之前写了一篇文章 我写了个能一键下载掘金文章的浏览器插件,后来我又将目光转向了 CSDN,由于历史原因,我早期一些文章是在 CSDN 写的,虽然以前的文章更不咋滴,但毕竟都是我自己写的,也算是一个印记,所以也想下载下来
我之前其实写过一篇从 CSDN 扒文章的文章,但是那一篇文章中的操作方法体验不是太好,做成一个浏览器插件会更易用,只不过当时由于一些原因没考虑这一块
使用浏览器插件从任何博客网站上扒文章的最简单方法,就是直接通过插件获取当前页面的DOM元素,转成 markdown 或者原样保存到本地,只需要两步即可
再复杂点,想将文章中引用到的图片也保存下来,就需要专门做额外的图片处理
最后,如果想将自己的文章原模原样一字不差地下载下来,逻辑就更多了(直接将页面DOM的文本信息下载下来或者转成 markdown下载下来,肯定会有精度缺失的)
既然着手做这个东西了,那么肯定是按照最高标准来做,也就是能下载图片就下载图片,能获取到原文本就获取原文本
直观点就是这张图:
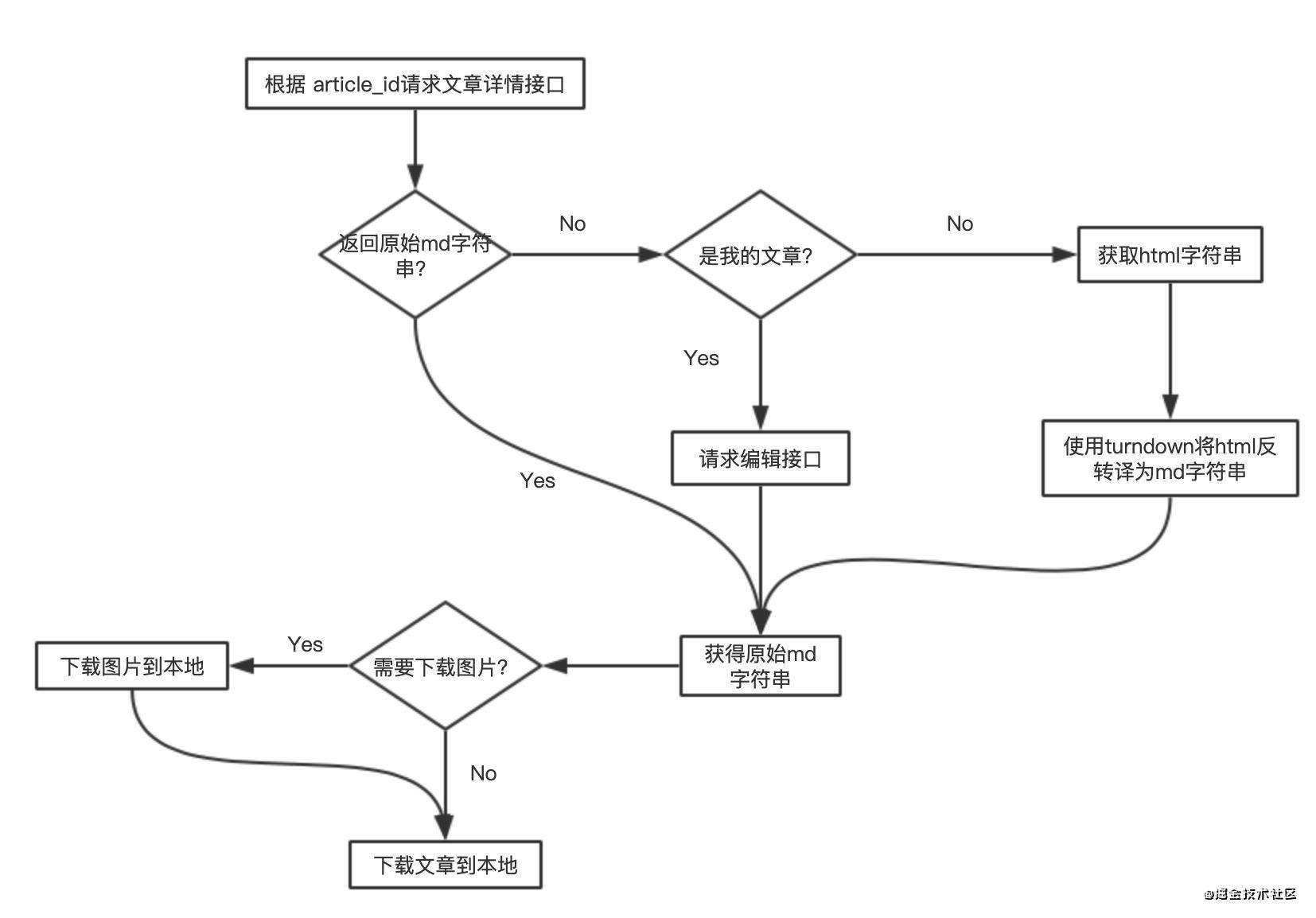
这个时候我就想到,既然所有博客网站扒文章的流程都是差不多的,那么索性就多处理几个网站的吧,最终的插件支持 掘金、CSDN、开源中国、博客园 这四个博客网站的文章下载功能
插件的源码已经放到 github 了,有兴趣的可以试用一下,不清楚如何安装这种本地插件的,可以看下我发的这个 沸点
