻汉字。因此近年以来,它逐步被 GBK 编码和 GB 18030 编码所替代了。在2017年,国家将 GB 2312 列为推荐标准,名字也变为 GB/T 2312(“T”是“推荐”的拼音首字母),不再是以前那样的强制标准了。
GBK
简介
GBK 可能是在国内最广为人知的汉字编码了。GBK 是 GB 2312 在字符集上的扩展,也就是说 GBK 囊括了 GB 2312 中的所有字符,除此之外它也包括了繁体汉字以及 GB 2312 推出之后才出现的简体汉字。
GBK 在 1993 年被微软公司发布,并且自此之后一直都是 Windows 简体中文版的默认文本字体。在系统自带的命令提示符(cmd)、记事本、资源管理器中的文件名等地方,使用的都是 GBK 编码。它使用的编码规范和 GB 2312 使用的 EUC-CN 类似,也是使用一到两个比特去编码字符,这里由于篇幅限制略去细节。
从上面的 ISO/IEC 8859 到这里的 GBK,我们发现几乎每一个国家都有一套自己的字符编码标准,这在国际间的交流上就产生了严重的问题,例如:在中国内使用 GBK 编写的一段夹杂中文和英文的产品说明书,如果传给一个法国人,它的计算机使用的是 ISO 8859-1 编码,那么他很可能得到的是一堆乱码,因为 ISO 8859-1 编码无法理解 GBK 中的各种编码。
针对这样的问题,在上世纪80年代末,90年代初期,有人设想创建一个异常庞大的字符集,将世界上所有语言的字符集囊括进来,再提供统一的编码方案,这样就能解决国际间的交流问题。Unicode 就是在这样的背景下诞生的。
Windows 与 GBK
为什么Windows 10 的简体中文版仍然在使用 GBK 编码呢?笔者认为主要还是因为历史原因。自 GBK 编码诞生的90年代以来,人们已经编写了无数个使用 GBK 编码的文档,如果突然切换到 UTF-8 等 Unicode 的编码,那么势必会造成很大的麻烦。
事实上,在Windows 日语版中使用的字符编码也不是 UTF-8。因此如果你曾经下载过一些较老的日本游戏,你会发现打开游戏后显示的文字全都是乱码。这时,你往往会需要一种叫做转区软件的程序才能将游戏中的日文正确地显示出来。
屯屯屯和烫烫烫
也许你曾经看过下面这样的段子,或者碰到过类似的神奇乱码:

这些神奇的乱码是如何产生的?据笔者查找资料,原来是 Windows 平台上的 VC++ 编译器在调试模式下会自动将未初始化的栈内存的值填充为 0xCC,将未初始化的堆内存的值填充为 0xCD。同时,由于在简体中文版 Windows 下的命令提示符(cmd)使用的默认文字编码为 GBK。那么,当遇到一连串的 0xCC 时,系统就会按照 GBK 编码解释 0xCCCC 得到了“烫”;遇到一连串的 0xCD 时,系统解释 0xCDCD 得到了“屯”。
我们还有一个类似的著名乱码“锟斤拷”,将在下文介绍。
Unicode
简介
Unicode 是由 Unicode Consortium 维护的一套囊括了世界上绝大多数语言的文字的通用字符集。它的1.0.0版本在1991年发布,最新的版本是在2020年发布的13.0版本,此时它已经囊括了超过14万个字符,来自154种世界上目前使用的,以及历史上曾经使用过的书写系统,以及近几年越来越火的 Emoji 表情。为了兼容 ASCII 编码,它将整个字符集的前128个字符定义为 ASCII 的所有128个字符。
Unicode 平面
Unicode 由17个平面(Plane)组成,每个平面最多可以包含216个字符。其中,第一个平面是Plane 0,也被称为BMP(Basic Multilingual Panel,基本多语言平面)。第一批被加入 Unicode 的汉字就被列入了 BMP 中,之后加入的汉字被加入了第二、三个平面,即 Plane 1 和 Plane 2中,这两个平面分别也被称为 Supplementary Ideographic Plane(表意文字支持平面)和 Teriary Ideographic Plane(表意文字第三平面)。值得一提的是,将汉字加入 Unicode 是由中国、韩国、日本、越南等国家及地区的多种机构负责的。每年都有许多汉字被收入 Unicode 中,包括古代典籍中出现的汉字,以及人名里的生僻字。
一个误区
