我的毕设项目是为学院编写一个在线 SQL 考试系统,目标是支撑 300 人同时进行在线 SQL 编程考试,全栈开发。身为前端,我毫不犹豫选择 Node 作为系统后台——告别庞大的 Java,全方位拥抱灵活的 JS,我对项目前景充满信心。项目进展顺利,很快业务完工,到达了最终测试环节,是系统投入真实场景的最后一关(测试不充分,上线必挨喷)。
我的印象中,Node 的并发性能不错,毕竟以前准备面试,背了一些“Node 单线程模型但是 IO 非阻塞,异步性能良好”之类的条文。况且 2021 年了,服务器本身性能也不会差到哪去,支撑 300 人并发估计不需优化就能做到,于是我接过学院一台 8G 内存,4 核 CPU 的云服务器,部署系统之后开始压测,结果发现,程序员是乐观主义者,小丑就是我自己,想的很美好,现实很残酷,目标 300 并发的系统,实际连 100 并发都撑不住,只能夹着尾巴老老实实找问题了。
如何定位 Node 的性能瓶颈
开始寻找性能问题之前,可以先夸夸自己,毕竟到了解决性能瓶颈这一步,代表之前的业务开发已经基本完成,项目搞定了十之八九。
性能测试
首先要对系统进行性能测试,观察各项指标,对系统的目前的性能进行评估,然后找出瓶颈所在,我在项目中使用的性能测试方式有如下两种:
- 某云的 PTS 压测服务,可模拟多 IP 同时并发
- JMeter 线程压测,模拟单点高频访问
具体压测操作不展开描述,感兴趣的朋友可以留下评论,我收集一下,以后讨论。
我开启一次从 0 到 100 递增的 PTS 并发压测,结果如下:
 可见从 100 并发开始,就出现了无法忽略的异常请求返回数量,5万请求860个异常,系统已经撑不住了,然后阅读生成的测试报告,发现几乎所有异常都发生在一个接口,如下图:
可见从 100 并发开始,就出现了无法忽略的异常请求返回数量,5万请求860个异常,系统已经撑不住了,然后阅读生成的测试报告,发现几乎所有异常都发生在一个接口,如下图:
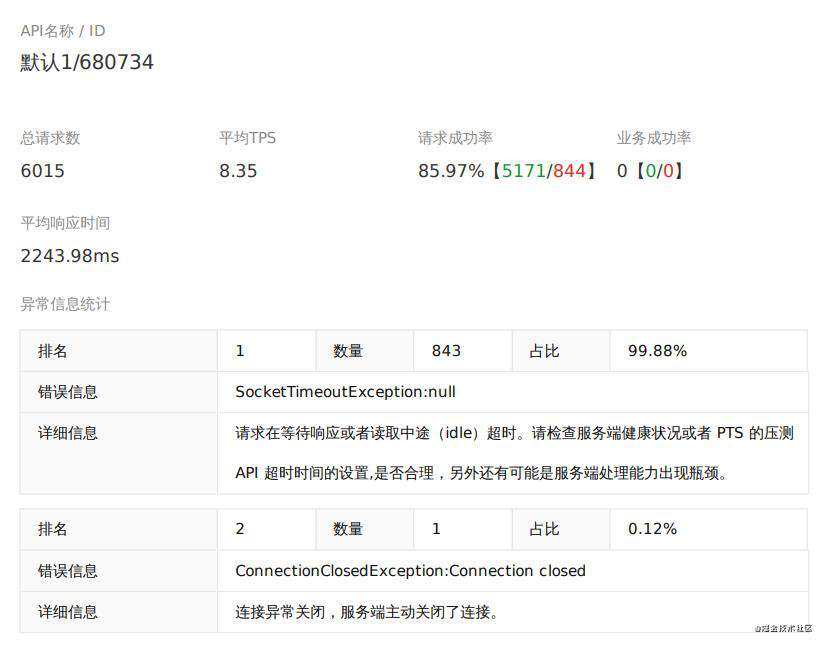 此接口贡献了860个异常请求中的844个,独占鳌头,系统现阶段的瓶颈就藏在这个接口之中。
此接口贡献了860个异常请求中的844个,独占鳌头,系统现阶段的瓶颈就藏在这个接口之中。
定位并缩小问题范围
