首先,回顾一下,上一篇文章的内容,我们首先介绍了content概念,知道了我们最终要的结果是显示在屏幕上的像素,了解了浏览器渲染的目标【html/css/js 转换到 正确的opengl调用来调整像素的样式】,了解了Style,了解了Layout,了解了Panit,现在所有的绘制操作已经记录在显示项列表(display items)中了,那么现在就可以开始本篇文章的阅读。
资料:docs.google.com/presentatio…
读前提要
因为浏览器渲染机制的两篇文章是基于前面资料中的ppt为出发点研究,所以文章的顺序没有按照完整的渲染顺序编写,读起来体验应该比较一般,文章中也可能存在或多或少的问题,但是我会在后续进行修正,并梳理出一篇清晰易懂的文章。
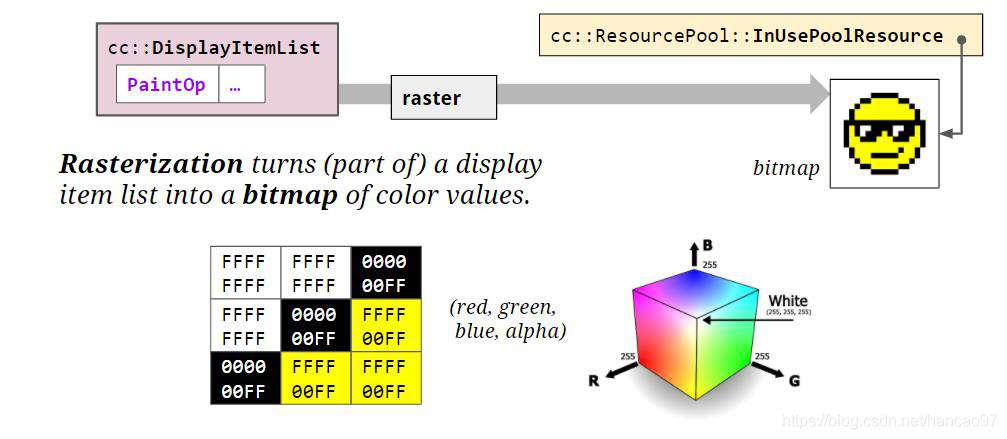
raster光栅化
显示项列表中的绘制操作由一个称为光栅化的进程执行。光栅化可以将显示项列表转换成颜色值的位图。生成的位图中每个单元都保存着这个位图的颜色值与透明度的编码(如下图FFFFFFF,其实就是RGBA的16进制表示)。

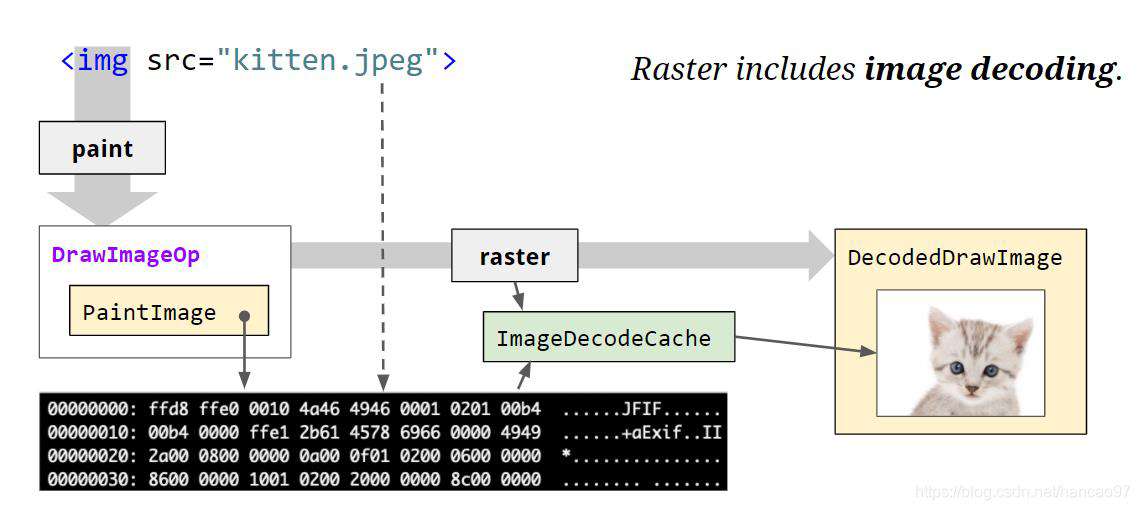
光栅化这个过程还会去解码嵌入在页面中的图像资源,绘制操作会引用压缩的数据(比如JPEG,PNG等等),而光栅化会调用适当的解码器对其进行适当的解压。
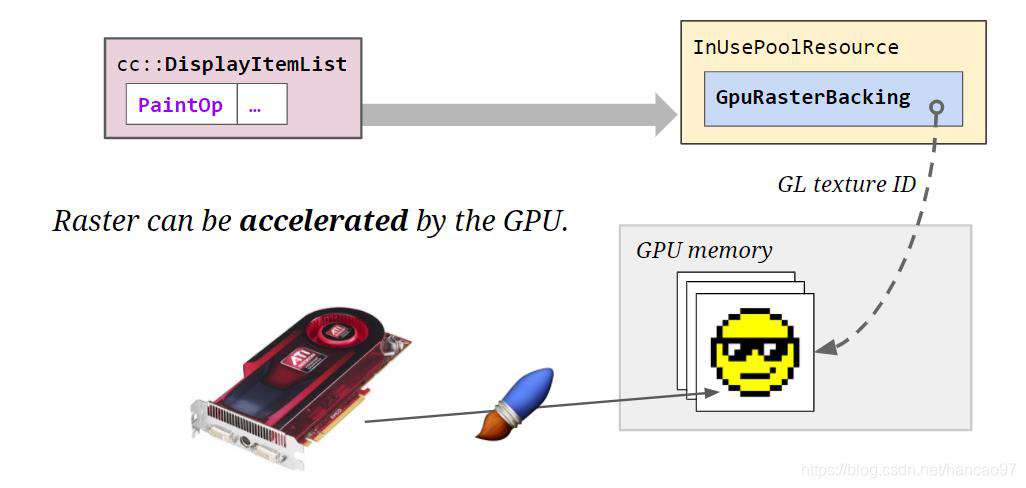
- 过去的GPU只是作为一个内存,这些内存被OpenGL纹理对象引用,我们会将栅格化的位图放到主内存里,然后上传到GPU,用来分担内存压力。
- 现在的GPU也可以执行生成位图的命令(“加速光栅化”),这属于硬件加速,但是无论是硬件光栅化还是软件光栅化,本质都是生成了某种内存中像素的位图。
现在仅仅是位图存储在了内存中,像素还没有显示在屏幕上。GPU光栅化并不是直接调用的GPU,而是通过Skia图形库(谷歌维护的2D图形库,在Android,Flutter,Chromium都有使用)。