CSDN
大体流程跟 我写了个能一键下载掘金文章的浏览器插件 差不多,先写下载当前文章的逻辑
如果当前文章是属于我的,并且我也已经登录了,那么为了获取到最精确的原始文本信息,则需要请求编辑文章接口,这个接口会将你原先保存的文章原文本返回
于是我去看了下 csdn的接口,接口是很好找的,就是 https://bizapi.csdn.net/blog-console-api/v3/editor/getArticle?id=xxx&model_type=,接着我就把这个链接复制下来继续写逻辑了,但是写完之后进行测试的时候,忽然发现接口 403 了
以为是 cookie没带上,看了下请求体里的 cookie明明都在,更让人迷惑的是,我在浏览器里直接请求这个链接,居然也是不通的,于是我在开发者工具里直接将 csdn发起的正常请求 Copy as fetch,也就是复制了一个一模一样的请求,包括 header、referrer等啥都一样的,然后在浏览器里执行这个请求,结果依旧是 403
这时我就意识到,这应该就不是我的问题了,联想到之前遇到过 csdn给图片加防盗链的事情,我就想到应该是 csdn对接口进行了一定的加密了
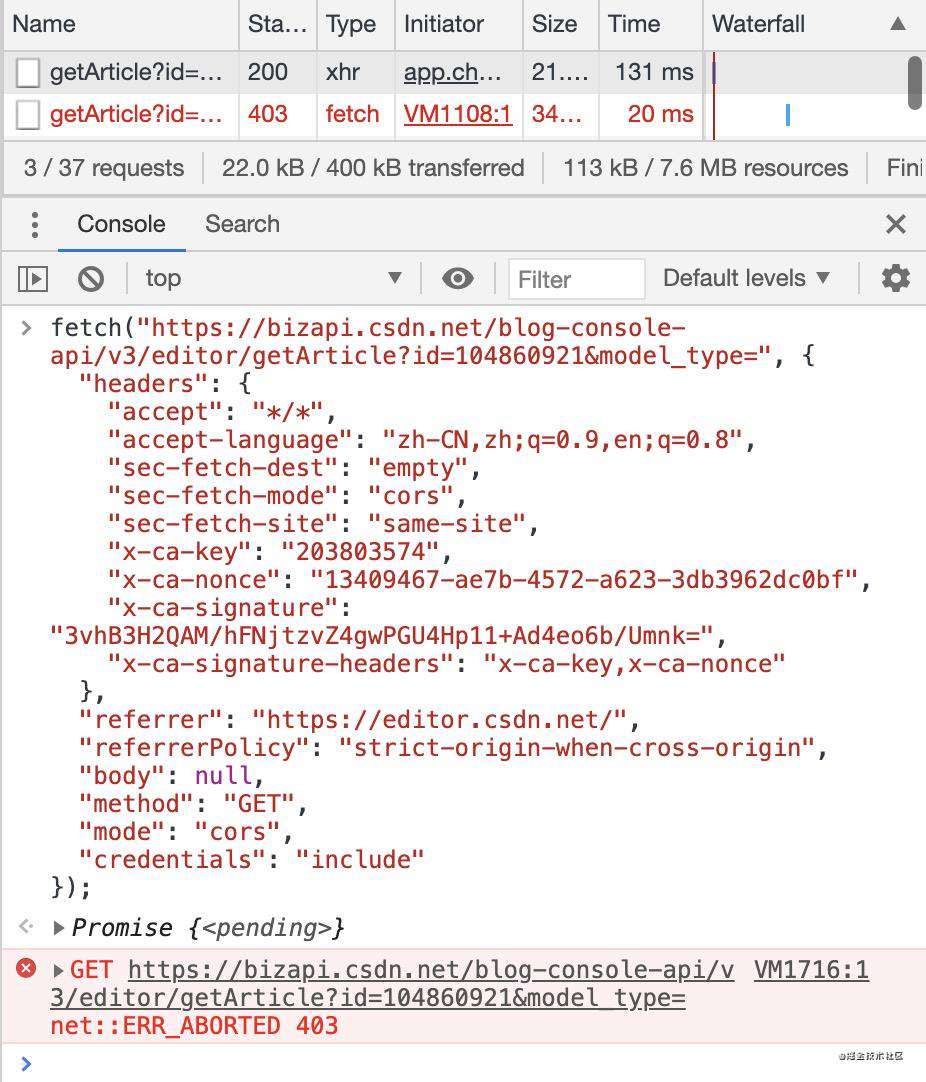
