欢迎大家给欧巴打榜!点击欧巴头像右侧 年度打榜投票中 可直达。您的支持是我更新最大的动力。
美味值:?????
口味:仔梅烧小排
01 浏览器架构演进
开篇我们先来简单回顾下历史,从 1993 年发布的第一款“好用”的浏览器 Mosaic,到 1994 年网景公司推出的红极一时的 Navigator 浏览器,图形用户界面化的浏览器终于开始推动了 Web 技术的普及和发展。
微软也随后推出了 IE,加入战场并取得浏览器大战“一战”的胜利。战败的网景公司索性将 Navigator 源代码开源,创建了 Mozilla 基金会,并于 2004 年发布了 Firefox 浏览器。
苹果公司于 2003 年发布了 Safari 浏览器,Google 公司于 2008 年发布了 Chrome 浏览器。Chrome 浏览器在浏览器大战的“二战”中技压群雄,拔得头筹。现如今也是前端工程师最喜爱的浏览器,没有之一。
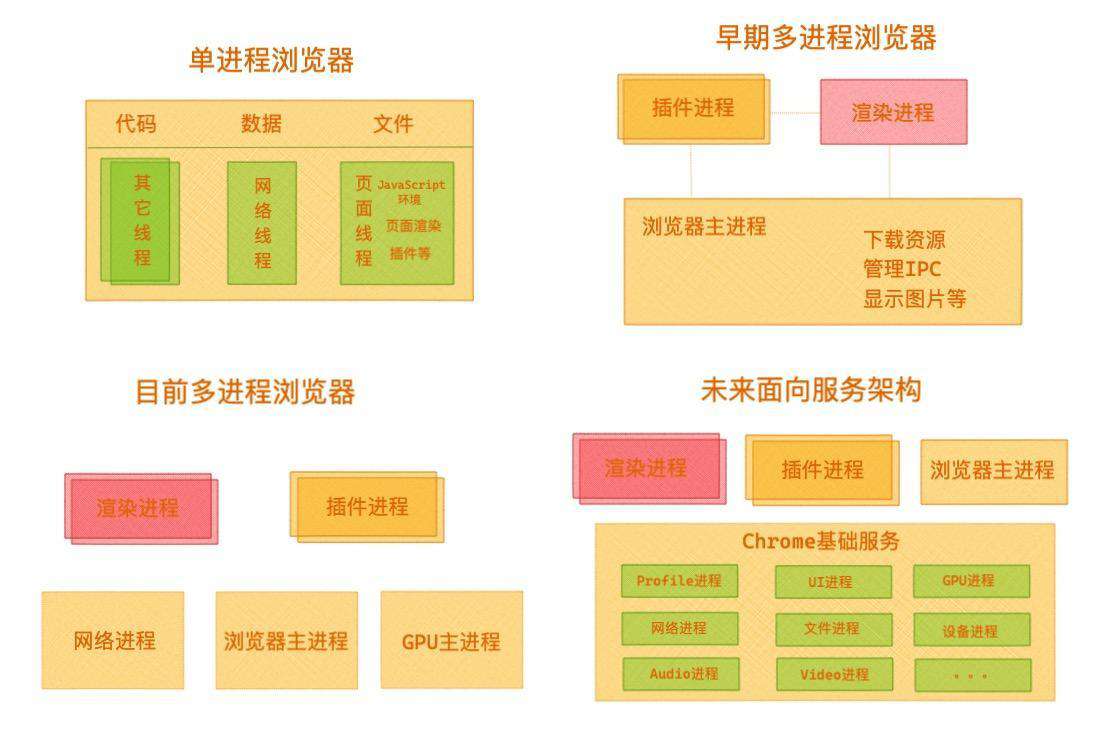
Chrome 浏览器从 2007 年以前的单进程架构到现在的多进程架构,浏览器的架构在不断的升级,变得更加稳定、更加流畅、更加安全。目前 Chrome 的浏览器包括如下进程:
- 1 个浏览器(Browser)主进程
- 1 个 GPU 进程
- 1 个网络(NetWork)进程
- 多个渲染进程(运行在沙箱模式下)
- 多个插件进程
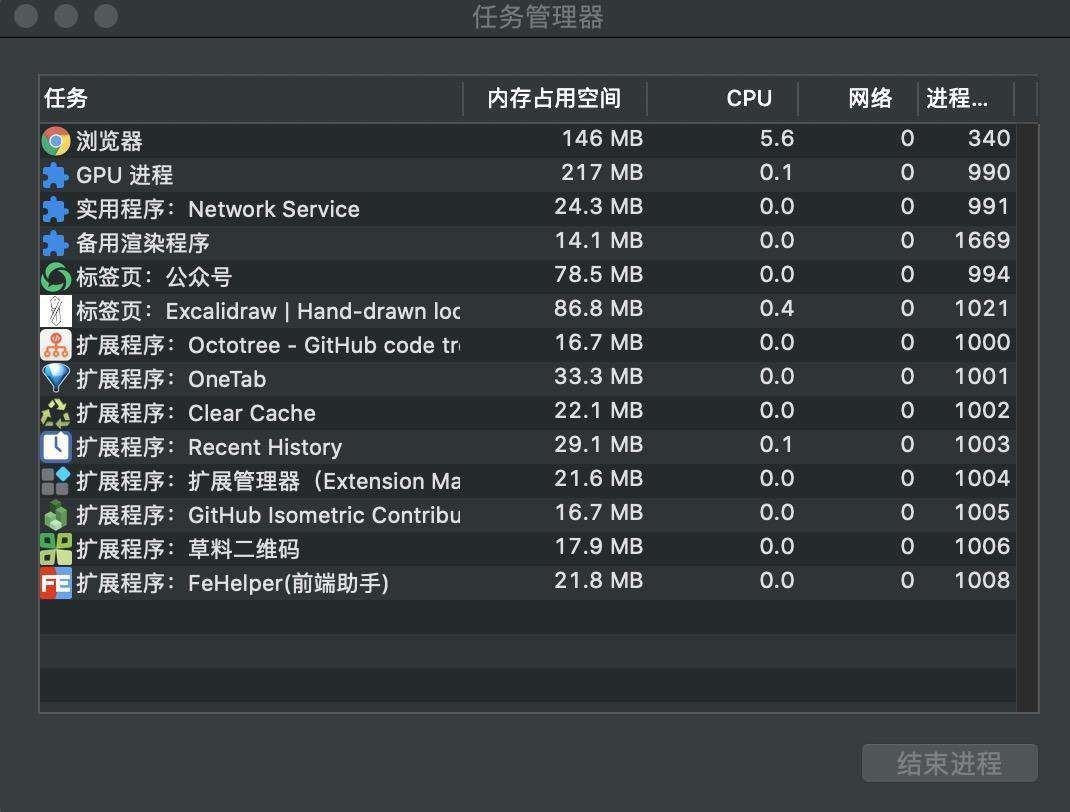
不过,软件工程可没有银弹。浏览器的架构体系也随着调整变得更加复杂,也会有更高的资源占用。
那么如何寻求一种在资源占用和复杂架构体系之间的平衡便成为了一个难题。
小孩子才做选择,鱼和熊掌我都要!