Skia提供了某种抽象层,可以理解更加复杂的东西,比如贝塞尔曲线。Skia是开源的,装载在Chrome二进制文件中,而不是存在于一个单独的代码库中。当需要光栅化的显示项(display item)时,会先去调用SkCanvas上面的方法,他是Skia的调用入口,SkCanvas提供了Skia内部更多的抽象,在硬件加速的时候,它会构建另一个绘图操作缓冲区,然后对其进行刷新,在栅格化任务结束时,通过flush操作,我们获得了真正的GL指令,GL指令运行在GPU进程中。
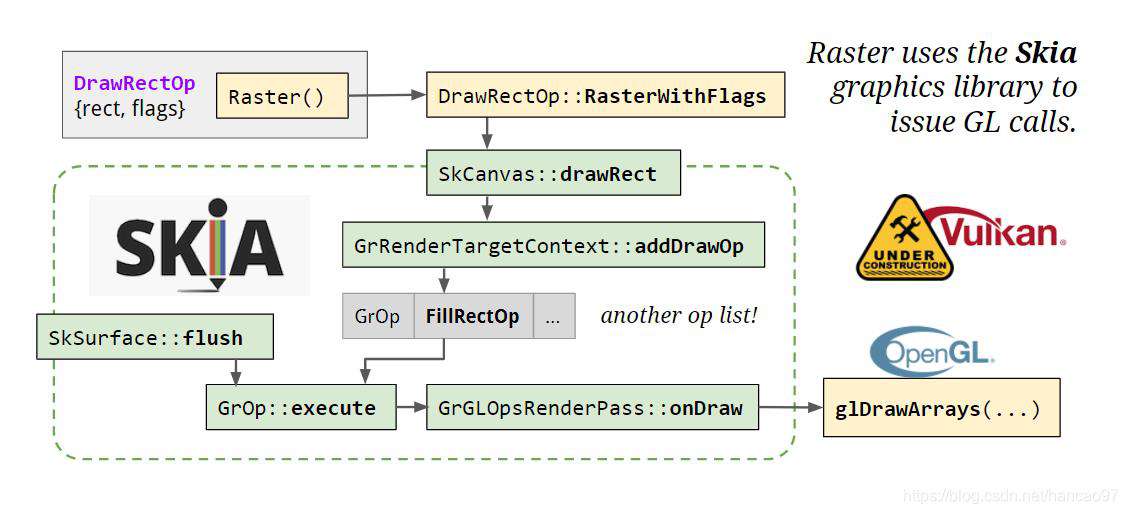
Skia和GL指令可以运行在不同的进程中,也可以运行在同一个进程,于是产生了两种调用方式。
- In Process Raster
- Out of Process Raster
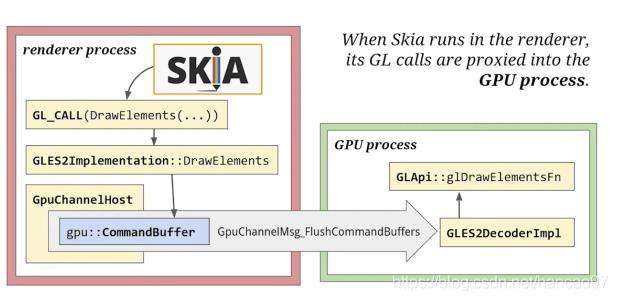
1.In Process Raster
老版本采用了这种方式,Skia是在渲染进程中执行的,他会生产GL调用指令,GPU有单独的GPU process,这种模式下Skia没办法直接进行渲染系统的调用。在初始化Skia的时候,会给它一个函数指针表(这个指针指向了GL API,但不是真正的OpenGL API,而是Chromium提供的代理)。下面的GpuChannelMsg_FlushCommandBuffers是一个命令缓冲区,会将函数指针表转换成真正的OpenGl API。
单独的GPU进程有利于隔离GL操作,提升稳定性和安全性,这种模式也成为沙箱机制(就是把不安全操作放在单独的进程去执行)。
(图中 GLES2后端映射到桌面的OpenGL 2.1)
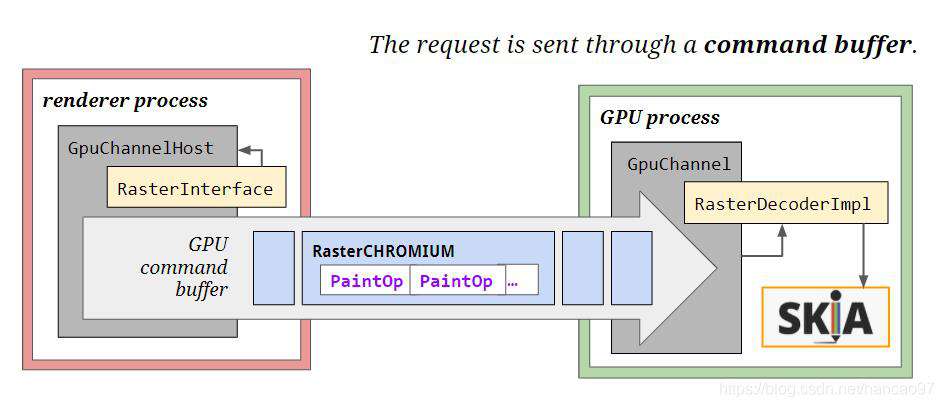
2.Out of Process Raster
新版本把绘制的操作都放在了GPU进程里面,在GPU进程中去运行Skia,可以提升性能。
光栅化的绘制操作包装在GPU的命令缓冲区在发送到IPC通道(进程间通信方式)。
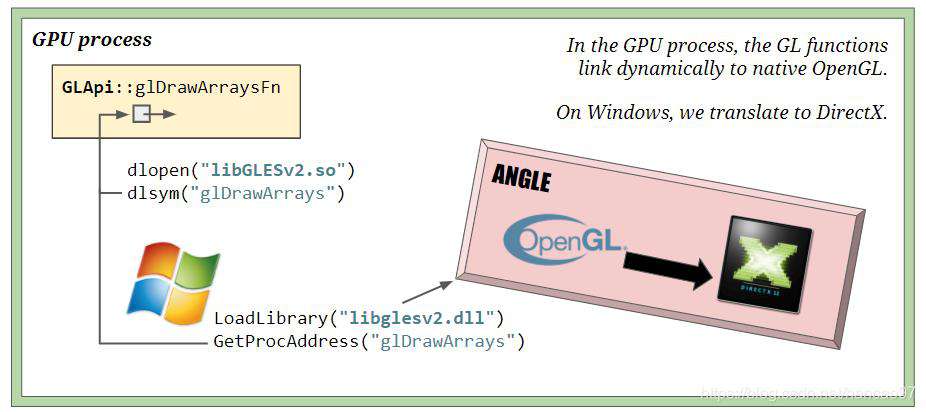
