前文链接
【文件上传那些事儿】- 01 简单的拖拽上传和进度条
【文件上传那些事儿】- 02 二进制级别的格式验证
V1.4:大文件切片上传 - 文件 hash 计算
做这一步之前,首先要知道,为什么要计算文件的 hash。
在第一章最基础的文件上传版本中,后端存储文件的方式是使用前端这边传过去的文件名,而我们知道,不同的两个文件,完全可以有相同的文件名,在这样的情况下,无论存储哪一个,都会覆盖掉另一个,而 hash 可以理解为文件的指纹,内容不同的文件 hash 一定是不一样的,如果以 hash 为文件明在后端进行存储,就不会出现同名文件相互覆盖的问题了,这是使用 hash 的一个原因。
在此之上还能拓展出一些别的功能,比如文件秒传:在上传文件之前,先将 hash 传到后端进行查询,如果已经有了这个 hash,说明文件已经在后端存在了,那么就不用重新上传,这个时候前端提示用户文件秒传成功即可。
有了前置知识的铺垫,就可以开始计算文件的 hash 了。
对于不算太大的文件,我们直接计算其 hash 也不会有太大的问题,但如果文件开始变得大起来,直接一股脑的进行计算,很容易让浏览器变得卡顿甚至直接卡死,所以通常我们需要先将文件进行切片,随后对切片进行增量的 hash 计算。
文件切片
这个功能没有太多的难度,使用 slice 即可完成:
export const CHUNK_SIZE = 1 * 1024 * 1024;
export const createFileChunks = (file) => {
const chunks = [];
const size = CHUNK_SIZE;
let cur = 0;
while (cur < file.size) {
chunks.push({
index: cur,
fileChunk: file.slice(cur, cur + size)
});
cur += size;
}
return chunks;
};
切片之后,就可以对文件进行增量的计算 hash 了,这里推荐一个很好用的库:spark-md5。
但文件内容过大的时候,切片会非常的多,这样一下子跑太多的任务,同样会造成浏览器的卡顿,而对于这个问题,我们通常有两种解决方案:
workjswindow.requestIdleCallback()
前者可以当作是将 js 变成多线程执行,主线程进行渲染等工作,将 hash 计算的工作放在其他线程去,从而不影响主线程的工作,而后者则是时间切片,灵感来自于 react fiber,其具体原理就是让浏览器在空闲的时候去做一些事情。
接下来就分别用这两种方式进行 hash 的计算。
workjs
workjs 是无法访问 node_modules 的,所以我们首先将 spark-md5.min.js 复制到 public 目录下,随后同样在 public 下创建 hash.js 用于之后的计算工作:
之后我们就可以通过 new Worker("/hash.js") 来创建 worker,并且通过 postMessage 和 onmessage 与之交互了:
const calculateByWorker = async (chunks) => {
return new Promise(resolve => {
const worker = new Worker("/hash.js");
worker.postMessage({
chunks
});
worker.onmessage = (e: any) => {
const data = e.data;
};
});
};
在 hash.js 中,也是用同样的方式进行通信。
这里的关键点是:
- 对于每一个 chunk,我们要用一个 FileReader 进行读取
- 将读取后的内容用 spark.append() 进行增量计算
- 计算完成之后,用 spark.end() 结束
- 当然,也不要忘了用 postMessage 将 hash 传回
综上,代码如下:
self.importScripts("spark-md5.min.js");
self.onmessage = e => {
const { chunks } = e.data;
const spark = new self.SparkMD5.ArrayBuffer();
let count = 0;
const loadNext = index => {
const reader = new FileReader();
reader.readAsArrayBuffer(chunks[index].fileChunk);
reader.onload = e => {
count++;
spark.append(e.target.result);
if (count === chunks.length) {
self.postMessage({
hash: spark.end()
});
} else {
loadNext(count);
}
};
};
loadNext(0);
};
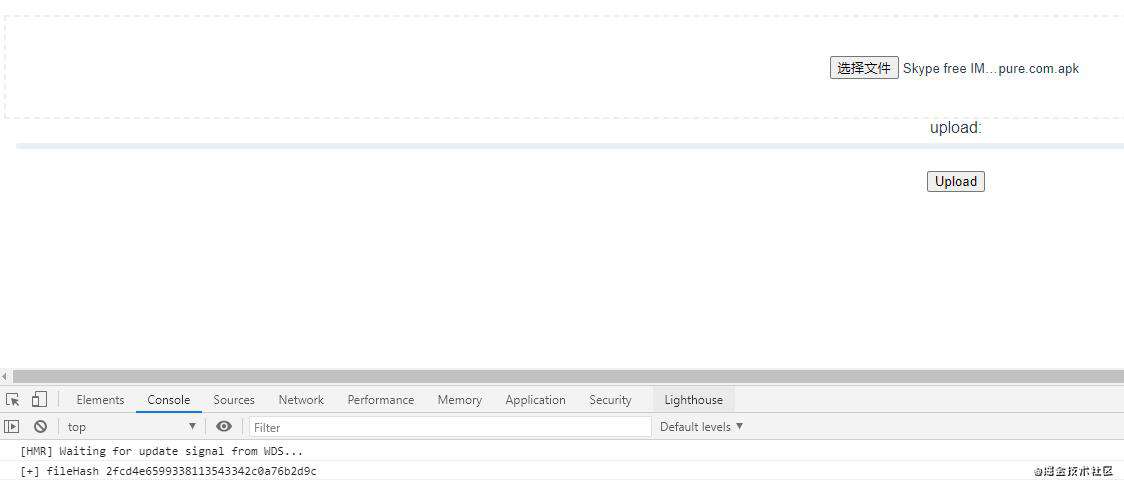
这样就可以成功计算文件的 hash 了,结果如下:
这里还可以进行一些小小的优化,比如给出计算 hash 的进度条。
那么 progress 是怎么来的呢?