Chrome 团队在 2016 年使用“面向服务的架构”(Services Oriented Architecture,简称 SOA)的思想设计了新的 Chrome 架构。
他们将模块重构成独立的服务(Service),服务运行在独立的进程中,想要访问的话必须使用定义好的接口,通过 IPC 来进行通信。这样的架构无疑更加内聚、松耦合、易于维护和扩展。
02 浏览器导航渲染流程
从输入 URL 到页面展示,这中间发生了什么?
这是一道十分常见的面试题,不过大多数人回答这个问题时都不够系统和全面,可见这道题能够充分考察应试者的知识深度。
我画了一张图整理了浏览器的导航渲染流程,下面我们来一起查缺补漏。
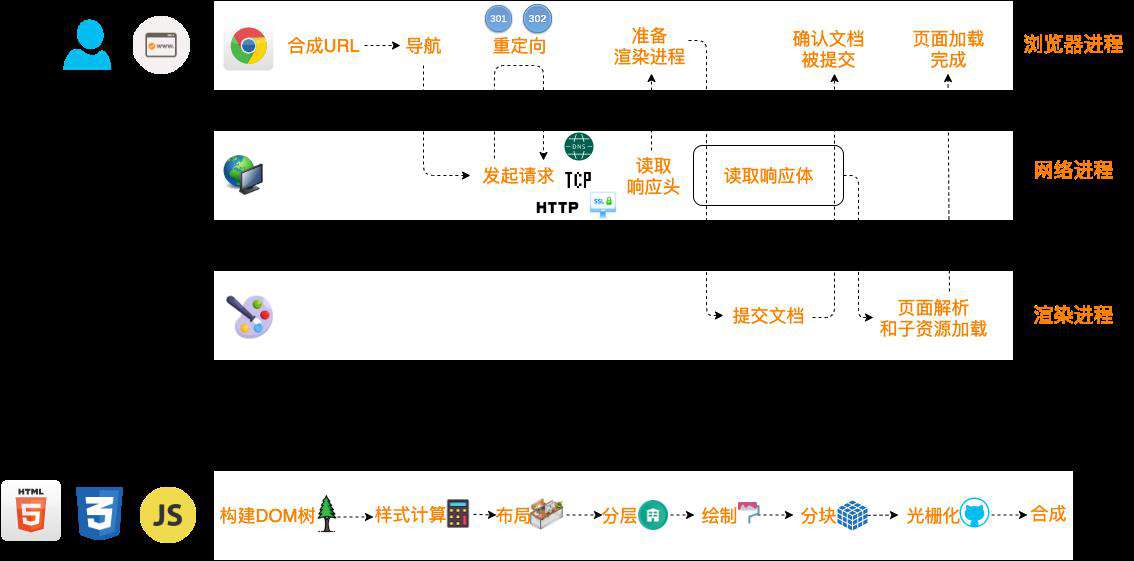
导航流程
- 用户在地址栏输入内容后,地址栏会将输入的内容进行合成 URL。
- 当用户输入完内容并按下回车键时,浏览器会在当前页面执行 beforeunload 事件,你可以在这个钩子中询问是否要离开当前页面,常见于一些表单提交的场景。
- 接下来开始导航流程,浏览器进入加载状态。
- 浏览器的网络进程会先查找缓存中是否存在该资源,有的话直接返回,如果没有的话会发起 URL 请求。
- 接下来首先要进行的是 DNS 解析,获得请求域名的服务器的 IP 地址(这个过程我也画了一张图,放在下文),如果协议是 HTTPS,还需要建立 TLS 连接。
- 接着利用目标服务器的 IP 地址建立 TCP 连接(三次握手),构建 HTTP 请求报文,发起请求。服务器收到请求后,会根据请求信息生成响应报文。
- 浏览器的网络进程接收到响应报文后进行解析,如果状态码是 301 或者 302,则需要取得响应头中的 Location 对应的地址进行重定向,再重新发起请求。