接下来就是去执行GL指令,GL指令一般是由底层的so库提供的,在Windows平台还会被转换成DirectX(微软的图形API,用于图形加速)
问题
现在我们从content 一点一点的讲到了如何转换到内存里面的像素,但是页面的呈现并不是一个静态的过程(页面滚动,js脚本执行,动画等等。。。),在发生变化的时候去重新运行整个管道代价是十分昂贵的。
那么我们如何去提高性能呢???

Compositing Update
在Layout操作完成之后,按理是去进行Paint,但是我们直接Paint代价是十分昂贵的,于是引入了一个图层合成加速的概念。
那么什么是图层合成加速?
图层合成加速是把整个页面按照一定规则划分成多个图层,在渲染的时候,只要操作必要的图层,其他的图层只要参与合成就好了,以这种方式提高了渲染的效率,完成这个工作的线程叫做:Compositor Thread(合成器线程),合成器线程还具备处理事件输入的能力,比如滚动事件,但是如果在js中进行了事件的注册和监听,它会把输入事件转发给主线程。
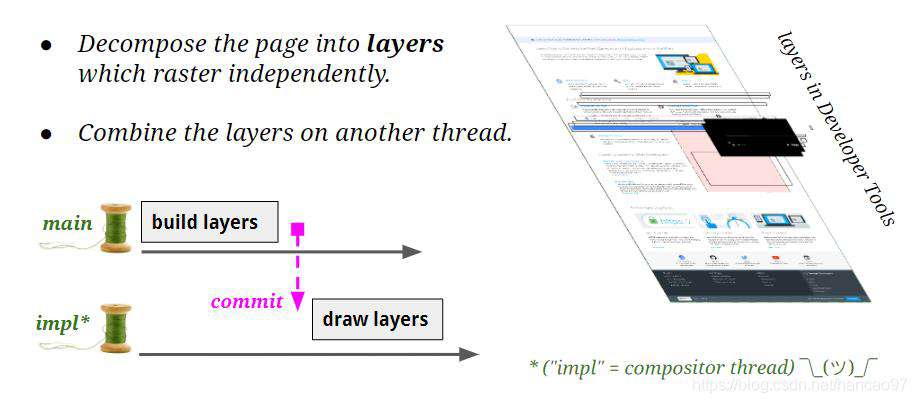
主线程把页面拆分成多个可以独立光栅化的层,并在另一个线程(合成器线程)中将这些层合并。
这使得某些RenderLayer拥有自己独立的缓存,它们被称作合成图层(Compositing Layer),内核会为这些RenderLayer创建对应的GraphicsLayer。
- 拥有自己的GraphicsLayer的RenderLayer在绘制的时候会绘制在自己的缓存里面
- 没有自己的GraphicsLayer的RenderLayer会向上查找父节点的GraphicsLayer,直到RootRenderLayer(他总是有自己的GraphicsLayer)为止,然后绘制在有GraphicsLayer的父节点的缓存里面。
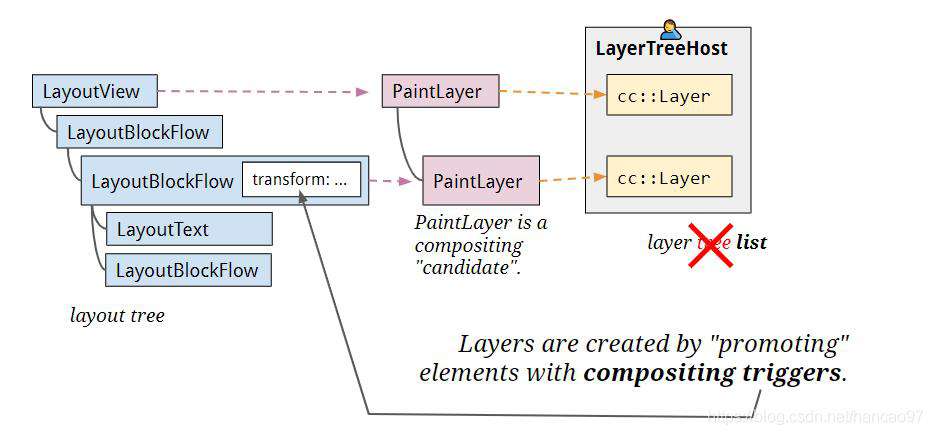
