是什么?
虚拟DOM(Virtual DOM)的本质就是一个对象,这个对象有三个属性,tag,attrs,children。们可以用这个对象来表示页面中的节点。
var element = {
tag: 'ul', // 节点标签名
attrs: { // DOM的属性,用一个对象存储键值对
id: 'list'
},
children: [ // 该节点的子节点
{tag: 'li', attrs: {class: 'item'}, children: ["Item 1"]},
{tag: 'li', attrs: {class: 'item'}, children: ["Item 2"]},
{tag: 'li', attrs: {class: 'item'}, children: ["Item 3"]},
]
}
对应的HTML节点是这样的:
<ul id='list'>
<li class='item'>Item 1</li>
<li class='item'>Item 2</li>
<li class='item'>Item 3</li>
</ul>
为什么?
想象一下这样的一个场景,如果我们要在网页中绘制一个表格,我们遍历后端给的数据然后,创建对应的标签插入到页面中,如果此时后端所给的数据变了,那么我们便需要重新遍历后端给的数据,然后创建对应的节点,然后插入到页面中。
如果我们还想使用JS操作表格里面的元素,那么随着数据与操作功能的增加,JS代码会变得非常繁杂且不便于维护。
对于从事前端的同学应该知道这会存在很严重的性能问题,由于Javascript是存在很多的标准的,浏览器为了适应这些标准从而将DOM元素做的非常复杂,这大大增加了我们操作DOM背后的工作量。这是一个DIV节点的第一层结构。

为了减少JS的代码量我们有了许多的MVVM框架来帮助我们,本质上这些框架要做的就是监听状态(数据)的改变,然后更新视图。但是在具体实现上这些框架所用的方法是不同的,有Angular的脏检查,Vue的依赖收集等,而这里所说的虚拟DOM(Virtual DOM)实际上也是一种方法,主要被React所使用。
其主要工作原理就是,用一个对象来表示页面中的元素,这个对象也就是所说的虚拟DOM。之后我们根据虚拟DOM生成真实的元素节点然后插入到页面中,当页面中的数据或者元素更改从而导致对应的虚拟DOM更改,我们就使用一个算法遍历我们的
怎么做?
1.使用JS对象模拟DOM树
我们需要利用一个构造函数来生成对象,使用构造函数的原因是:
- 方便我们后续创建对应的节点时使用递归
- 方便后续子元素的类型检查
function Element (tag, attrs, children) {
this.tagName = tagName
this.props = props
this.children = children
}
function el(tag, attrs, children) {
return new Element(tag, attrs, children)
}
之后生成我们所需要的对象:
var ul = el('ul', {id: 'list'}, [
el('li', {class: 'item'}, ['Item 1']),
el('li', {class: 'item'}, ['Item 2']),
el('li', {class: 'item'}, ['Item 3'])
])
之后就可以根据对象来生成所需要的DOM节点了,这个比较重要:
Element.prototype.render = function(){
let el = document.createElement(this.tag);
let attrs = this.attrs;
for(let attrName in attrs) {
let attrValue = attrs[attrName];
el.setAttribute(attrName,attrValue);
}
let children = this.children || [];
children.forEach( child => {
let childEle = (child instanceof Element)? // 判断子元素是不是节点
child.render(): // 如果是递归继续渲染
document.createTextNode(child); // 否则创建一个文本节点便好
el.appendChild(childEle);
});
return el;
}
let ulRoot = ul.render();
document.body.appendChild(ulRoot);
2.比较两棵虚拟DOM树的差异
在上面我们已经根据虚拟DOM生成了真实元素节点,并且把它插入到了页面中,接下来我们的虚拟DOM将会更新(也就是真实情况中数据将会改变),我们需要使用一个算法比较新旧两棵虚拟DOM树的差别(也就是diff算法),然后生成一个补丁patches(记录两棵树的差别的对象),之后根据这个补丁来修改页面中的节点元素。
对于比较两棵树的不同我们采用的是深度优先遍历,遍历到的每一个节点都会有一个记号(也就是当前节点的索引),在遍历的过程中比较两棵树节点的不同,然后记录在一个对象里:
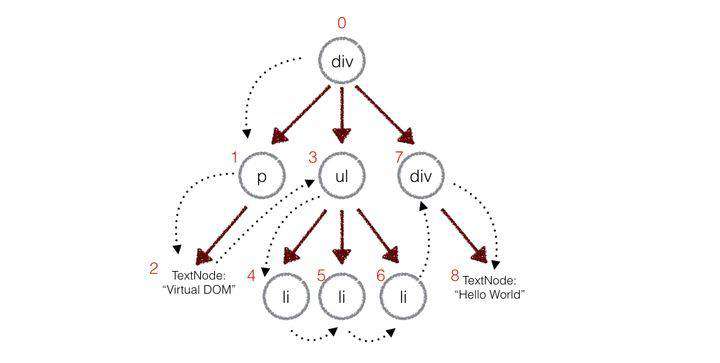
这里就先放一下大概的比较过程,具体diff算法的细节还是请看戴嘉华大佬的这篇文章,里面也有完整的diff算法流程。
这里主要是遍历虚拟DOM 树的每一个节点得到index从而生成patches补丁,具体比较两个节点区别的部分比较复杂就省略了,大家有兴趣还是推荐去看看的。
// diff 函数,对比两棵树
function diff (oldTree, newTree) {
var index = 0 // 当前节点的标志
var patches = {} // 用来记录每个节点差异的对象
dfsWalk(oldTree, newTree, index, patches)
return patches
}
// 对两棵树进行深度优先遍历
function dfsWalk (oldNode, newNode, index, patches) {
// 对比oldNode和newNode的不同,记录下来
patches[index] = [...]
