前言
最近开始深入学习React的原理了,后面会出一系列关于React原理的文章,基本都是我学习其他前辈的React源码分析以及跟随他们阅读源码时的一些思考和记录,内容大部分非原创,但我会用我自己的方式去总结原理以及相关的流程,并加以补充,当作自己的学习总结。
本系列内容偏向底层源码实现,如果你是React新手,不建议你细看。
本文的内容是关于React首次渲染的流程。
首次渲染中,React代码变成DOM的流程

这里主要有两个步骤,第一个是从JSX代码经过React.createElement方法变成一个虚拟DOM,第二个步骤是通过ReactDOM.render方法把虚拟DOM变成真实DOM。
React.createElement
对于 React.createElement方法,很多新人可能并不知道,因为我们在一般的业务逻辑中,比较少会直接使用这个方法。其实在React官网中,就已经有写明了。
我们在babel官网里可以写个JSX试一下。
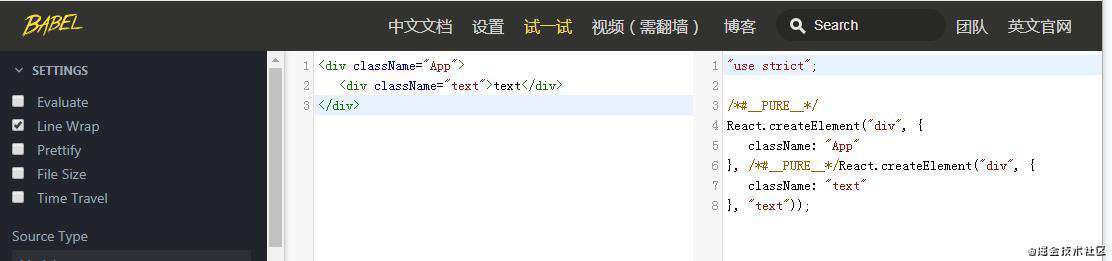
JSX在经过babel的编译之后,变成了嵌套的React.createElement。JSX 的本质其实就是React.createElement这个 JavaScript 调用的语法糖。 有了JSX 语法糖的存在,我们可以使用我们最为熟悉的类 HTML 标签语法来创建虚拟 DOM,在降低学习成本的同时,也提升了研发效率与研发体验。
接下来,我们来看下createElement的源码
export function createElement(type, config, children) {
// propName 变量用于储存后面需要用到的元素属性
let propName;
// props 变量用于储存元素属性的键值对集合
const props = {};
// key、ref、self、source 均为 React 元素的属性
let key = null;
let ref = null;
let self = null;
let source = null;
// config 对象中存储的是元素的属性
if (config != null) {
// 进来之后做的第一件事,是依次对 ref、key、self 和 source 属性赋值
if (hasValidRef(config)) {
ref = config.ref;
}
// 此处将 key 值字符串化
if (hasValidKey(config)) {
key = '' + config.key;
}
self = config.__self === undefined ? null : config.__self;
source = config.__source === undefined ? null : config.__source;
// 接着就是要把 config 里面的属性都一个一个挪到 props 这个之前声明好的对象里面
for (propName in config) {
if (
// 筛选出可以提进 props 对象里的属性
hasOwnProperty.call(config, propName) && !RESERVED_PROPS.hasOwnProperty(propName)
) {
props[propName] = config[propName];
}
}
}
// childrenLength 指的是当前元素的子元素的个数,减去的 2 是 type 和 config 两个参数占用的长度
const childrenLength = arguments.length - 2;
// 如果抛去type和config,就只剩下一个参数,一般意味着文本节点出现了
if (childrenLength === 1) {
// 直接把这个参数的值赋给props.children
props.children = children;
// 处理嵌套多个子元素的情况
} else if (childrenLength > 1) {
// 声明一个子元素数组
const childArray = Array(childrenLength);
// 把子元素推进数组里
for (let i = 0; i < childrenLength; i++) {
childArray[i] = arguments[i + 2];
}
// 最后把这个数组赋值给props.children
props.children = childArray;
}
// 处理 defaultProps
if (type && type.defaultProps) {
const defaultProps = type.defaultProps;
for (propName in defaultProps) {
if (props[propName] === undefined) {
props[propName] = defaultProps[propName];
}
}
}
// 最后返回一个调用ReactElement执行方法,并传入刚才处理过的参数
return ReactElement(
type,
key,
ref,
self,
source,
ReactCurrentOwner.current,
props,
);
}
总结一下这个函数做的一些事情
- 1.二次处理
key,ref,self,source四个值(将key字符串化,将config中的ref赋值给ref,self和source暂不太清楚其功能,可以忽略,17版本的jsx方法直接删除了这两个参数) - 2.遍历
config,筛选出可以赋值到props里的属性 - 3.提取子元素,赋值到
props.children中(如果只有一个子元素,就直接赋值,如果子元素大于一个,就以数组形式存储) - 4.格式化
defaultProps(如果没有传入相关的props,props就取设置的默认值) - 5.返回一个