这样就形成了与RenderLayer Tree对应的GraphicsLayer Tree。当Layer的内容发生变化时,只需要更新对应的GraphicsLayer即可,而单一缓存架构下,就会更新整个图层,会比较耗时。这样就提高了渲染的效率。但是过多的GraphicsLayer也会带来内存的消耗,虽然减少了不必要的绘制,但也可能因为内存问题导致整体的渲染性能下降。因而图层合成加速追求的是一个动态的平衡。
图层化的决策目前是由Blink来负责,根据DOM树生成一个图层树,并以DisplayList记录每个图层的内容。
了解了图层合成加速的概念以后,我们再来看看发生在Layout操作之后的Compositing update(合成更新),合成更新就是为特定的RenderLayer创建GraphicsLayer的过程,如下所示:

Prepaint
属性树:在描述属性的层次结构这一块,之前的方式是使用图层树的方式,如果父图层具有矩阵变换(平移、缩放或者透视)、裁剪或者特效(滤镜等),需要递归的应用到子节点,时间复杂度是O(图层数),这在极端情况下会有性能问题。
于是,为了提高性能,引入了属性树的概念,合成器提供了变换树,裁剪树,特效树等。每个图层都有若干节点id,分别对应不同属性树的矩阵变换节点、裁剪节点和特效节点。这样的时间复杂度就是O(要变化的节点),如下所示:
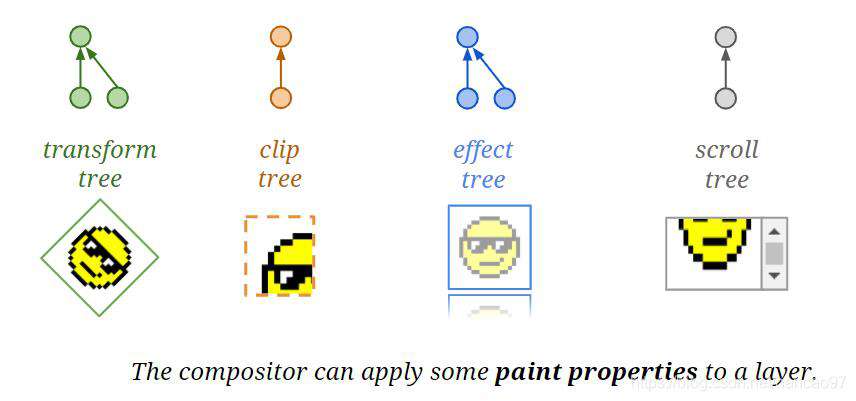
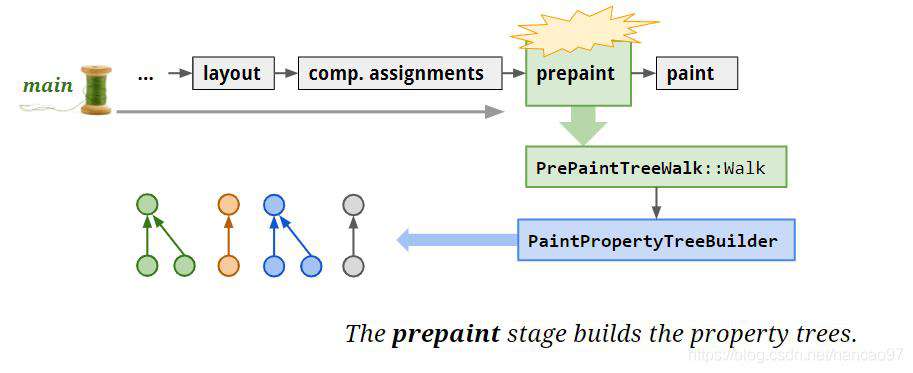
prepaint的过程其实就是构建属性树的过程。
commit
前面提到了我们在paint这个阶段前,多了两件事情要做,先把页面拆成了很多图层,还构建了属性树。paint阶段做了什么?paint阶段把绘制的操作放在了display item里面。
下面就来到了commit阶段,这个阶段会更新图层和属性树的副本到合成器线程。
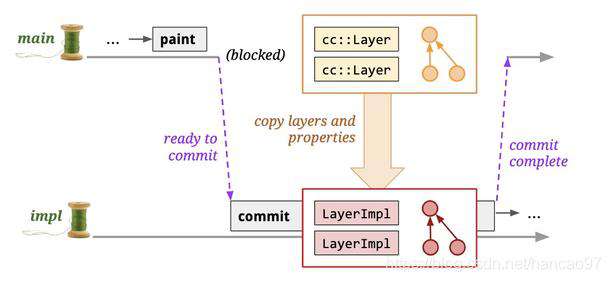
Tiling
合成器线程接收到数据之后,不会立即开始合成,而是把图层进行分块,这里涉及到了一个叫做“分块渲染”的技术,分块渲染会将网页的缓存分成一块一块的,比如256*256的块,之后进行分块渲染。
为什么要分块渲染?