这里还要注意,Unicode 只是字符集(Charset),不是编码规范。很多人都将 Unicode 误解为一种编码规范,实际上它只是字符集,只能回答“什么字符在 Unicode 里”以及“编号是多少”这样的问题,不能回答“这个字符如何用0和1表示”这样的问题,而后者正是编码规范所做的事情。Unicode 官方采用了多种编码规范,如大名鼎鼎的 UTF-8,以及 UTF-16 和 UTF-32 等。
Unicode Zalgo Text
这里额外介绍一个有趣的概念:Unicode Zalgo Text。首先我们来看一个例子:“é”和“é”。你能看出这两个字符的区别吗?这两个字符看上去一模一样,但是如果把它们分别复制下来使用编程语言比较,你得到的结果是:
> 'é' === 'é'
false
事实上,后者的 Unicode 码点为 U+00E9,而前者的 Unicode 码点为 U+0065、U+0301。后者是一个单独的字符,但前者是一个英文小写字母“e”加上一个特殊的符号。这个特殊的符号会给前面的像“e”这样的字符的顶部显示一个斜点。除了这个特殊字符外,Unicode 还有很多类似的给前面的字符顶部或底部加上记号的特殊字符。它们被 Unicode 统一称为 Acute accent,主要用于像拉丁语、希腊语这样的语言的文字显示上。
于是,有人想到可以给字符叠加几十个甚至几百个这样的特殊字符,从而得到一些显示效果非常诡异的文字,例如“H̴͓̪̩̟̳̺̠̫̤͉̭̗̊̏͑e̷̛̮̠͖͕̝͍̤l̸̛̮͈͍̬̇̈͌́̌̑̎̿͌͝l̶͔͕̀̒̋͐ȍ̷̡̧̦̘̹̺̫̟̭̣͂̌͗̍̽͒̈͑̋̈́͂͑̄͠ ̴̨̲͓̙̺̰͖̞̯̼̝͚̦̐̈́͊̂̊́͊̚ͅw̷̝͍͑̋͐̂͘o̸̱̽̈̓̌̅̽̑́̔͒̃̏̅͗r̶͙͖̬͙̚͝ͅl̴̨͇͙͇̯̬͔̙̞͛̑̈̀͑̓̉̈́͒̾͠͝d̷̠͙̲̗̲̍̐̅”。也有的人会使用 Acute accent 给同一个字符叠加上百个的字符,创造一个显示出来高度甚至突破了字符所在的那行,盖过了其他行的神奇字符。前几年笔者在贴吧、QQ等平台上就常常见到有人转发这些文字。
UTF-8
简介
UTF-8 是一套面向 Unicode 的变长(Variable-width)字符编码规范。**“变长”是指可变长度,依据字符的不同,可能将它编码为一个、两个、三个或四个字节。**其中,UTF-8 专门将 ASCII 中的字符编码为一个字节,且与 ASCII 保持一致,这样 UTF-8 做到了兼容 ASCII 编码。
UTF -8 应该是程序员最为耳熟的一个字符编码规范了,在 Web 领域,超过97%的网页使用了 UTF-8 字符编码。值得一提的是,他的作者是 Rob Pike 和 Ken Thompson,后者正是 C 语言的作者。他们同时也是 Go 语言的作者之一。
 左图为年轻时的 Rob Pike,右图为在贝尔实验室工作时的 Ken Thompson(坐着的那位)
左图为年轻时的 Rob Pike,右图为在贝尔实验室工作时的 Ken Thompson(坐着的那位)
编码规则
既然使用如此广泛,我们有必要稍微深入地研究一下 UTF-8,它的编码规则如下图所示:
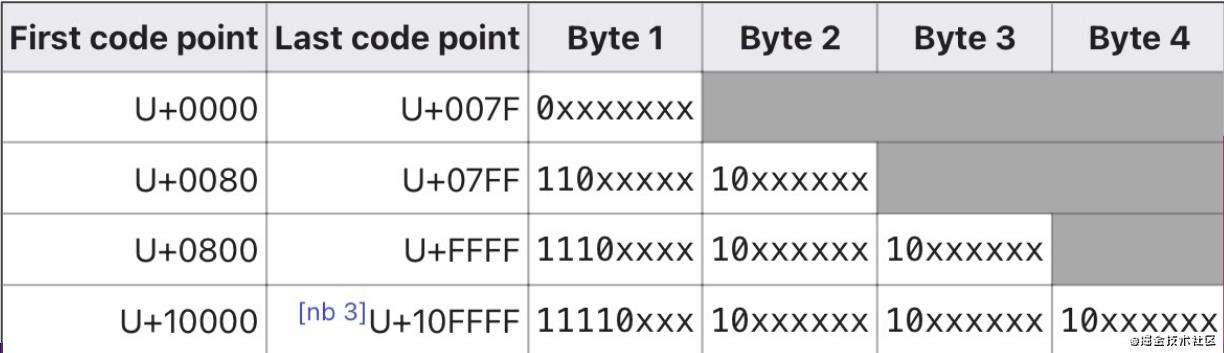 表格来自维基百科
表格来自维基百科
针对不同范围编号的 Unicode 字符,UTF-8 会将它编码为不同长度的比特流。你也许会发现,UTF-8 其实理论上能够编码221个字符,这比 Unicode 现在包含的字符总数还要多的多。但是,为了安全起见,UTF-8 最高能表示的 Unicode 编号被限制在了 U+10FFFF。因此,UTF-8 能够编码的 Unicode 字符范围是 U+0000 ~ U+10FFFF。
UTF-8 与 C 语言
不少人在刚刚开始学习 C 语言的时候可能会写出 char c = '帅' 这样的代码,他们认为一个 char 类型能够装下一个字符,既然能够装下像“a”这样的英文字母,那就也能够装下一个汉字。然而,这样的代码在编译时会被编译器警告,例如在 GCC 中会得到下面的输出:
main.c: In function 'main':
main.c:4:14: warning: multi-character character constant [-Wmultichar]
...