查找异常接口的Network数据之后发现,该接口是用户登录接口,怎么会呢?一个和业务本身无关的接口竟然成了系统瓶颈,惊讶片刻,我开始寻找更多信息,以确定原因。
首先我尝试提升服务器配置,毕竟之前的 4 核 CPU 着实不够看,如果提升硬件就能解决,至少是一种最直接的方案。然而,当我把配置提升到 32 核,32G,系统性能依然没有任何提升,看来问题不在于硬件配置,需要更进一步确定问题所在了。
我再次开始并发测试,测试期间启动服务端命令行和云端控制台,在命令行运行 top 命令查看进程具体性能,发现本系统 node 主进程的 CPU 占用率直接拉满(100%),然而云端控制台上显示服务器的 CPU 性能占用最高只有 6%,可以看这张云端控制台的服务器性能实时监控图:
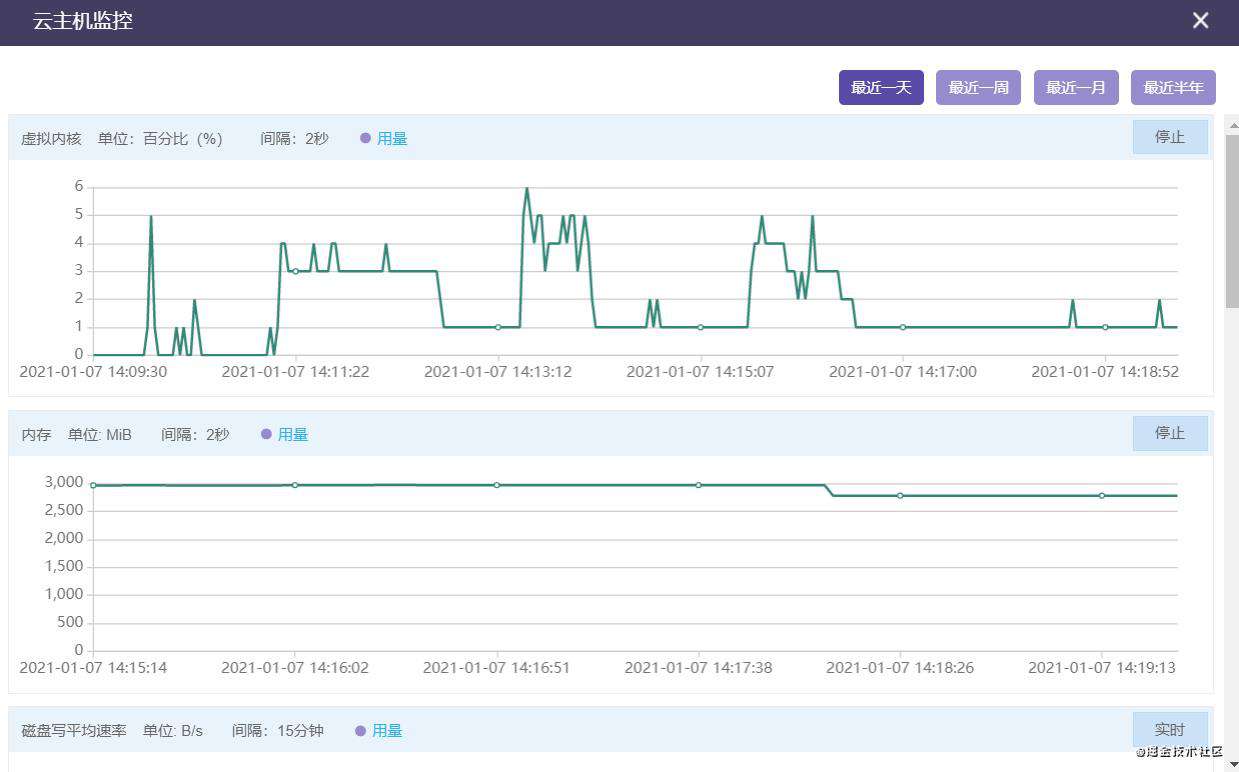
注意纵坐标最大值只有6,在多核 CPU 的条件下,这种现象显然代表主进程没有充分利用多核 CPU,即 CPU 的一个核拼命运行,其他核呆着看戏。此外,也可以看出,top 命令显示的 CPU 占用率是单核的。
现在问题缩小到 node 主进程没办法利用多核 CPU,原因很好理解,Node 本身单线程模型,而我们启动项目也就相当于启动单个进程,所以整个项目就是一个进程一个主线程,一旦主线程拉满,就只能等待。结合已有信息,可以推测:用户登录接口 CPU 消耗过多。然后进行最终确认,将用户登录接口注释,再次进行测试,发现 100 人并发非常轻松,CPU 单核也没有拉满,看来用户登录接口的确消耗了过多 CPU 性能,成为瓶颈。
Code Review
接下来需要找到引起CPU大量性能消耗的代码,于是对写好的用户登录接口进行 CR,如下是我封装的密码工具文件 passhash.js,用于密码加密和校验:
const bcrypt = require("bcryptjs");
/**
* 将用户输入的密码和hash加密后的密码对比
* @param {string} password
* @param {string} passhash
* @returns {Promise<boolean>}
*/
function comparePassword(password, passhash) {