- .GPU合成通常是使用OpenGL ES贴图实现的,这时候的缓存实际就是纹理(GL Texture),很多GPU对纹理的大小是有限制的,比如长宽必须是2的幂次方,最大不能超过2048或者4096等。无法支持任意大小的缓存。
- 分块缓存,方便浏览器使用统一的缓冲池来管理缓存。缓冲池的小块缓存由所有WebView共用,打开网页的时候向缓冲池申请小块缓存,关闭网页是这些缓存被回收。
tiling图块也是栅格化的基本单位,栅格化会根据图块与可见视口的距离安排优先顺序进行栅格化。离得近的会被优先栅格化,离得远的会降级栅格化的优先级。这些图块拼接在一起,就形成了一个图层,如下所示:
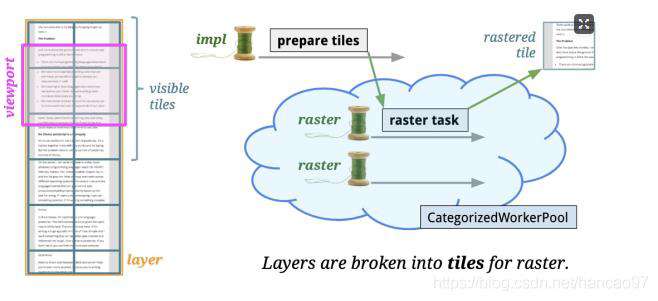
Activate
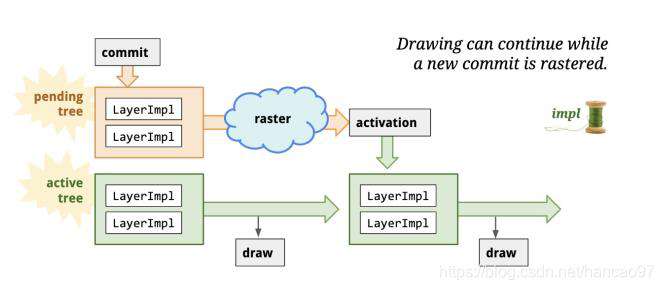
在Commit之后,Draw之前有一个Activate操作。Raster和Draw都发生在合成器线程里的Layer Tree上,但是我们知道Raster操作是异步的,有可能需要执行Draw操作的时候,Raster操作还没完成,这个时候就需要解决这个问题。
它将LayerTree分为了
- PendingTree:负责接收commit,然后将Layer进行Raster操作
- ActiveTree:会从这里取出光栅化好的Layer进行draw操作。
主线程的图层树由LayerTreeHost拥有,每个图层以递归的方式拥有其子图层。Pending树、Active树、Recycle树都是LayerTreeHostImpl拥有的实例。这些树被定义在cc/trees目录下。之所以称之为树,是因为早期它们是基于树结构实现的,目前的实现方式是列表。
Draw
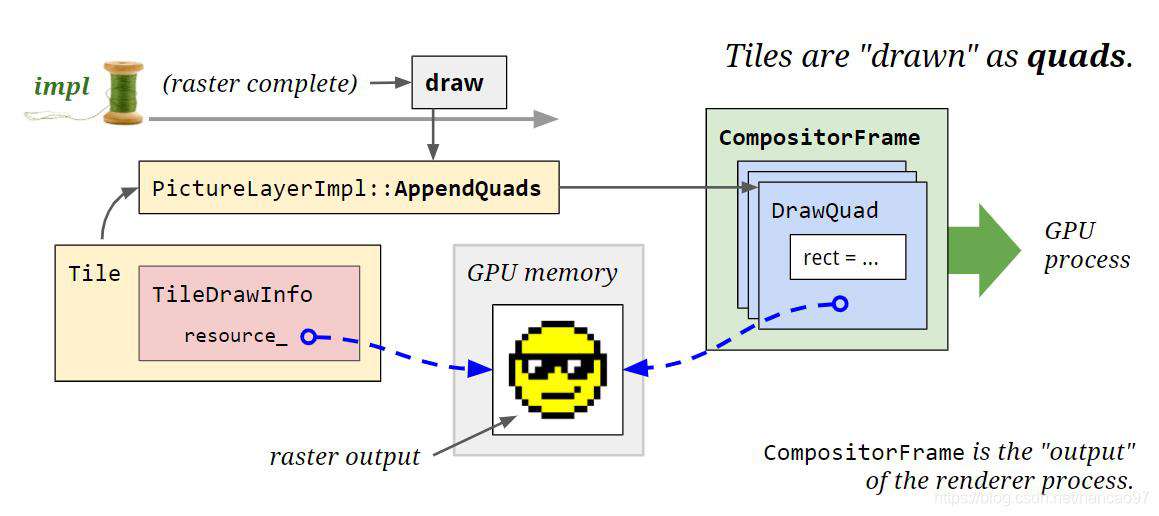
好,现在到了Draw这个步骤,当每个图块都被光栅化之后,合成器线程会为每个图块生成draw quads(在屏幕的指定位置绘制图块的指令,也包含了属性树里面的变换,特效等操作),这些draw quads会被封装在CompositorFrame对象里面,CompositorFrame对象也是Render Process的产物,它会被提交到Gpu Process中,我们平时提到的60fps输出帧率指的帧其实就是CompositorFrame。
Draw指的就是 把光栅化的图块,转换成draw quads的过程。
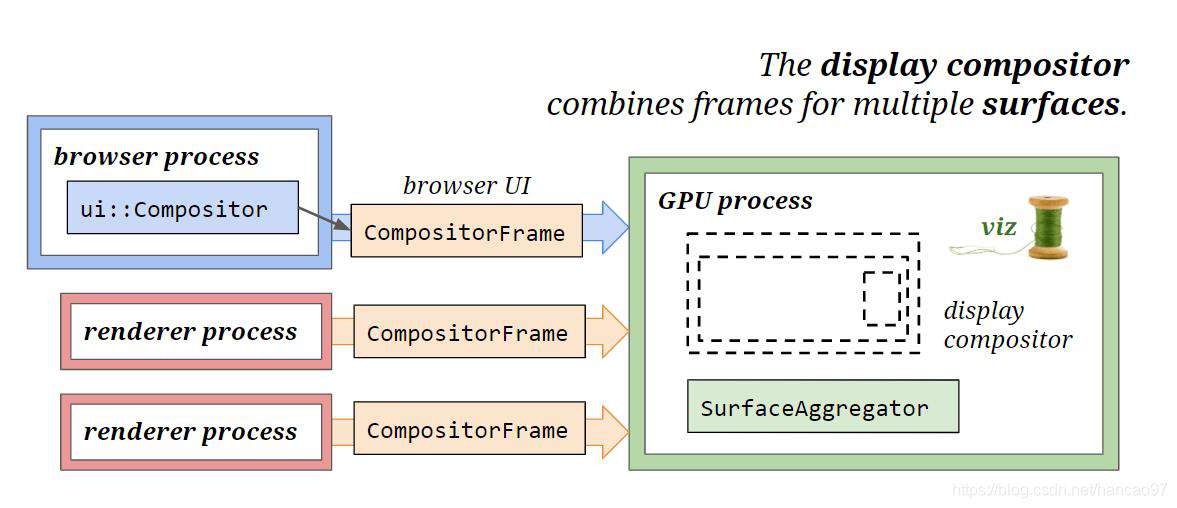
Display Compositor
Display
Draw操作完成之后,就生成了CompositorFrame,它会被输出到Gpu process,它会从多个来源的Render Process接收CompositorFrame。
多个来源:
- Browser Process也有自己的Compositor来生成Compositor Frame,这些一般是用来绘制Browser UI(导航栏,窗口等)
- 每次创建tab或者使用iframe,会创建一个独立的Render Process。
Display Compositor运行在Viz Compositor thread,Viz会调用OpenGL指令来渲染Compositor Frame里面的draw quads,把像素点输出到屏幕上。
VIz也是双缓冲输出的,它会在后台缓冲区绘制draw quads,然后执行交换命令最终让它们显示在屏幕上。
双缓冲机制:
在渲染的过程中,如果只对一块缓冲区进行读写,这样会导致一方面屏幕要等待去读,而GPU要等待去写,这样要造成性能低下。一个很自然的想法是把读写分开,分为:
- 前台缓冲区(Front Buffer):屏幕负责从前台缓冲区读取帧数据进行输出显示。