- 如果状态码是 200,浏览器会根据响应头中的 Content-Type 字段来识别返回的响应体数据类型,从而进行不同的流程。如 text/html 代表 html 格式,
application/octet-stream 代表字节流类型,浏览器会按照下载类型来处理。 9. 如果是 HTML,浏览器会遵循 process-per-site-instance 默认策略准备渲染进程,准备好后就提交文档(将网络进程接收到的数据提交给渲染进程)。文档被提交后,渲染进程便开始进行页面解析和子资源的加载。
(当然在第 7 点中还有 300、303 等 3xx 的状态码,具体含义可以参考我的这一篇专栏 那些年与面试官交手过的HTTP问题)
process-per-site-instance 默认策略:每个标签对应一个渲染进程,如果从一个页面打开了一个新页面,新打开的页面与当前页面还属于同一个站点的话,那么新页面会复用当前页面的渲染进程。
渲染流程
渲染流程在上图中一并画了出来,需要经过以下几个阶段:
- 构建 DOM 树
- 样式计算
- 布局
- 分层
- 绘制
- 分块
- 光栅化
- 合成
因为渲染流程的内容比较多,本文先不详细展开,后面我们再开一篇专栏进行讲解。
DNS
DNS 的解析是一个递归流程,顺序如下图中数字标记所示:
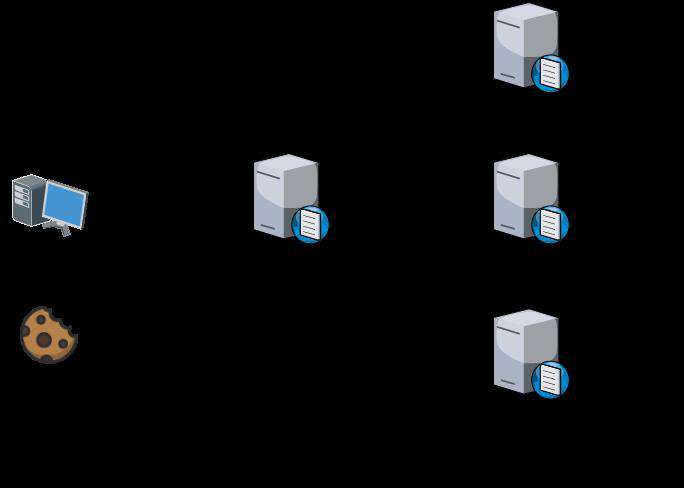
- 根 DNS 服务器:返回顶级域 DNS 服务器的 IP 地址
- 顶级 DNS 服务器:返回权威 DNS 服务器的 IP 地址
- 权威 DNS 服务器:返回相应主机的 IP 地址
03 垃圾回收
栈中的垃圾数据
先来看一段简单的示例代码:
function hello () {
var name = '前端食堂'