ReactElement方法,并传入刚才处理的参数
createElement其实就是一个数据处理器,把从JSX获取到的内容进行格式化,再传入ReactElement方法中。
注意:在React 17版本当中,createElement会被替换成jsx(源码地址)方法。
import React from 'react'; // 在17版本中,可以不引入这句
function App() {
return <h1>Hello World</h1>;
}
// createElement
function App() {
return React.createElement('h1', null, 'Hello world');
}
// 17版本中的jsx
import {jsx as _jsx} from 'react/jsx-runtime'; // 由编译器引入
function App() {
// 子元素将直接编译成config对象里的children属性,jsx不再接收单独的子元素入参
return _jsx('h1', { children: 'Hello world' });
}
ReactElement
我们来看看ReactElement方法做了哪些事,源码地址。
const ReactElement = function(type, key, ref, self, source, owner, props) {
const element = {
// REACT_ELEMENT_TYPE是一个常量,用来标识该对象是一个ReactElement
$$typeof: REACT_ELEMENT_TYPE,
// 内置属性赋值
type: type,
key: key,
ref: ref,
props: props,
// 记录创造该元素的组件
_owner: owner,
};
//
if (__DEV__) {
// 省略这些不必要的代码
}
return element;
};
ReactElement方法也很简单,其实就是通过这些传入的参数,创建了一个对象,并把它返回出来。这个ReactElement对象实例就是createElement方法最终返回出的内容,它就是React虚拟DOM的一个节点。虚拟DOM其实本质上就是一个存储了很多用来描述DOM的属性的对象。
这里你要注意,因为每个节点都会被createElement方法调用,所以最终返回回来的应该是一个虚拟DOM的树。
const App = (
<div className="App">
<h2 className="title">title</h2>
<p className="text">text</p>
</div>
);
console.log(App);

如上图所示,所有的节点都会被编译成ReactElement对象实例(虚拟DOM)。
ReactDOM.render
虚拟DOM有了,但我们最终的目的还是要把内容渲染到页面上,所以我们还需要通过ReactDOM.render方法把虚拟DOM渲染成真实的DOM。这一块内容比较多,我会一个函数一个函数的分开讨论。
关于为什么要使用虚拟DOM,虚拟DOM有哪些优势,这些内容不在本文的讨论范围内容,网上相关的文章很多,大家可以自行去了解一下。
三种React启动方式
在React的16版本以及17版本中,一直都有三种启动方式
legacy模式,ReactDOM.render(<App />, rootNode)。目前常用的模式,渲染过程是同步的blocking模式,ReactDOM.createBlockingRoot(rootNode).render(<App />)。过渡的模式,基本很少用concurrent模式,ReactDOM.createRoot(rootNode).render(<App />)。异步渲染的模式,还可以使用一些新的特性,目前还在实验中。
官方文档
我们是解析ReactDOM.render的渲染流程,所以其实分析的是一个同步的流程。关于concurrent的异步渲染流程,时间分片以及优先级,其实也是在同步渲染的基础上做的一些修改,这些内容我会在本系列后续的文章中再总结。
虽然说是一个同步的流程,但是在React 16版本的时候,已经把整个的渲染链路重构成了Fiber的结构。Fiber架构在 React中并不能够和异步渲染画严格的等号,它是一种同时兼容了同步渲染与异步渲染的设计。
首次render的三个阶段
ReactDOM.render 方法对应的调用栈很深,涉及到的函数方法也很多,不过我们可以只需要看一些关键的逻辑,了解大致的流程即可。
首次render可以大体上分成三个阶段
- 初始化阶段,完成
Fiber树中基本实体的创建。从调用ReactDOM.render开始,到scheduleUpdateOnFiber方法调用performSyncWorkOnRoot结束。 - render阶段,构建和完善
Fiber树。从performSyncWorkOnRoot方法开始,到commitRoot方法结束。 - commit阶段, 遍历
Fiber树,把Fiber节点映射为DOM节点并渲染到页面上。从commitRoot方法开始,到渲染结束。
上面几个方法现在看不懂没关系,接下来会一步步带你了解。只需要有个大致的印象,知道这三个阶段分别完成的事情。
初始化阶段
现在我们开始初始化阶段,在这个阶段,上文中已经说,主要就是完成Fiber树中基本实体的创建。但是我们需要知道什么是基本实体?有哪些?我们从源码中去寻找答案。
legacyRenderSubtreeIntoContainer
我们只看关键的逻辑,我们先来看看ReactDOM.render中调用的legacyRenderSubtreeIntoContainer方法(源码地址)。
// ReactDOM.render中的调用
return legacyRenderSubtreeIntoContainer(null, element, container, false, callback);