return bcrypt.compare(password, passhash);
}
/**
* 返回hash加密后的密码
* @param {string} password
*/
async function getPasshash(password) {
const salt = await bcrypt.genSalt(10);
const hash = await bcrypt.hash(password, salt);
return hash;
}
module.exports = {
comparePassword,
getPasshash,
};
我使用了 bcrypt 这个库对密码进行了加密,为了提高安全性还加了 10 位的盐,每次登录时都需要调用 bcrypt 的 comparePassword 方法计算用户密码是否正确,显然是 CPU 密集型操作,所以最终确定瓶颈就是密码校验。
解决单线程瓶颈
分析并编码
密码校验是 CPU 密集型操作,而 Node 本身只能用上一个核,要解决这个瓶颈,显然需要进行额外的编码,充分利用多核 CPU。因为 Node 本身没办法启动多个线程,所以只能采取多进程的方式,启动一个主进程,负责系统的主要业务,同时启动多个子进程,负责进行 CPU 密集型计算,有多少个进程就可以利用多少个 CPU 核心。
进行多进程操作,就需要了解 Node 的两个关键模块:child_process 和 cluster,child_process 顾名思义就是子进程模块,提供各种子进程操作,包括创建、销毁、事件监听等等;cluster 意思是集群,就是将子进程进行集成统一管理,封装了 child_process 的 fork 创建方式,屏蔽了 child_process 的一些细节。
我们在项目中创建并管理子进程,直接使用 cluster 即可,用它可以方便的对主进程和子进程进行分工,我的项目使用 Express 框架,所以启动流程写在 server.js 文件内,关键代码如下:
if (cluster.isMaster) {
masterProcess();
} else {
childProcess();
}
// 主进程初始化
function masterProcess() {
// ...启动服务器,监听端口,监听退出信号,这里省略...