var food = { name: '回锅肉' }
function world () {
var description = { slogan: '吃好每一顿饭' }
}
world()
}
hello()
上面的代码所对应的内存堆栈空间如下图所示:
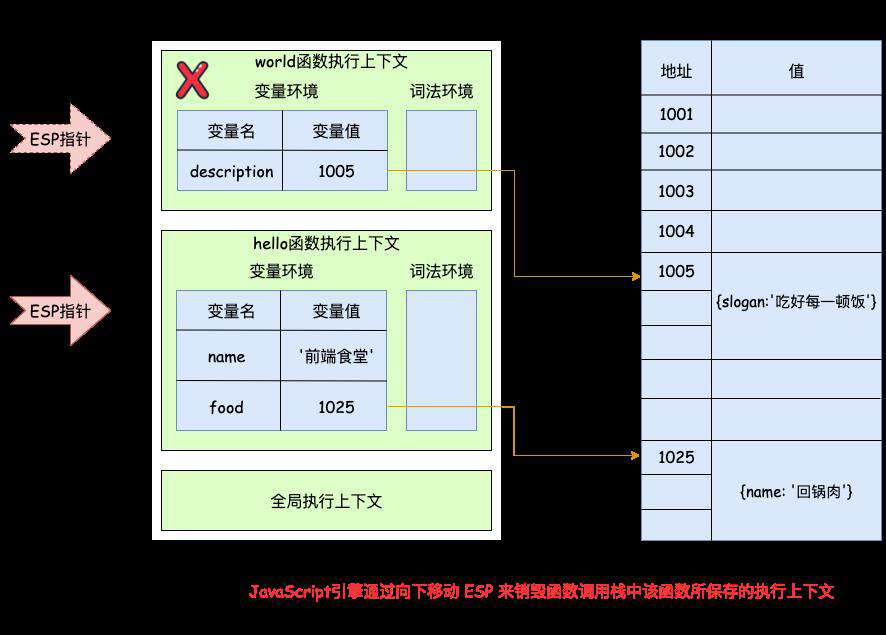
栈中的垃圾回收比较简单,当一个函数执行结束后,JavaScript 引擎会通过向下移动 ESP 来销毁函数调用栈中所保存的执行上下文,ESP 就是记录当前执行状态的指针。
堆中的垃圾数据
先来看两个概念,能够帮助我们更好的理解堆中的垃圾回收操作。
代际假说
堆中的垃圾回收策略都是建立在代际假说的基础之上,代际假说有以下两个特点:
- 大部分对象在内存中存在的时间很短,简单来说,就是很多对象一经分配内存,很快就变得不可访问。
- 不死的对象,会活得更久。
分代收集
在 Chrome 浏览器引擎 V8 中会把堆分为新生代和老生代两个区域,如下图所示:
顾名思义,生存时间短的对象放在新生区中,生存时间久的对象放在老生区中。
堆中的垃圾回收需要用到垃圾回收器,分为主垃圾回收器和副垃圾回收器。
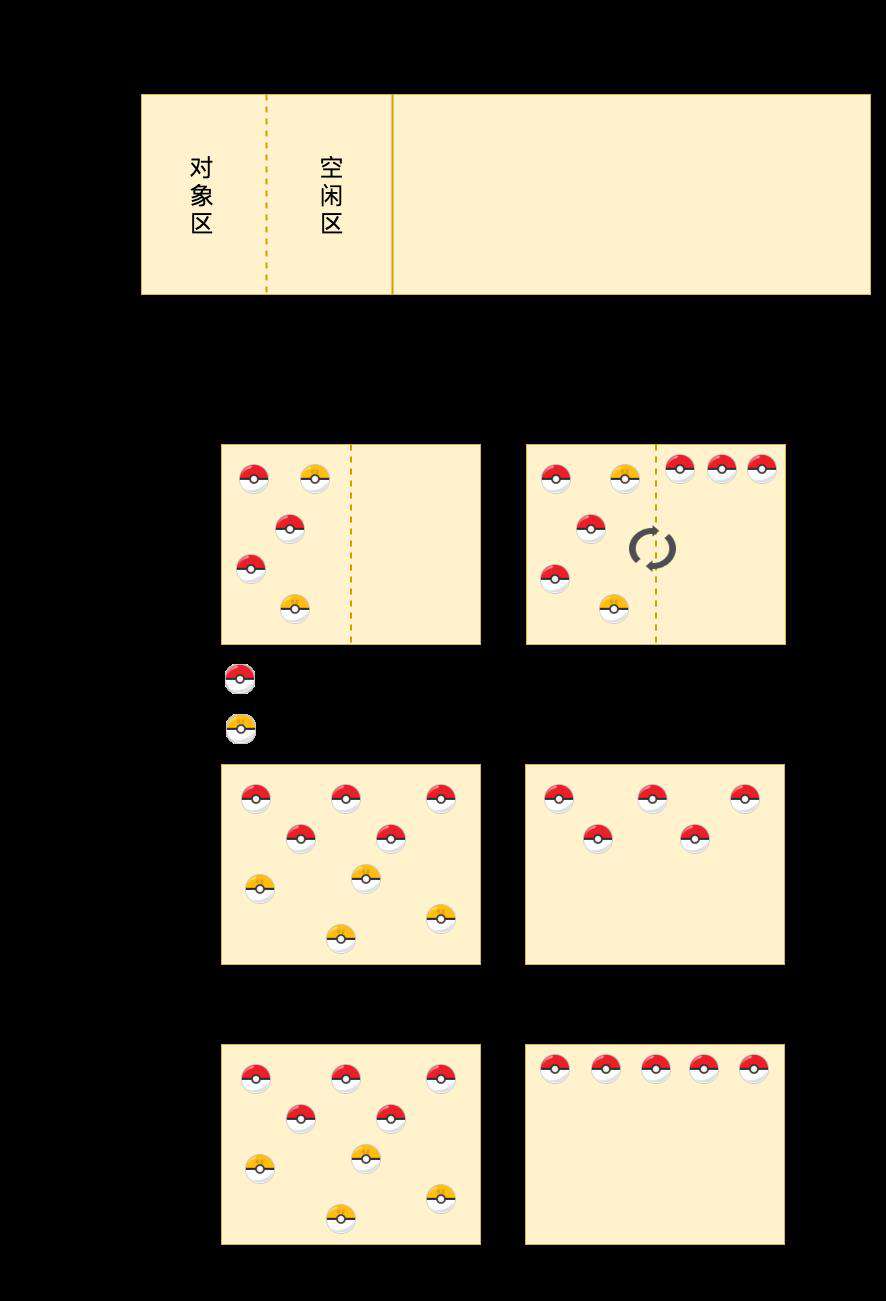
副垃圾回收器
负责新生区的垃圾回收,新生区区域不大(为了执行效率),回收频繁。
新生区中使用了 Scavenge 算法,该算法会把新生区的空间划分为两个区域,一半是对象区域,一半是空闲区域。
副垃圾回收器的工作流程如下:
- 首先对对象区域中的垃圾进行标记。
- 标记完成后,副垃圾回收器会将存活的对象复制到空闲区域中,为了避免产生内存碎片,还需要进行有序的排列,有序排列相当于内存整理。