// legacyRenderSubtreeIntoContainer源码
function legacyRenderSubtreeIntoContainer(parentComponent, children, container, forceHydrate, callback) {
// container 对应的是我们传入的真实 DOM 对象
var root = container._reactRootContainer;
// 初始化 fiberRoot 对象
var fiberRoot;
// DOM 对象本身不存在 _reactRootContainer 属性,因此 root 为空
if (!root) {
// 若 root 为空,则初始化 _reactRootContainer,并将其值赋值给 root
root = container._reactRootContainer = legacyCreateRootFromDOMContainer(container, forceHydrate);
// legacyCreateRootFromDOMContainer 创建出的对象会有一个 _internalRoot 属性,将其赋值给 fiberRoot
fiberRoot = root._internalRoot;
// 这里处理的是 ReactDOM.render 入参中的回调函数,你了解即可
if (typeof callback === 'function') {
var originalCallback = callback;
callback = function () {
var instance = getPublicRootInstance(fiberRoot);
originalCallback.call(instance);
};
} // Initial mount should not be batched.
// 进入 unbatchedUpdates 方法
unbatchedUpdates(function () {
updateContainer(children, fiberRoot, parentComponent, callback);
});
} else {
// else 逻辑处理的是非首次渲染的情况(即更新),其逻辑除了跳过了初始化工作,与楼上基本一致
fiberRoot = root._internalRoot;
if (typeof callback === 'function') {
var _originalCallback = callback;
callback = function () {
var instance = getPublicRootInstance(fiberRoot);
_originalCallback.call(instance);
};
} // Update
updateContainer(children, fiberRoot, parentComponent, callback);
}
return getPublicRootInstance(fiberRoot);
}
这个函数主要做了下面几步
- 1.调用
legacyCreateRootFromDOMContainer方法创建了container._reactRootContainer并赋值给root - 2.将
root的_internalRoot属性赋值给fiberRoot - 3.将
fiberRoot与一些其他参数传入updateContainer方法 - 4.把
updateContainer的回调内容作为参数传入unbatchedUpdates方法
这里的fiberRoot的本质是一个FiberRootNode对象,它的关联对象是真实DOM的容器节点,这个对象里有一个current对象
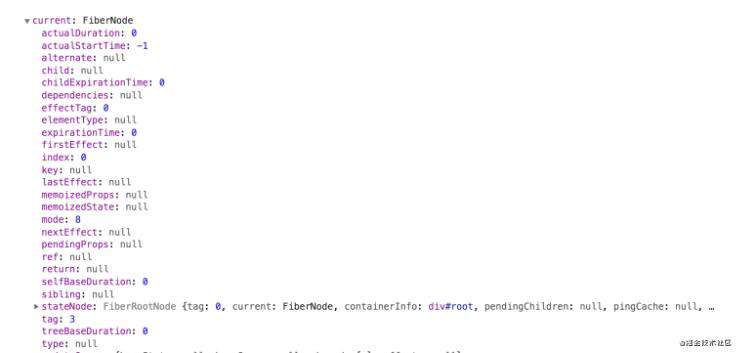 如上图,这个
如上图,这个current对象是一个FiberNode实例,其实它就是一个Fiber节点,而且她还是当前Fiber树的头部节点。fiberRoot和它下面的current对象这两个节点,将是后续整棵Fiber树构建的起点。
unbatchedUpdates
接下来我们看看unbatchedUpdates方法(源码地址)。
function unbatchedUpdates(fn, a) {
// 这里是对上下文的处理,不必纠结
var prevExecutionContext = executionContext;
executionContext &= ~BatchedContext;
executionContext |= LegacyUnbatchedContext;
try {
// 重点在这里,直接调用了传入的回调函数 fn,对应当前链路中的 updateContainer 方法
return fn(a);
} finally {
// finally 逻辑里是对回调队列的处理,此处不用太关注
executionContext = prevExecutionContext;
if (executionContext === NoContext) {
// Flush the immediate callbacks that were scheduled during this batch
resetRenderTimer();
flushSyncCallbackQueue();
}
}
}
这个方法比较简单,其实就是直接调用了传入的回调函数fn。而fn,是在legacyRenderSubtreeIntoContainer中传入的
unbatchedUpdates(function () {
updateContainer(children, fiberRoot, parentComponent, callback);
});
所以我们再来看updateContainer方法
updateContainer
先来看源码(源码地址),我会删除很多无关的逻辑。