- 后台缓冲区(Back Buffer):GPU负责向后台缓冲区写入帧数据。
这两个缓冲区并不会直接进行数据拷贝(性能问题),而是在后台缓冲区写入完成,前台缓冲区读出完成,直接进行指针交换,前台变后台,后台变前台,那么什么时候进行交换呢,如果后台缓存区已经准备好,屏幕还没有处理完前台缓冲区,这样就会有问题,显然这个时候需要等屏幕处理完成。屏幕处理完成以后(扫描完屏幕),设备需要重新回到第一行开始新的刷新,这期间有个间隔(Vertical Blank Interval),这个时机就是进行交互的时机。这个操作也被称为垂直同步(VSync)。
垂直同步也会在后续进行介绍。
viz
viz是做什么的?
在 Chromium 中 viz 的核心逻辑运行在 GPU 进程中,负责接收其他进程(渲染进程?)产生的 viz::CompositorFrame(简称 CF),然后把这些 CF 进行合成,并将合成的结果最终渲染在窗口上。
CF是什么?
一个 CF 对象表示一个矩形显示区域中的一帧画面。内部存储了 3 类数据,分别是 CompositorFrameMetadata, TransferableResoruce 和 RenderPass/DrawQuad,如下图所示:
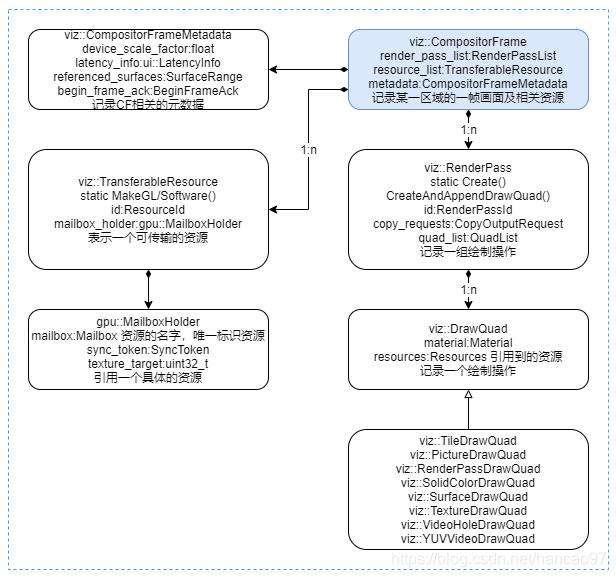
- CompositorFrameMetadata:CF的元数据,比如画面的缩放级别,滚动区域。。。
- TransferableResoruce :CF引用到的资源。
- RenderPass/DrawQuad:CF包含的绘制操作。
viz::RenderPass由一系列相关的viz::DrawQuad构成。
CF 是 viz 中的核心数据结构,它代表某块区域中UI的一帧画面,使用 DrawQuad 来存储 UI 要显示的内容。它代表了 viz 运行时的数据流。
CF合成
CF 合成指的是viz线程把 CF 中的内容或者多个 CF 合成到一起,形成一个完整的画面。
CF渲染
CF 的渲染主要由 viz::DirectRenderer 和 viz::OutputSurface 负责,他们将合成的结果渲染到程序选择的渲染目标上去。
CC
现在我们在统一的梳理一下cc的功能作用以及cc的工作流程。
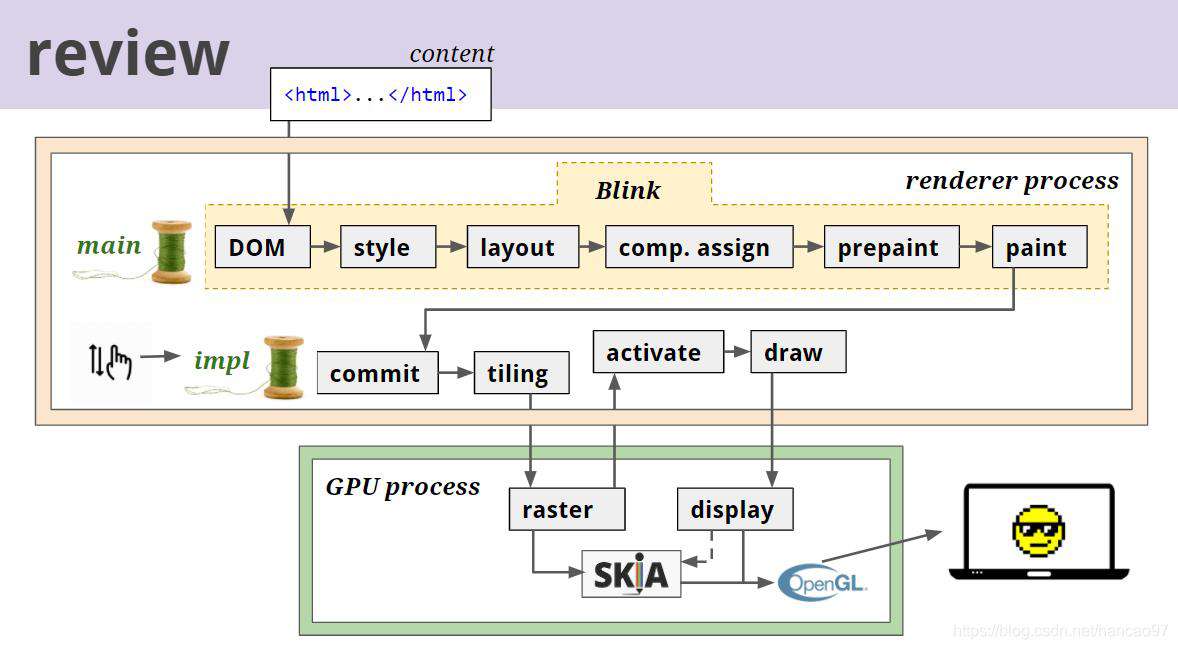
我们先回顾一下,看看上面这个图,Blink 进行了DOM,Style,Layout,comp.assign,prepaint,paint。
我们可以发现,Paint是blink和cc对接的桥梁。
整体的流程其实可以 理解成:
Blink一顿操作 -> paint生成了cc模块的数据源(cc:layer)->commit->(Tiling->)Raster->Active->draw(submit)->Viz(呈像)
就是Blink一顿操作,并在paint阶段生成cc的数据源,cc进行一系列操作并最终在draw阶段将结果(CF)提交给viz。也就是说,Blink负责网页内容绘制,cc负责将绘制的结果合成并提交给viz。
cc的架构设计
cc的设计相对比较简单,我们可以把他理解成一个多线程调度的异步流水线,运行在 Browser 进程中的 cc 负责合成浏览器非网页部分的 UI,运行在 Renderer 进程中的 cc 负责网页的合成。
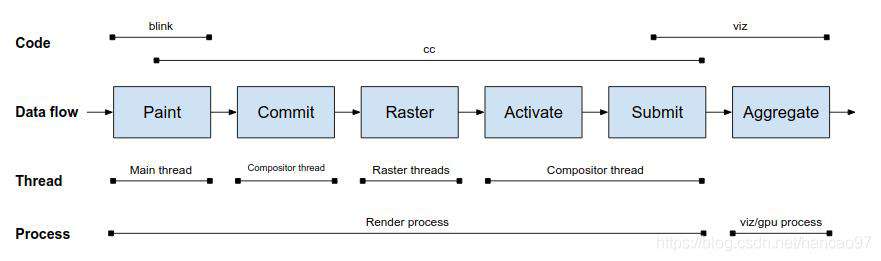
在chromium.googlesource.com/chromium/sr… how cc works官网有这样一张图,我觉得可以很好的反应cc的核心逻辑。
cc的多线程体现在在不同的阶段,cc运行在不同线程中,Paint 运行在 Main 线程,Commit,Activate,Submit 运行在 Compositor 线程,而 Raster 运行在专门的 Raster 线程。