- 完成复制后,将对象区域和空闲区域进行翻转,就完成了垃圾回收的操作。
翻转的这种操作可以让对象区和空闲区无限重复的使用,不过由于新生区空间并不大,很容易会被存活的对象塞满。所以 V8 引擎采用了对象晋升的策略,经过两次垃圾回收后依然还能存活的对象会被晋升到老生区中。
主垃圾回收器
负责老生区中的垃圾回收,老生区中对象占用空间大,对象存活时间长。
除了上文说到的新生区中晋升的对象,一些大的对象也会直接被分配到老生区。
主垃圾回收器是使用了标记 - 清除(Mark-Sweep)的算法,工作流程如下:
- 首先是标记阶段,从一组根元素开始递归遍历,能到达的元素就是活动对象,否则就是垃圾。
- 然后使用标记 - 清除算法进行垃圾回收,不过回收后会产生大量不连续的内存碎片。
- 于是又产生了另外一种算法
标记 - 整理(Mark-Compact),整理时可以让存活的对象都向一端移动,然后直接清除掉端边界以外的内存。
全停顿
垃圾回收操作会暂停 JavaScript 的运行,回收完毕后才会恢复执行,这种行为就是全停顿。
为了降低全停顿所带来的卡顿,V8 引擎采用了增量标记(Incremental Marking) 算法进行优化,将标记过程分为一个个小任务,这些小任务的执行时间比较短,可以穿插在其他的 JavaScript 任务中间执行,这样就不会有明显的卡顿了。
当然,V8 所采用的优化方案不只这一种,而是多种方案综合使用的,除了增量回收还有并行回收、并发回收等。
- 并行回收:垃圾回收器会使用多个辅助线程来并行执行垃圾回收
- 并发回收:回收线程在执行 JavaScript 的过程中,辅助线程在后台执行垃圾回收
如果你了解 React 的 Concurrent 模式中时间切片的原理,它的实现思想是不是与增量标记算法有异曲同工之妙呢。