我仔细看了下我 copy下来的请求内容,发现在 headers 中有四个属性比较奇怪:x-ca-key、x-ca-nonce、x-ca-signature、x-ca-signature-headers
这四个 headers 属性并不是标准属性,而是认为加上去的,而且属性的名字也很有指向性,看着就像是用来加密的
重复刷新编辑页面,发现对于完全相同的一个请求,每次请求的header头中,这四个属性中的 x-ca-key 和 x-ca-signature-headers都是固定的,x-ca-nonce 和 x-ca-signature 则会发生变化,于是想到这两个值可能是其他接口返回的,但是把页面相关的所有接口都看了一遍,发现并没有相关信息,既然不是后端返回的,那么就只能是前端生成的
全局搜索 x-ca-,一下就搜到了,而且四个属性的赋值逻辑全写到了一起去了
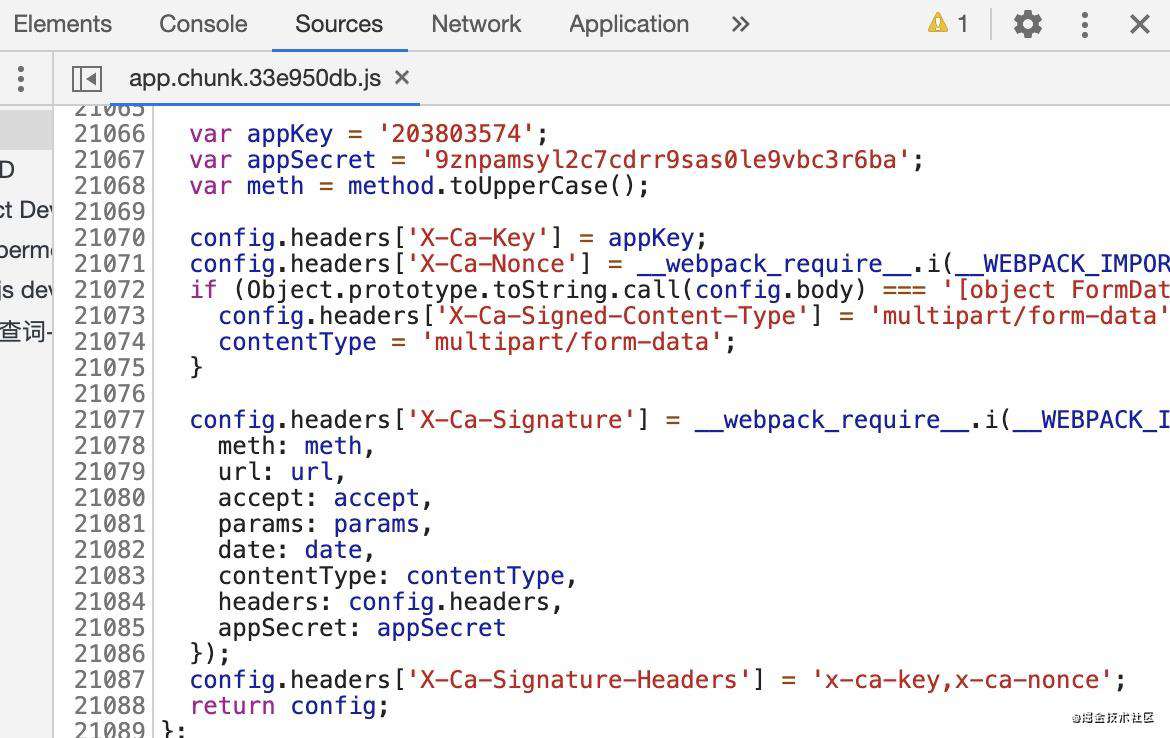
和猜想的一样,x-ca-key、x-ca-signature-headers都是固定写死的,x-ca-nonce 和 x-ca-signature就另有计算逻辑了
先看下 x-ca-nonce 的计算,是由一个 xCaNonce() 的方法得到的,看下这个方法

这个方法又调用了 createUuid,这个方法看名字大概就可以猜到是干什么的了

看了下这个方法果然很熟悉,就是一种生成 uuid的方法,所以每次请求发出的时候,这个值都不一样就解释得通了,直接把这个方法抄下来,就用它生成 x-ca-nonce

接下来再看 x-ca-signature,这个计算逻辑稍微复杂一点,首先调用了一个 xCaSignature() 方法

这个方法比较复杂,中间一大堆逻辑就是用来计算一些中间值的,直接倒着看,从最后的结果往上倒推

看这段:
var xCaSignature = function xCaSignature(_ref) {
// ...
var hash = __WEBPACK_IMPORTED_MODULE_3_crypto_js___default.a.HmacSHA256(textToSign, appSecret);
var signature = hash.toString(__WEBPACK_IMPORTED_MODULE_3_crypto_js___default.a.enc.Base64);
return signature;
};
__WEBPACK_IMPORTED_MODULE_3_crypto_js___default这个对象中的 crypto_js 字符,以及后面的 HmacSHA256 方法,综合起来看着就该是 crypto-js,所以猜测一下这应该就是关键加密逻辑了
appSecret 是一个固定字符串 9znpamsyl2c7cdrr9sas0le9vbc3r6ba,textToSign是啥呢?