main.c:4:14: warning: overflow in implicit constant conversion [-Woverflow]
究其原因,其实是这里我们的源文件使用了 UTF-8 编码,而 UTF-8 编码会将“帅”这个汉字编码为三个字节,也就是说编译器在读取单引号包围的内容时会读取到三个字节的数据,但 char 类型只能容纳一个字节的数据,自然就会出问题了。
为了验证这一点,我们可以编写这样的代码:
#include <stdio.h>
#include <string.h>
int main(void) {
printf("The length is %ld\n", strlen("帅"));
return 0;
}
这个代码中,我们使用了双引号去包围“我”这个汉字,告诉 C 语言这里是一个 char 类型的数组。编译运行得到的输出是 The length is 3,符合预期。
锟斤拷
在介绍 GBK 编码时,我们介绍了两个著名的乱码产生的原理。这里再介绍一下另一个著名的乱码“锟斤拷”是如何产生的。在 Unicode 中,有一个特殊的字符“�”(U+FFFD),规范规定 Unicode 处理程序在遇到一个无法处理的 Unicode 码点时(可能是因为码点的值无效等原因),将它对应字符替换为这个特殊字符。这种情况在使用 UTF-8 解码 GBK 编码后的文本时可能会发生。
特殊字符“�”在 UTF-8 中会被编码为 0xEFBFBD。一连串的 0xEFBFBD 在 GBK 中会被解码为“锟”(0xEFBF)、“斤”(0xBDEF)和“拷”(0xBFBD),这就是锟斤拷产生的原理。
UTF-16
简介
UTF-16 是 Unicode 官方采用的另一套编码规范,它的编码范围和 UTF-8 一样,而且也同样是变长的字符编码规范。不过,UTF-16 的编码规则很特殊:对于位于 BMP 的字符,它们将被编码为两个字节;而对于 BMP 之外的字符(从 U+10000 到 U+10FFFF),它们将被编码为四个字符。
也由于这种特殊的编码规则,UTF-16 并不兼容 ASCII。不过,Windows 内核、Java 和 Javacript/ECMAScript 的内部使用的却都是 UTF-16 编码。
UTF-8 与 UTF-16
事实上,对于那些位于 BMP 中的汉字,它们的码点都在U+2E80以上。因此,根据上面介绍的 UTF-8 编码规则,它们会被编码为三个字节。但是,在 UTF-16 中则只会被编码为两个字节。注意,BMP 中的汉字已经囊括绝大多数的常见汉字,包括绝大多数的姓名生僻字等。因此,有人认为 UTF-16 相比 UTF-8 更适合编码汉字字符,而 UTF-8 更适合编码像英语这样的字符。
UTF-32
UTF-32 也是 Unicode 官方采用的编码规范。和前面的 UTF-8、UTF-16 相比,它最大的不同在于它是一套定长(Fixed-length)编码规范,即每一个字符都被编码为32个比特(即4个字节)。Go 语言中的rune类型使用的就是 UTF-32 编码。
Emoji?