04 核心网页指标 Core Web Vitals
Google 大佬推出了 Core Web Vitals:目的是为了更好的简化场景,帮助网站专注于最重要的指标以提升用户体验。
在 2020 年主要关注三个方面:加载、交互性和视觉稳定性,并包括以下指标:

衡量所有 Core Web Vitals 最简单的方法就是使用 web-vitals 库,使用起来就像调用单个函数一样简单。
import {getCLS, getFID, getLCP} from 'web-vitals';
getCLS(console.log);
getFID(console.log);
getLCP(console.log);
也可以使用 Chrome 插件 Web Vitals Chrome 来帮助我们测量这些指标。
如果想要直接通过 Web API 来获取这些指标的话可以参考下面的获取方法:
- 在JavaScript中测量LCP
- 在JavaScript中测量FID
- 在JavaScript中测量CLS
LCP Largest Contentful Paint 最大内容绘制
LCP用于衡量标准报告视口内可见的最大图像或文本块的渲染时间,为了提供良好的用户体验,网站应努力在开始加载页面的前2.5 秒内进行“最大内容绘制”。
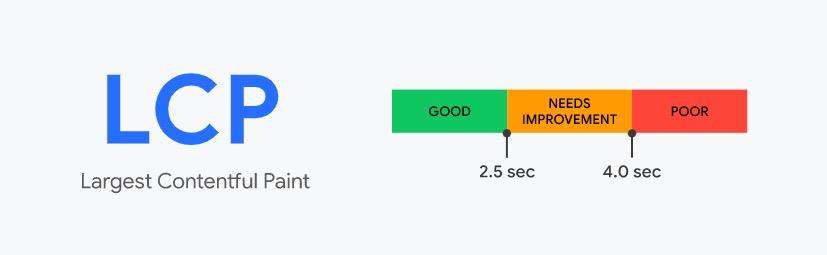
优化LCP方案
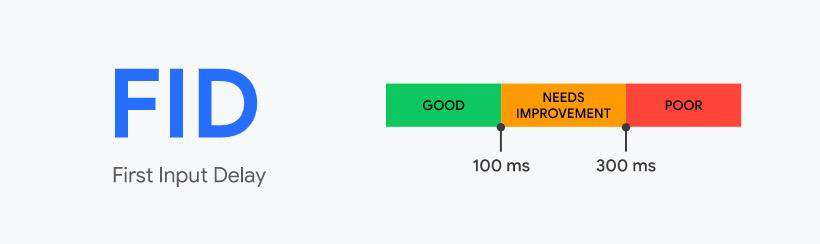
FID First Input Delay 首次交互延迟
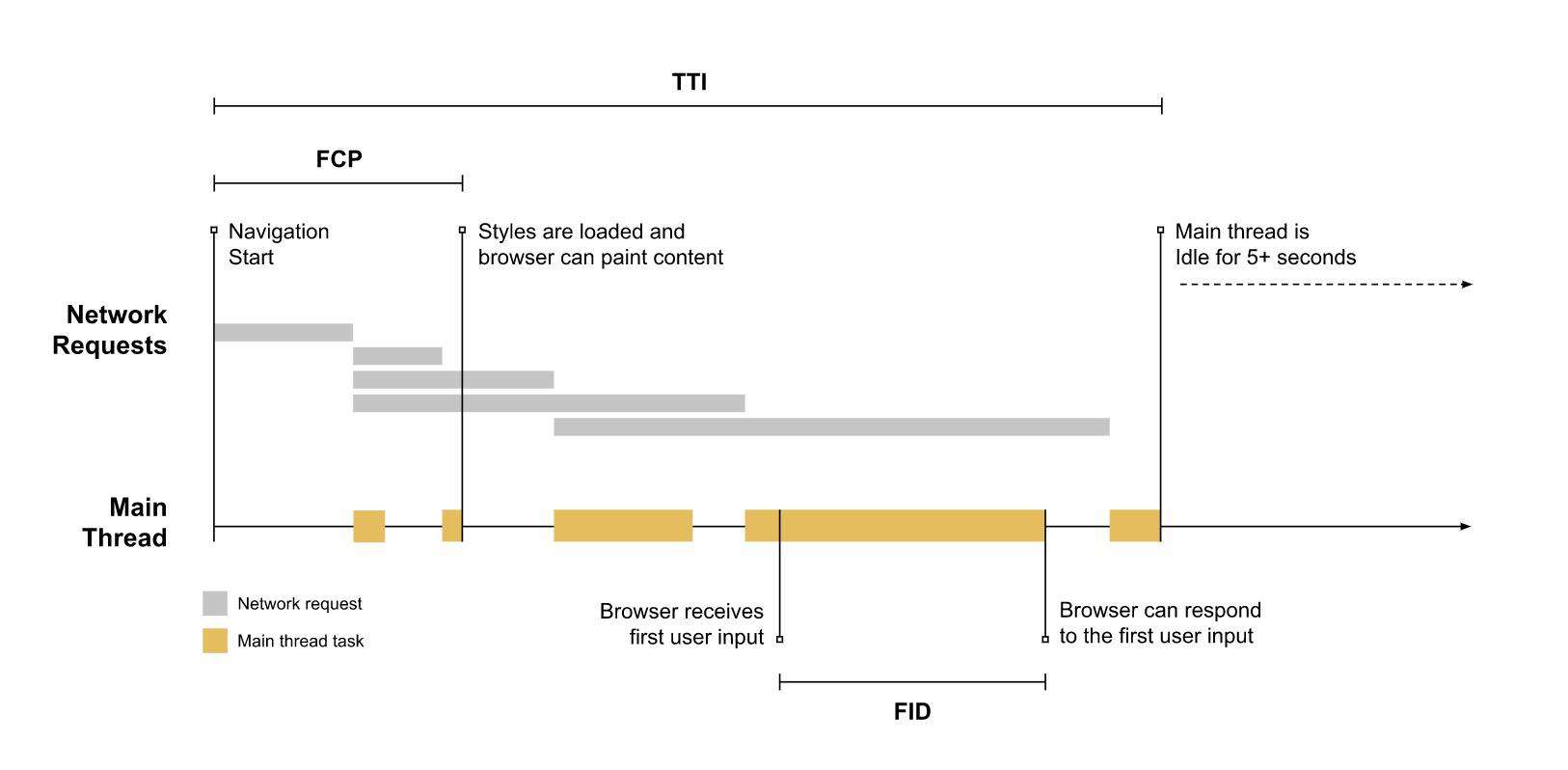
FID用于衡量从用户第一次与页面进行交互到浏览器实际上能够开始处理事件处理程序的时间。为了提供良好的用户体验,网站应努力使首次输入延迟小于 100 毫秒。