// 启动子进程,设定子进程的事件监听函数,具体代码较长,进行了缩略
for (let i = 0; i < numCPUs; i++) {
cluster.fork();
}
bindEvent(cluster.workers); // bindEvent来自子进程事件管理器
}
// 子进程初始化。子进程用于利用多核cpu性能执行耗时操作
function childProcess() {
const passhash = require("./lib/passhash.js");
const { childDataTypes } = require("./const/childWorker.js");
// 子进程监听父进程的事件,根据message事件附带的data对象中的type属性判断消息类型,如果是密码校验请求,则进行响应校验操作
process.on("message", async function (data) {
if (data.type === childDataTypes.password) {
const isMatch = await passhash.comparePassword(
data.password,
data.passhash
);
// uuid是外部生成的唯一id,用于确定本次密码校验结果对应于哪个http请求
if (isMatch) {
process.send({ isMatch: true, uuid: data.uuid });
} else {
process.send({ isMatch: false, uuid: data.uuid });
}
} else {
process.send({ noData: true, uuid: data.uuid });
}
});
}
完成上述步骤后,主进程和子进程已经创建,且二者已经建立事件通信的双向桥梁。其中,bindEvent 方法用于对子进程进行事件监听,定义在事件管理器文件 event-binder.js 中,该文件主要提供两个功能:对子进程进行事件监听、暂存请求的回调函数以便子进程运算完成后调用。关键代码如下:
// 存储回调函数的map结构,用于在子进程给主进程返回事件时,进行相应的回调处理
const callbackMap = new Map();
/**
* 为子进程创建各种类型的事件绑定
* @param {Object} workers 外部传入的cluster.workers
*/
function bindEvent(workers) {