diffChildren(oldNode.children, newNode.children, index, patches)
}
// 遍历子节点
function diffChildren (oldChildren, newChildren, index, patches) {
var leftNode = null
var currentNodeIndex = index
oldChildren.forEach(function (child, i) {
var newChild = newChildren[i]
currentNodeIndex = (leftNode && leftNode.count) // 计算节点的标识
? currentNodeIndex + leftNode.count + 1
: currentNodeIndex + 1
dfsWalk(child, newChild, currentNodeIndex, patches) // 深度遍历子节点
leftNode = child
})
}
如果两棵树标记为0的节点是不同的那么补丁大概是这样:
patches[0] = [{difference}, {difference}, ...] // 用数组存储新旧节点的不同
3.比较具体两个节点的区别
上面说了我们怎么比较两棵树的,那补丁到底是什么样的呢?
因为对于两个节点来说可能有很多处不同,比如标签名,一个是div一个是span,比如属性值等等,也有可能是标签里面的文本内容等等,所以我们首先将这些区别分成了四种类型:
- 替换掉原来的节点,例如把上面的div换成了section
- 移动、删除、新增子节点,例如上面div的子节点,把p和ul顺序互换
- 修改了节点的属性
- 对于文本节点,文本内容可能会改变。例如修改上面的文本节点2内容为Virtual DOM 2。
对应的;
var REPLACE = 0
var REORDER = 1
var PROPS = 2
var TEXT = 3
所以看见下面几个例子:
如果是标签名不一样从之前的div变为section,我们需要直接替换掉之前的节点:
patches[0] = [{
type: REPALCE,
node: newNode // el('section', props, children)
}]
如果给div新增了属性id为container,就记录下:
patches[0] = [{
type: REPALCE,
node: newNode // el('section', props, children)
}, {
type: PROPS,
props: {
id: "container"
}
}]
如果是文本节点不一样,那么我们需要记录一下:
patches[2] = [{
type: TEXT,
content: "Virtual DOM2"
}]
节点的标签、属性、文本的更改我们都可以记录了,那么如果是同一级节点的位置修改了,比如之前div的子节点是p,span,section,现在变成span,section,p,我们要完全替换掉之前的三个标签吗?这样显然开销比较大了,创建DOM再插入是比较昂贵的操作。我们只需要使用算法将其进行移动便好了。
这个算法称之为列表对比算法。
假如旧节点的顺序是这样的:
a b c d e f g h i
现在对节点进行了删除、插入、移动的操作。新增j节点,删除e节点,移动h节点:
新节点的顺序是:
a b c h d f g i j
那么究竟如何用最简单的删除、移动、增加完成旧到新的改变呢?
得到的补丁是这样:
patches[0] = [{
type: REORDER,
moves: [{remove or insert}, {remove or insert}, ...]