下图中米色方块代表主线程处于忙碌阶段,如果此时用户进行输入,则它必须等待任务完成时才能响应输入,等待的时间也就是此页面上该用户的 FID 值。
优化FID方案
CLS Cumulative Layout Shift 累积布局偏移
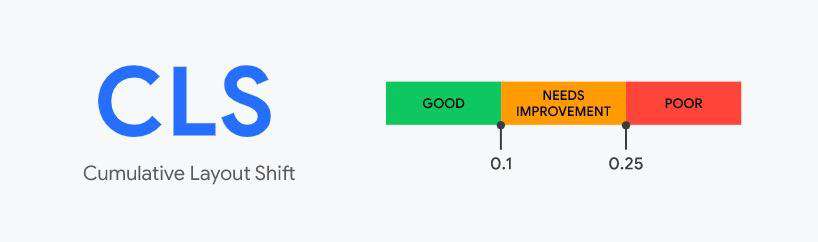
CLS用于测量在页面的整个生命周期中发生的每一个意外的布局移动,它代表所有单独布局转移分数的总和。为了提供良好的用户体验,网站应努力使CLS分数小于0.1。
布局偏移分数
浏览器将查看视口大小以及两个渲染帧之间的视口中不稳定元素的移动。
布局偏移分数是该运动的两个指标的乘积:影响分数和距离分数
layout shift score = impact fraction * distance fraction
影响分数
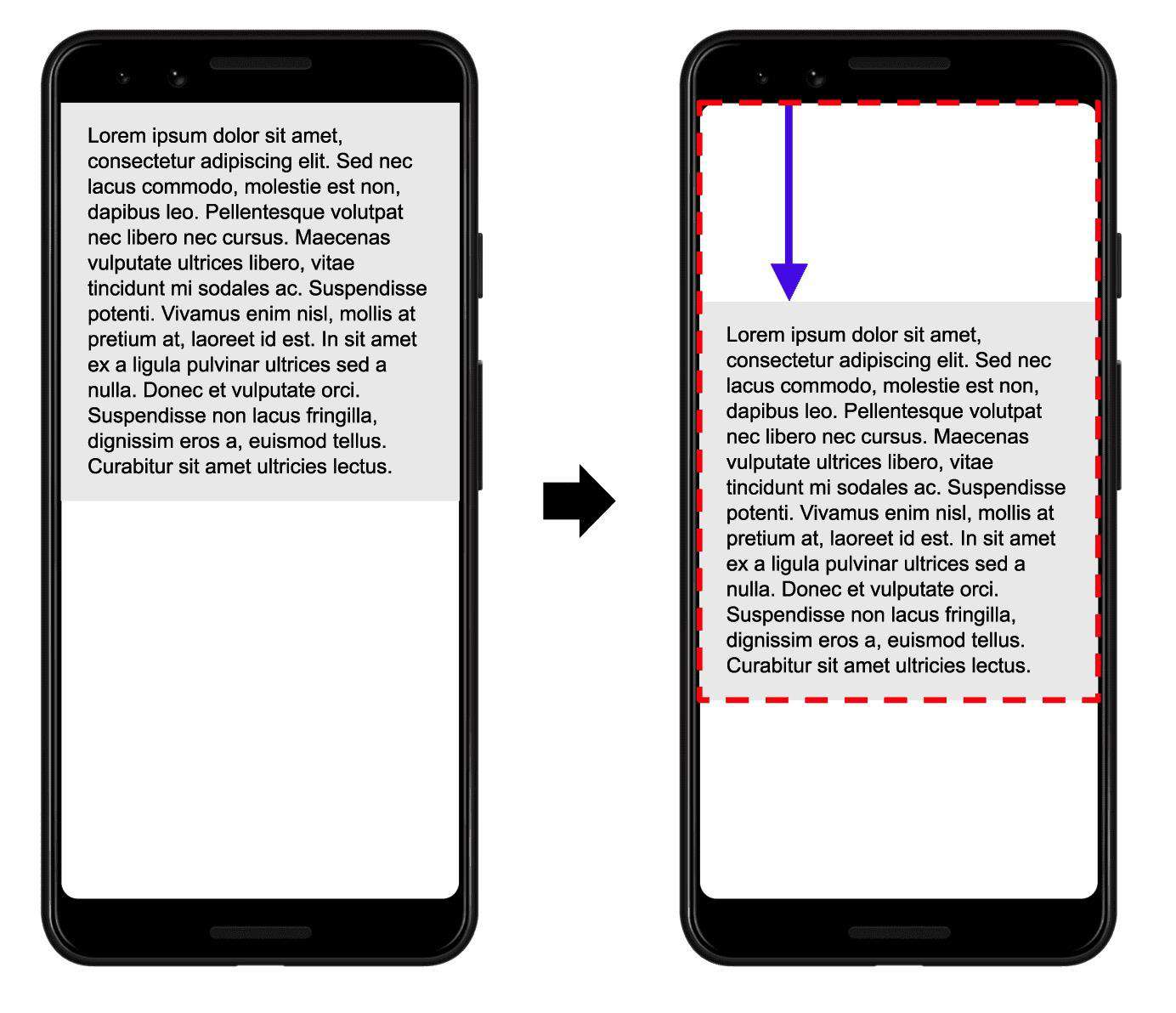
前一帧和当前帧的所有不稳定元素的可见区域的并集(占视口总面积的一部分)是当前帧的影响分数。
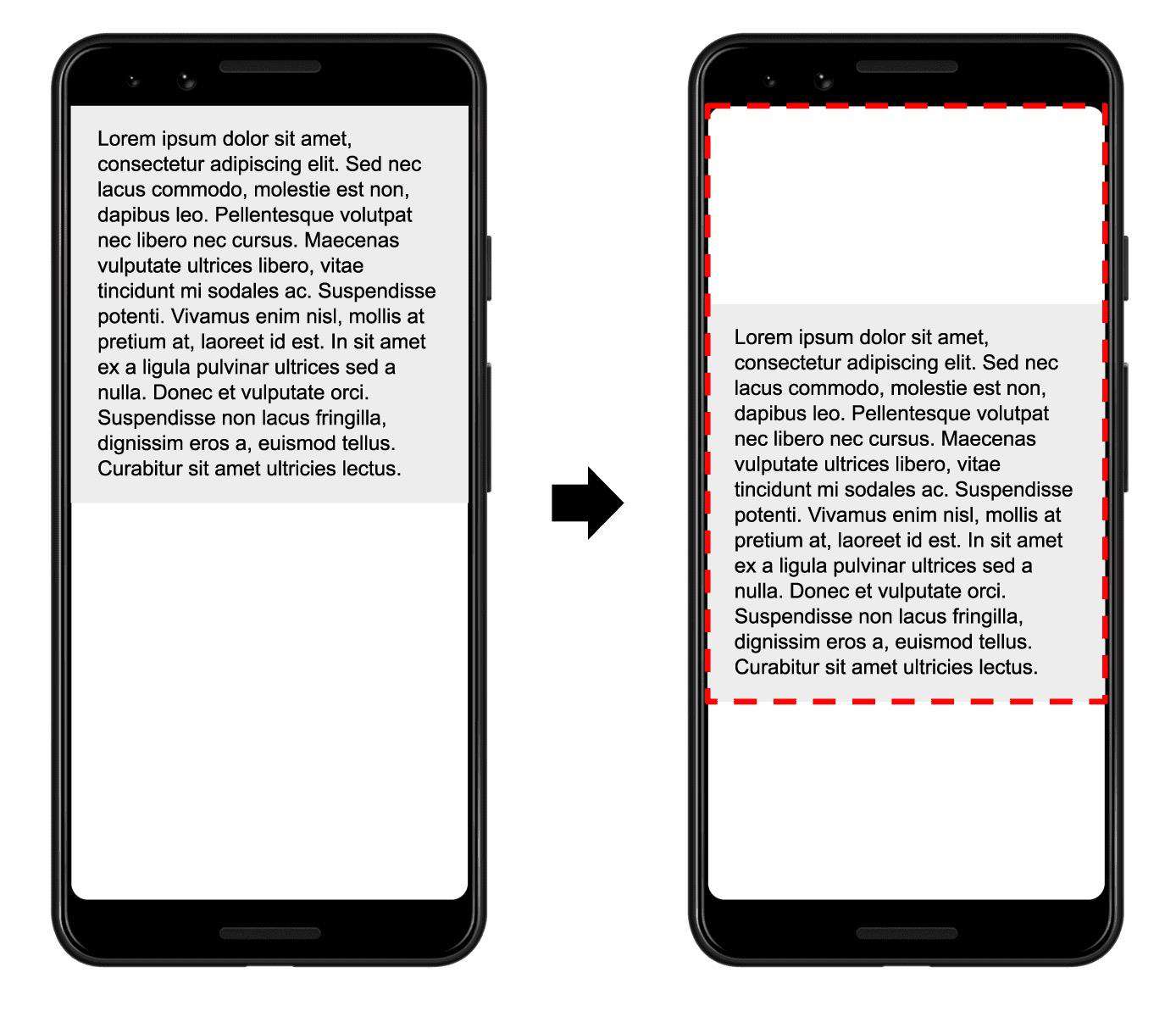
在上图中,有一个元素在一帧中占据了视口的一半。然后,在下一帧中,元素下移视口高度的 25%。红色的虚线矩形表示两个帧中元素的可见区域的并集,在这种情况下,其为总视口的 75%,因此其影响分数为 0.75。
距离分数
布局偏移分数方程的另一部分测量不稳定元素相对于视口移动的距离。距离分数是任何不稳定元素在框架中(水平或垂直)移动的最大距离除以视口的最大尺寸(宽度或高度,以较大者为准)。
在上图中,最大视口尺寸是高度,不稳定元素已经移动了视口高度的 25%,所以距离分数是 0.25。