const workerArray = Object.values(workers);
if (workerArray.length === 0 || !workers) {
return;
}
workerArray.forEach((worker) => {
worker.on("message", (data) => {
const callback = callbackMap.get(data.uuid);
callback?.(data);
callbackMap.delete(data.uuid);
});
});
}
function addCallback(uuid, callback) {
callbackMap.set(uuid, callback);
}
module.exports = { bindEvent, addCallback };
接下来剩下最后一步,在处理用户登录请求时,通知子进程进行密码校验,并向子进程事件管理器中注册回调函数,对密码校验结果进行处理,返回登录结果。这部分代码很容易写出来:
const uuid = uuidv4();
const worker = roundRobin(cluster.workers);
worker?.send({
type: childDataTypes.password,
password,
passhash: user.passhash,
uuid,
});
// 向子进程事件管理器中注册uuid对应的回调
addCallback(uuid, responseFunc);
其中,roundRobin 方法是通过最简单的轮询方式选取目前空闲的子进程,然后给该进程派送密码校验任务,其实就是非分布式场景下的负载均衡。responseFunc 函数涉及到具体业务逻辑,不展开描述了,大体就是根据密码校验结果返回不同的提示信息。
再次性能测试
最后重新开启某云的 PTS 压测,启动服务端命令行和云端控制台,命令行 top 之后发现很多 node 进程启动,且每个进程的 CPU 性能都拉到 90%以上,然后观察云端控制台的可视化实时性能图表:
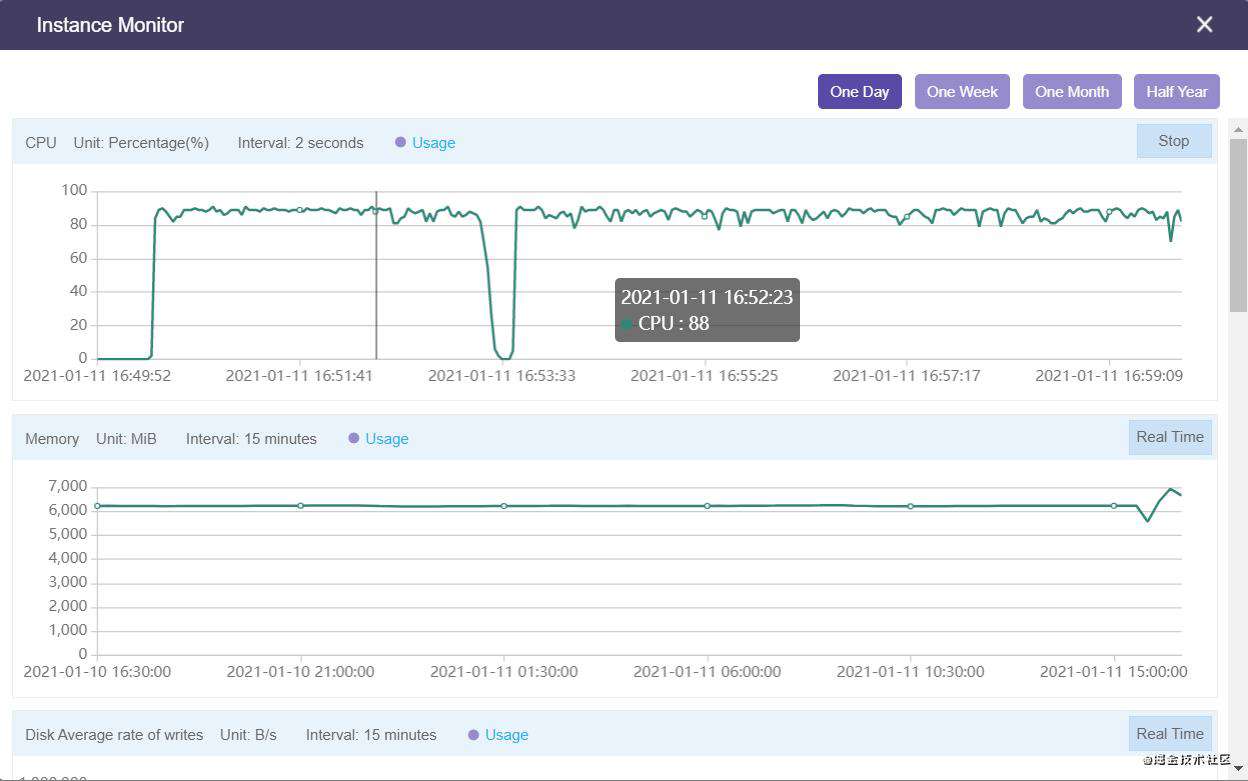
服务器 CPU 终于被拉到了接近 90%,多核性能被充分利用,再看看用户登录接口的表现:
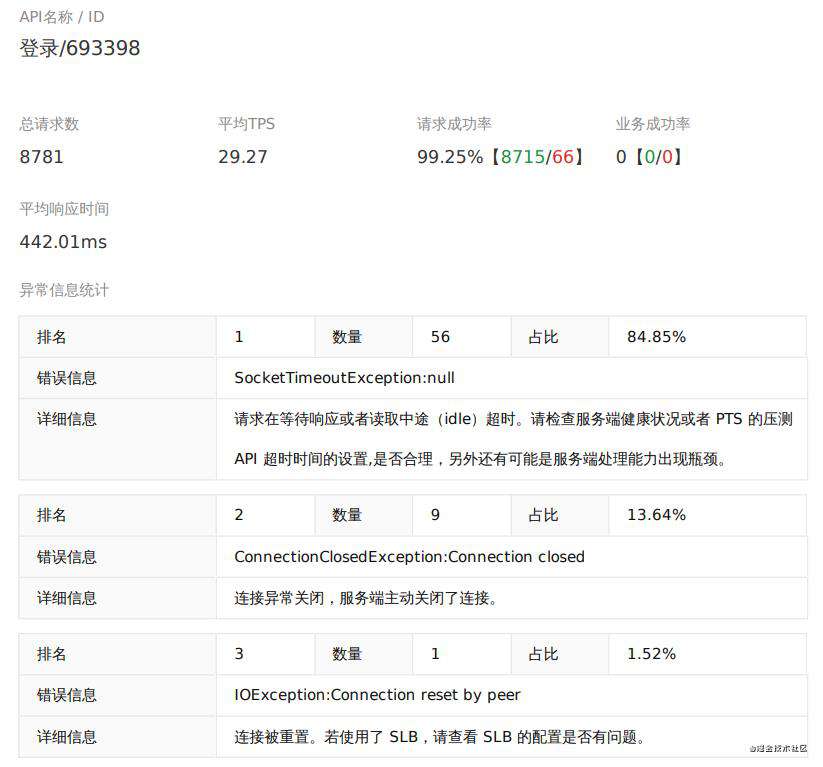