下面我们开始对cc流水线的各个阶段进行分析。
Paint
Paint阶段会产生cc的数据源(cc:layer树),一个cc:layer会表示一个矩形区域的UI,它有很多子类,用于存储不同类型的UI数据:
- cc::PictureLayer。用于实现自绘型的UI组件,比如上层的各种 Button,Label 等都可以用它来实现。它允许外部通过实现
cc::ContentLayerClient接口提供一个cc::DisplayItemList对象,它表示一个绘制操作的列表,记录了一系列的绘制操作,比如画线,画矩形,画圆等。通过cc::PaintCanvas接口可以方便的创建复杂的自绘 UI。cc::PictureLayer还是唯一需要 Raster 的cc::Layer。它经过 cc 的流水线之后转换为一个或多个viz::TileDrawQuad存储在viz::CompositorFrame中。 cc::TextureLayer对应 viz 中的viz::TextureDrawQuad,所有想要使用自己的逻辑进行 Raster 的 UI 组件都可以使用这种 Layer,比如 Flash 插件,WebGL等。cc::SurfaceLayer对应 viz 中的viz::SurfaceDrawQuad,用于嵌入其他的 CompositorFrame。Blink 中的 iframe 和视频播放器可以使用这种 Layer 实现。cc::SolidColorLayer用于显示纯色的 UI 组件。cc::VideoLayer以前用于专门显示视频,被 SurfaceLayer 取代。cc::UIResourceLayer/cc::NinePatchLayer类似 TextureLayer,用于软件渲染。
Blink 通过以上各种 cc::Layer 来描述 UI 并实现和 cc 的对接。由于 cc::Layer 本身可以保存 Child cc::Layer,因此给定一个 Layer 对象,它实际上表示一棵 cc::Layer 树,这个 Layer 树即主线程 Layer 树,因为它运行在主线程中,并且主线程有且只有一棵 cc::Layer 树。
Commit
Commit 阶段的核心作用是将保存在 cc::Layer 中的数据提交到 cc::LayerImpl 中。cc::LayerImpl 和 cc::Layer 一一对应,只不过运行在 Compositor 线程中(也称为 Impl 线程)。在 Commit 完成之后会根据需要创建 Tiles 任务,这些任务被 Post 到 Raster 线程中执行。
Tiling+Raster
在 Commit 阶段创建的 Tiles 任务(cc::RasterTaskImpl)在该阶段被执行。Tiling 阶段最重要的作用是将一个 cc::PictureLayerImpl 根据不同的 scale 级别,不同的大小拆分为多个 cc::TileTask 任务。Raster 阶段会执行每一个 TileTask,将 DisplayItemList 中的绘制操作 Playback 到 viz 的资源中。 由于 Raster 比较耗时,属于渲染的性能敏感路径,因此Chromium在这里实现了多种策略以适应不同的情况。这些策略主要在两方面进行优化,一方面是 Raster 结果(也就是资源)存储的位置,一方面是 Raster 中 Playback 的方式。这些方案被封装在了 cc::RasterBufferProvider 的子类中,下面一一进行介绍:
cc::GpuRasterBufferProvider使用 GPU 进行 Raster,Raster 的结果直接存储在 SharedImage 中。(前文以及提到过的硬件加速)cc::OneCopyRasterBufferProvider使用 Skia 进行 Raster,结果先保存到 GpuMemoryBuffer 中,然后再将 GpuMemoryBuffer 中的数据通过 CopySubTexture 拷贝到资源的 SharedImage 中。GpuMemeoryBuffer 在不同平台有不同的实现,也并不是所有的平台都支持,在 Linux 平台上底层实现为 Native Pixmap(来自X11中的概念),在 Windows 平台上底层实现为 DXGI,在 Android 上底层实现为 AndroidHardwareBuffer,在 Mac 上底层实现为 IOSurface。cc::ZeroCopyRasterBufferProvider使用 Skia 进行 Raster,结果保存到 GpuMemoryBuffer 中,然后使用 GpuMemoryBuffer 直接创建 SharedImage。cc::BitmapRasterBufferProvider使用 Skia 进行 Raster,结果保存到共享内存中。
Raster最终会产生一个资源,这个资源被记录在了cc:PictureLayerImpl 中,他们会在Draw阶段被放在CF中。
Activate
在 Impl 端有三个 cc::LayerImpl 树,分别是 Pending,Active,Recycle 树。Commit 阶段提交的目标其实就是 Pending 树,Raster 的结果也被存储在了 Pending 树中。
在 Activate 阶段,Pending 树中的所有 cc::LayerImpl 会被复制到 Active 树中,为了避免频繁的创建 cc::LayerImpl 对象,此时 Pending 树并不会被销毁,而是退化为 Recycle 树。
和主线程 cc::Layer 树不同,cc::LayerImpl 树并不是自己维护树形结构的,而是由 cc::LayerTreeImpl 对象来维护 cc::LayerImpl 树的。三个 Impl 树分别对应三个 cc::LayerTreeImpl 对象。
Draw
Draw 阶段并不执行真正的绘制,而是遍历 Active 树中的 cc::LayerImpl 对象,并调用它的 cc::LayerImpl::AppendQuads 方法创建合适的 viz::DrawQuad 放入 CompositorFrame 的 RenderPass 中。cc::LayerImpl 中的资源会被创建为 viz::TransferabelResource 存入 CompositorFrame 的资源列表中。至此一个 viz::CompositorFrame 对象创建完毕,最后通过 cc::LayerTreeFrameSink 接口将该 CompositorFrame 发送到给 viz 进程(GPU进程)进行渲染。
总结
现在整个渲染流程就基本结束了,前端的代码已经变成了屏幕上的像素点了。
常见问题FAQ
- 免费下载或者VIP会员专享资源能否直接商用?
- 本站所有资源版权均属于原作者所有,这里所提供资源均只能用于参考学习用,请勿直接商用。若由于商用引起版权纠纷,一切责任均由使用者承担。更多说明请参考 VIP介绍。
- 提示下载完但解压或打开不了?
- 找不到素材资源介绍文章里的示例图片?
- 模板不会安装或需要功能定制以及二次开发?



![[浏览器工作原理与实践] Day 03 | HTTP 请求流程](/ripro/timthumb.php?src=https://img.qiyuandi.com/img/20210621/[llrgm5qpnlh1y0a.jpg&h=200&w=300&zc=1&a=c&q=100&s=1)

发表评论
还没有评论,快来抢沙发吧!