所以,布局偏移分数:0.75 * 0.25 = 0.1875
优化CLS方案
好了,本文到这里就结束了,文中参考的链接都整理到了下面,大家可以自行查阅。
站在巨人的肩膀上
- 图解 Google V8 李兵
- 浏览器工作原理与实践 李兵
- Core Web Vitals web.dev/vitals/
- web-vitals github.com/GoogleChrom…
- LCP web.dev/lcp/
- FID web.dev/fid/
- CLS web.dev/cls/
- 优化FID方案 web.dev/optimize-fi…
- 优化LCP方案 web.dev/optimize-lc…
- 优化CLS方案 web.dev/optimize-cl…
爱心三连击
1.如果你觉得食堂酒菜还合胃口,就点个赞支持下吧,你的赞是我最大的动力。
2.关注公众号前端食堂,吃好每一顿饭!
3.点赞、评论、转发 === 催更!

常见问题FAQ
- 免费下载或者VIP会员专享资源能否直接商用?
- 本站所有资源版权均属于原作者所有,这里所提供资源均只能用于参考学习用,请勿直接商用。若由于商用引起版权纠纷,一切责任均由使用者承担。更多说明请参考 VIP介绍。
- 提示下载完但解压或打开不了?
- 找不到素材资源介绍文章里的示例图片?
- 模板不会安装或需要功能定制以及二次开发?



![[浏览器工作原理与实践] Day 03 | HTTP 请求流程](/ripro/timthumb.php?src=https://img.qiyuandi.com/img/20210621/[llrgm5qpnlh1y0a.jpg&h=200&w=300&zc=1&a=c&q=100&s=1)

发表评论
还没有评论,快来抢沙发吧!