看起来很像是请求header中的一些数据拼接而成的字符串,试了几次后确定下来,这个字符串的第一、二行是固定的,再往下 x-ca-key:203803574 这行也是固定字符,再下一行其实就是上面计算出来的 x-ca-nonce及其值的 k-v字符串,这个时候再回头看 xCaSignature() 方法就很清晰了,好家伙,代码写了一大堆,就是为了拼接这个字符串
计算出了 hash 后,又进行了一次 base64 的加密,接着就把结果返回作为 x-ca-signature的值了
大概弄清楚了逻辑之后,我就去把 crypto-js 下载了下来,然后按照上述逻辑验证了一遍,流程跑通,至此,四个加密 header属性都已经得到
csdn的这个加密确实增加了爬取文章的难度,但加密逻辑应该只是出自一般搬砖的业务程序员之手,关键代码的混淆压缩都没做,稍微分析下就能很快理清思路,当然了,他们的目的可能也只是这个罢了,只要能增加一点门槛过滤掉一部分人即可,毕竟前端加密本来就不靠谱,也没必要费尽心思去做这种 roi不高的事情
不过有一点我还是没搞明白,有权限编辑文章的人肯定是文章所有者,给编辑接口加密的目的是什么?防止我爬取我自己的文章?
接下来的流程基本就和 我写了个能一键下载掘金文章的浏览器插件 中的一样了,不多赘述
开源中国(osChina)
开源中国倒是没有对接口加密的操作,但有一点比较麻烦的是,它的文章链接存在很多种格式,甚至对于同一篇文章,从不同的入口进去,链接居然都可以是不同的
穷举这些入口格式就没必要了,只需要能保证支持大多数文章即可,也就是文章详情页链接是这两种格式的:https://my.oschina.net/xxx/blog/yyy、https://my.oschina.net/u/xxx/blog/yyy,相对应的,文章所属作者主页和文章列表页等页面,也都是各自对应着两种路由格式,这种对应关系是有规可循的,所以只要在一开始确定好用哪种格式之后,后面的跟着用就行了
博客园(cnblogs)
博客园的技术栈应该比较古老,页面基本都是服务器渲染返回的,ajax接口很少,甚至编辑页面的数据都是服务器返回然后前端进行数据切分及格式化的,所以这块逻辑还需要单独处理下
并且编辑页面的域名和文章详情页也不一样,插件在文章详情页发起对编辑页面的请求居然还跨域了,于是只好再给插件加一个可以无限跨域的 background script,然后又想到在获取一些图片的 cotent-type的时候也会出现跨域问题,于是一并也都使用 background script 解决掉
另外,博客园的大版本改动应该比开源中国还要多,文章详情页的链接格式不止一种(到底多少种我也不知道),更有甚者,博客园的页面好像是可以自定义页面布局之类的东西的,总之,想使用统一的逻辑处理所有的页面比较困难,case很多,我只能将我所碰到的一一解决掉,至于我没遇到过的场景,插件肯定就无法处理了,大家如果使用的时候遇到问题,可以提 issue,最好带上出问题的文章链接,方便定位进行处理
小结
插件的技术难度没有多少,但处理的case比较多,虽然我尽可能地进行了测试,但肯定还是可能存在没有验证到的场景,所以可能还是存在一些问题的,诸位在使用的过程中如果遇到了问题,欢迎提 issue 或者 PR
插件目前支持掘金、CSDN、开源中国、博客园这四个网站的文章下载功能,实际上无论是下载哪个网站上的技术文章,大体处理流程都是一样的,即开篇的那张图
所以除了这四个网站之外,其他的网站理论上也可以利用当前已有的处理框架/流程快速进行功能开发,另外,还可以加一些额外的功能,例如将其他网站的文章一键发布到掘金 欢迎有兴趣的同学一起持续共建本插件
常见问题FAQ
- 免费下载或者VIP会员专享资源能否直接商用?
- 本站所有资源版权均属于原作者所有,这里所提供资源均只能用于参考学习用,请勿直接商用。若由于商用引起版权纠纷,一切责任均由使用者承担。更多说明请参考 VIP介绍。
- 提示下载完但解压或打开不了?
- 找不到素材资源介绍文章里的示例图片?
- 模板不会安装或需要功能定制以及二次开发?



发表评论
还没有评论,快来抢沙发吧!