99%以上的成功率,性能比优化前提升了不止一个量级,剩下不到 1%的异常几乎是超时问题,我推测大概率是我使用的内网透传工具的带宽问题,于是打开 JMeter,在内网进行 300 并发的线程压测,表现如下:
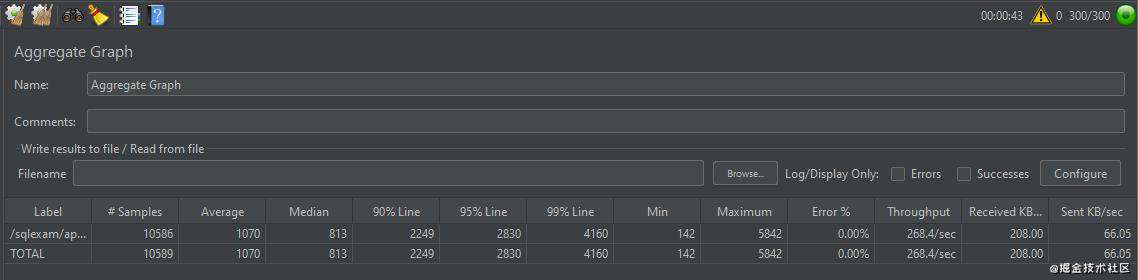
可见,内网测试没有任何错误率,由此可以确定,使用某云 PTS 压测时需要公网 ip,我只能用 ip 透传工具将内网 ip 透传到公网,这个工具存在带宽限制影响了公网测试时的并发性能。解决问题的办法很简单,申请一个公网 ip 服务器即可。
进程间共享状态怎么办
Node进程间状态共享有两种思路:
- 将状态存储在公共的Redis数据库中,所有进程对它进行存取。
- 通过IPC进程间通信的方式,将状态管理在主进程中,主进程状态改变时,通过IPC通知子进程更新状态,子进程状态改变时,也通过IPC通知主进程同步。
小伙伴如有其他好方法,欢迎评论分享。
总结
经过这样的优化,后面又进行了500并发压测也能抗住,第一个正式版本终于安心上线了,虽然随着时间推移可能会暴露更多问题,随着使用人数的膨胀新的性能瓶颈会出现,但是现阶段的事情已经做好,以后水来土掩,出现问题再解决,不断优化、扩展系统,才是软件正常的发展趋势(理直气壮的把锅甩给学弟学妹,手动狗头)。
牛年到来,春招将至,祝愿同学们收获满意的 offer,同事们工作顺利。新的一年腾讯 AlloyTeam 会继续招募新同学,这里先做个预报,后续春招正式开始后,欢迎把简历丢给我。
阿联会继续输出干货文章,一切源于实战和学习思考的结合,如果对你有帮助,欢迎关注我,一起进步。
参考资料
Node 文档——cluster集群
其他干货
面经加答案:
- 科班小前端的大厂面经
Webpack干货:
- 在淘宝优化了一个大型项目,分享一些干货(Webpack,SplitChunk代码实例,图文结合)
- 妈妈再也不用担心我的优化|Webpack系列(二):SplitChunksPlugin源码讲解
CSS 细节:
- 面试官想知道你多了解 position:absolute
写给找不到方向的同学
- 后端转前端的小老弟突然收割大厂offer,真相竟然是
常见问题FAQ
- 免费下载或者VIP会员专享资源能否直接商用?
- 本站所有资源版权均属于原作者所有,这里所提供资源均只能用于参考学习用,请勿直接商用。若由于商用引起版权纠纷,一切责任均由使用者承担。更多说明请参考 VIP介绍。
- 提示下载完但解压或打开不了?
- 找不到素材资源介绍文章里的示例图片?
- 模板不会安装或需要功能定制以及二次开发?





发表评论
还没有评论,快来抢沙发吧!