简介
Emoji 是什么这里就不用多说了,它受到了上世纪90年代日本移动社交网络的影响,是一套经过多方参与共同形成的统一标准,囊括了各种表情、符号等。和 Unicode 类似,Emoji 也在不断地更新发展之中,不断地有新的 Emoji 被加入标准之中。
Emoji 字符集包含什么
Emoji 是一套字符集,被列入了 Unicode 中。**但是,Emoji 除了引入新的字符,还将一些在 Unicode 中已经存在的字符纳入 Emoji 字符集。**例如,在 Unicode 中有一个特殊的区域叫做“Majhong Tiles”,里面包含了麻将牌面所表示的若干个字符。Emoji 标准只将其中的红中列入为了 Emoji。因此你会发现你使用输入法打出来的麻将牌字符,只有红中长得很像 Emoji,但其他却长得像普通的文字(也就是白底黑字的样子)。
Emoji 字体
这里需要强调一个容易混淆的概念:**Emoji 标准只是一套字符集,只定义了“什么字符是 Emoji”,以及“某个字符具体叫做什么(也就是有什么要素)”,但没有定义“Emoji 具体长什么样子”。**你看到的各种 Emoji 字符的外观是由 Emoji 字体所决定的。很多厂商都有开发自己的 Emoji 字体,例如苹果公司给 iOS、MacOS 等自家产品的系统上引入了 Apple Color Emoji 字体,又如微软在 Windows 10 上引入 Segoe UI Emoji 字体。不同厂家的 Emoji 字体都长得不太一样。例如下面的图片展示了“红包”这个 Emoji (U+1F9E7)在不同 Emoji 字体中的样式:
 图片来自 Emojipedia
图片来自 Emojipedia
同时,有些厂商的字体会被“添加私货”。例如,微软的 Segoe UI Emoji 字体将没有被列入 Emoji 规范的其他麻将字符也提供了 Emoji 的样式。**因此,在 Windows 上,如果程序正确使用了 Segoe UI Emoji 字体,那么你看到的麻将字符很可能都长得很像 Emoji,但其实除了红中都不属于 Emoji。**例如下图中就是 Segoe UI Emoji 字体里的两万:
 图片来自 Emojipedia
图片来自 Emojipedia
但是,在笔者使用的 Ubuntu 20.04 上,这个两万字符会显示成这样:

Emoji 与 Unicode Zero-width joiner
在 Unicode 中有一个特殊的字符叫做 Zero-width joiner(ZWJ,码点 U+200D)。它被用来给一些复杂的语言(例如阿拉伯语)的文字进行特殊的排版操作,例如将两个原本连写的字分拆出来。ZWJ 如果单独使用是不会显示的。
Emoji 也利用了 ZWJ,将一些复杂的 Emoji 表情表示为几个简单的 Emoji 表情加上 ZWJ 。例如这个家庭 Emoji 字符:???,其实是由 ?、ZWJ、?、ZWJ、?一共五个字符连接而成的。如果你查看家庭 Emoji 字符的 UTF-8 编码,你会发现它由上述五个字符的 UTF-8 编码组合而成。如果你使用 JavaScript 运行下面的代码:[...'???'],你会得到 ["?", "", "?", "", "?"]。注意,JavaScript 处理像 Emoji 这些处于 BMP 以外的 Unicode 字符时需要特殊的一套方法,详情请查询相关资料。
ZWJ 其实也可以用在普通的文本上,让一些文本变得看上去和原来一模一样,但实际上并不相等,例如下面的这个在 Node 上运行的例子:
> const str1 = [...'异世相遇,尽享美味'].join(String.fromCodePoint(0x200D));
undefined
> const str2 = '异世相遇,尽享美味';
undefined
> str1
'异世相遇,尽享美味'
> str2
'异世相遇,尽享美味'
> str1 === str2
false
我们通过给每个汉字之间加上 ZWJ,创建了一个看上去一模一样,但其实不一样的字符串。这种技巧的用途有很多,有些人可以通过这些空白的ZWJ在一段正常的文字上附加一些特殊的信息,以做到“话里有话”。也有的人给会被贴吧和谐的文字加上 ZWJ 以绕过贴吧的和谐代码,水贴称“据说,帖子和回复里含有XXX就会被和谐”,一座水楼就这样拔地而起。
Emoji Modifier Fitzpatrick Type
Emoji 规范里也定义了很多特殊用途的字符,例如这里要介绍的六个 Emoji Modifier Fitzpatrick Type-N,其中 N 为从1到6(在 Unicode 中的码点从 U+1F3FB 到 U+1F3FF)。这六个特殊字符用于给 Emoji 中的与肤色相关的表情附上肤色信息,如下表的例子所示:
 表格来自维基百科
表格来自维基百科
这里的 Fitzpatrick 是一个人名,这位科学家在对人类的肤色种类的分类上作出了卓越贡献。
总结
以上是笔者对目前常见的一些字符编码收集、总结的一些知识要点。主要的 Reference 为维基百科与 Emojipedia。部分文字可能有失偏颇,或者需要补充,欢迎在评论中指正或补充。
常见问题FAQ
- 免费下载或者VIP会员专享资源能否直接商用?
- 本站所有资源版权均属于原作者所有,这里所提供资源均只能用于参考学习用,请勿直接商用。若由于商用引起版权纠纷,一切责任均由使用者承担。更多说明请参考 VIP介绍。
- 提示下载完但解压或打开不了?
- 找不到素材资源介绍文章里的示例图片?
- 模板不会安装或需要功能定制以及二次开发?





发表评论
还没有评论,快来抢沙发吧!