}]
需要注意的是:很多时候可能两个节点名是一样的,所以我们需要给每个节点增加一个独一无二的记号key,我们在列表进行比较的时候使用key进行比较,这样当节点只是移动位置的时候我们才可以复用节点。
这样我们使用深度优先遍历虚拟DOM树,遍历得到的当前节点就与新树上的节点比较,如果有差异就记录下来。得到补丁(patches)之后我们就需要根据补丁来真正修改页面中的节点了,完整 diff 算法代码可见 diff.js。
4.修改页面中的元素
使用深度优先遍历最初生成的真实的DOM树ulRoot,在遍历的过程中找到当前节点对应的补丁,然后进行修改。
function patch (node, patches) {
var walker = {index: 0}
dfsWalk(node, walker, patches)
}
function dfsWalk (node, walker, patches) {
var currentPatches = patches[walker.index] // 从patches拿出当前节点的差异
var len = node.childNodes
? node.childNodes.length
: 0
for (var i = 0; i < len; i++) { // 深度遍历子节点
var child = node.childNodes[i]
walker.index++
dfsWalk(child, walker, patches)
}
if (currentPatches) {
applyPatches(node, currentPatches) // 对当前节点进行DOM操作
}
}
applyPatches,根据不同类型的差异对当前节点进行 DOM 操作:
function applyPatches (node, currentPatches) {
currentPatches.forEach(function (currentPatch) {
switch (currentPatch.type) {
case REPLACE:
node.parentNode.replaceChild(currentPatch.node.render(), node)
break
case REORDER:
reorderChildren(node, currentPatch.moves)
break
case PROPS:
setProps(node, currentPatch.props)
break
case TEXT:
node.textContent = currentPatch.content
break
default:
throw new Error('Unknown patch type ' + currentPatch.type)
}
})
}
完整代码可见 patch.js。
5.总结
最后我们可以发现其实完整的虚拟DOM算法是分为三大部分的,我们可以捋一下具体的过程。
首先我们需要使用Element构造函数生成虚拟DOM,之后使用render方法将其转换为真实的DOM对象,从而插入到页面之中。
当页面中的数据修改我们得到新的虚拟DOM树,使用diff方法,遍历旧的虚拟DOM对象和新虚拟DOM树进行比对得到patches补丁,之后由patch方法传入补丁与真实的DOM对象更改页面,这个过程也是深度优先遍历真实的DOM节点从patches中找到当前节点对应的补丁从而进行节点操作。
最后想说一点的是,对于将虚拟DOM生成真实的对象的render方法,要重点掌握,这是之前字节考过的原题。
// 1. 构建虚拟DOM
var tree = el('div', {'id': 'container'}, [
el('h1', {style: 'color: blue'}, ['simple virtal dom']),
el('p', ['Hello, virtual-dom']),
el('ul', [el('li')])
])
// 2. 通过虚拟DOM构建真正的DOM
var root = tree.render()
document.body.appendChild(root)
// 3. 生成新的虚拟DOM
var newTree = el('div', {'id': 'container'}, [
el('h1', {style: 'color: red'}, ['simple virtal dom']),
el('p', ['Hello, virtual-dom']),
el('ul', [el('li'), el('li')])
])
// 4. 比较两棵虚拟DOM树的不同
var patches = diff(tree, newTree)
// 5. 在真正的DOM元素上应用变更
patch(root, patches)
本文所实现的完整代码存放在 Github,仅供学习。
虚拟DOM的性能怎么样?
这个问题我推荐大家去看尤大知乎上的这个回答,这里简要的说一下。
首先我们要知道JS的计算一般是要远远便宜与DOM操作的,如果我们只有少部分的数据要改变,我们使用虚拟DOM,得到差别后再去修改页面中的元素还是效率比较高的,但是如果有大量的数据要改变相比于直接操作DOM来说我们还要增加diff算法的消耗。所以对于React来说如果有大量数据要改变的情况下还是通过其他的算法去实现的,应该是直接重写innerHtml。
所以对于虚拟DOM来说,其性能优势往往只在一些特定的场合其作用,如在初始渲染时(不需要像Vue那样依赖收集,所以比较快),拥有大量数据但只有小部分数据更改时。
所以对于虚拟DOM来说其真正的优先是在于:
- 其为函数式UI提供了思路,即像UI = f(data)这种构建UI的方式。
- 其可以渲染到DOM以外的其他场合中,也就是跨平台开发,如ReactNative。
最后看一下虚拟DOM与各大框架在性能上的比较,来自于尤大:
- 初始渲染:Virtual DOM > 脏检查 >= 依赖收集
- 小量数据更新:依赖收集 >> Virtual DOM + 优化 > 脏检查(无法优化) > Virtual DOM 无优化
- 大量数据更新:脏检查 + 优化 >= 依赖收集 + 优化 > Virtual DOM(无法/无需优化)>> MVVM 无优化
参考:
戴嘉华:如何理解虚拟DOM
尤大:网上都说操作真实 DOM 慢,但测试结果却比 React 更快,为什么?
常见问题FAQ
- 免费下载或者VIP会员专享资源能否直接商用?
- 本站所有资源版权均属于原作者所有,这里所提供资源均只能用于参考学习用,请勿直接商用。若由于商用引起版权纠纷,一切责任均由使用者承担。更多说明请参考 VIP介绍。
- 提示下载完但解压或打开不了?
- 找不到素材资源介绍文章里的示例图片?
- 模板不会安装或需要功能定制以及二次开发?





发表评论
还没有评论,快来抢沙发吧!