我们可以在每一个切片的 hash 计算完成之后计算当前的进度,并且返回给主线程,当计算完之后将 progress 设置为 100 即可:
self.importScripts("spark-md5.min.js");
self.onmessage = e => {
const { chunks } = e.data;
const spark = new self.SparkMD5.ArrayBuffer();
+ let progress = 0;
let count = 0;
const loadNext = index => {
const reader = new FileReader();
reader.readAsArrayBuffer(chunks[index].fileChunk);
reader.onload = e => {
count++;
spark.append(e.target.result);
if (count === chunks.length) {
self.postMessage({
+ progress: 100,
hash: spark.end()
});
} else {
+ progress += 100 / chunks.length;
+ self.postMessage({
+ progress
+ });
loadNext(count);
}
};
};
loadNext(0);
};
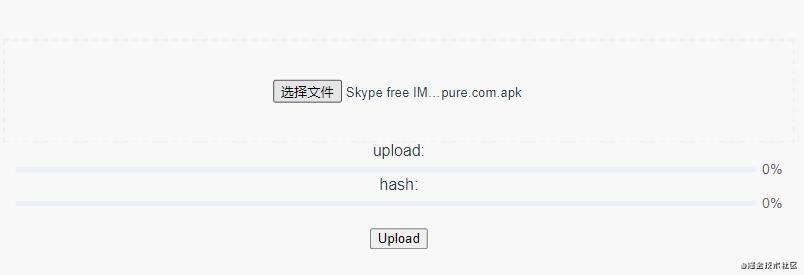
结果如下:
requestIdleCallback
前面已经提过,requestIdleCallback 的原理是让浏览器在空闲的时候执行任务,那么这里的关键点如下:
- 首先启动 requestIdleCallback
- 空闲,并且还有任务的时候,执行任务
- 自启动下一个 requestIdleCallback
那么宏观架构如下:
const calculateByIdle = (chunks) => {
let count = 0
const workLoop = async (deadline: any) => {
while (count < chunks.length && deadline.timeRemaining() > 1) {
/* do something */
count++
}
window.requestIdleCallback(workLoop);
};
window.requestIdleCallback(workLoop);
};
显然,在 while 中,我们会有一个判断:
- 如果计算完成了,则返回 hash
- 如果没有完成,则继续进行计算
这里实现一个工具方法来计算 hash:
const appendToSpark = (chunk) => {
return new Promise(resolve => {
const reader = new FileReader();
reader.readAsArrayBuffer(chunk);
reader.onload = (e) => {
spark.append(e.target.result);
resolve();
};
});
};
那么在 while 中应该是这个样子:
while (count < chunks.length && deadline.timeRemaining() > 1) {
await appendToSpark(chunks[count].fileChunk);
count++;
if (count < chunks.length) {
progressRef.value = Number(((100 * count) / chunks.length).toFixed(2));
} else {
progressRef.value = 100;
return spark.end()
}
}
由于这个过程是异步的,所以将整个 calculateByIdle 也封装起来:
const calculateByIdle = async (chunks) => {
+ return new Promise(resolve => {
const spark = new SparkMD5.ArrayBuffer();
let count = 0;
const workLoop = async (deadline) => {
while (count < chunks.length && deadline.timeRemaining() > 1) {
await appendToSpark(chunks[count].fileChunk);
count++;
if (count >= chunks.length) {
+ resolve(spark.end());
}
}
window.requestIdleCallback(workLoop);
};
window.requestIdleCallback(workLoop);
});
};
同样的,我们也可以为它加上进度:
const calculateByIdle = async (chunks, progressRef) => {
return new Promise(resolve => {
const spark = new SparkMD5.ArrayBuffer();
let count = 0;
const workLoop = async (deadline: any) => {
while (count < chunks.length && deadline.timeRemaining() > 1) {
await appendToSpark(chunks[count].fileChunk);
count++;
if (count < chunks.length) {
+ progressRef.value = Number(((100 * count) / chunks.length).toFixed(2));
} else {
+ progressRef.value = 100;
resolve(spark.end());
}
}
window.requestIdleCallback(workLoop);
};
window.requestIdleCallback(workLoop);
});
};
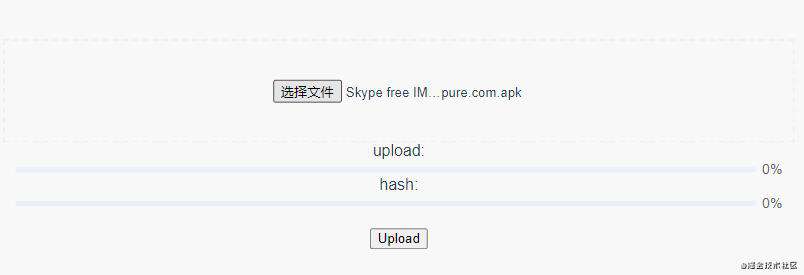
结果如下:
结束语
到这里,关于大文件上传的先期准备已经充足,接下来将介绍如何将文件切片上传到后端。
那么今天就到此为止,期待下一次的相遇~
常见问题FAQ
- 免费下载或者VIP会员专享资源能否直接商用?
- 本站所有资源版权均属于原作者所有,这里所提供资源均只能用于参考学习用,请勿直接商用。若由于商用引起版权纠纷,一切责任均由使用者承担。更多说明请参考 VIP介绍。
- 提示下载完但解压或打开不了?
- 找不到素材资源介绍文章里的示例图片?
- 模板不会安装或需要功能定制以及二次开发?





发表评论
还没有评论,快来抢沙发吧!