function updateContainer(element, container, parentComponent, callback) {
// 这个 current 就是之前说的当前`Fiber`树的头部节点
const current = container.current;
// 这是一个 event 相关的入参,此处不必关注
var eventTime = requestEventTime();
// 这是一个比较关键的入参,lane 表示优先级
var lane = requestUpdateLane(current);
// 结合 lane(优先级)信息,创建 update 对象,一个 update 对象意味着一个更新
var update = createUpdate(eventTime, lane);
// update 的 payload 对应的是一个 React 元素
update.payload = {
element: element
};
// 处理 callback,这个 callback 其实就是我们调用 ReactDOM.render 时传入的 callback
callback = callback === undefined ? null : callback;
if (callback !== null) {
{
if (typeof callback !== 'function') {
error('render(...): Expected the last optional `callback` argument to be a ' + 'function. Instead received: %s.', callback);
}
}
update.callback = callback;
}
// 将 update 入队
enqueueUpdate(current, update);
// 调度 fiberRoot
scheduleUpdateOnFiber(current, lane, eventTime);
// 返回当前节点(fiberRoot)的优先级
return lane;
}
这个方法里的逻辑有点复杂,总的来说可以分为三点
- 1.请求当前
Fiber节点的lane(优先级) - 2.结合
lane(优先级),创建当前Fiber节点的update对象,并将其入队 - 3.调度当前节点(
rootFiber)进行更新
不过因为本文讲解的首次渲染链路是同步的,优先级意义不大,所以我们可以直接看看调度节点的方法scheduleUpdateOnFiber。
scheduleUpdateOnFiber
这个方法内容有点长,我只列出关键逻辑(源码地址)。
// 如果是同步的渲染,将进入这个条件。如果是异步渲染的模式,将进入它的else逻辑中
// React 是通过 fiber.mode 来区分不同的渲染模式
if (lane === SyncLane) {
if (
// 判断当前是否运行在 unbatchedUpdates 方法里
(executionContext & LegacyUnbatchedContext) !== NoContext &&
// 判断当前是否已经 render
(executionContext & (RenderContext | CommitContext)) === NoContext
) {
schedulePendingInteractions(root, lane);
// 我们要关注的关键步骤,从这个方法开始。开启 render 阶段
performSyncWorkOnRoot(root);
} else {
ensureRootIsScheduled(root, eventTime);
schedulePendingInteractions(root, lane);
if (executionContext === NoContext) {
// Flush the synchronous work now, unless we're already working or inside
// a batch. This is intentionally inside scheduleUpdateOnFiber instead of
// scheduleCallbackForFiber to preserve the ability to schedule a callback
// without immediately flushing it. We only do this for user-initiated
// updates, to preserve historical behavior of legacy mode.
resetRenderTimer();
flushSyncCallbackQueue();
}
}
}
在之前的步骤中,React已经完成Fiber树中基本实体的创建,其实就是之前几节说的fiberRoot和它下面的current对象这两个节点。在这个方法中,我们只需要关注performSyncWorkOnRoot方法,从它开始,我们将进入render阶段。
render阶段
render阶段要做的事情是构建和完善Fiber树,其实就是以fiberRoot和它下面的current对象这两个节点为顶节点,不断的遍历,把他们的子元素的Fiber树构建出来。
我们先来看performSyncWorkOnRoot方法。
performSyncWorkOnRoot
performSyncWorkOnRoot源码地址
这里重点看两个逻辑
exitStatus = renderRootSync(root, lanes);
...
commitRoot(root);
renderRootSync方法是render阶段开始的标志,而下面的commitRoot是commit阶段开始的标志。我们先进入的是render阶段,所以我们先看renderRootSync里的流程。
renderRootSync源码地址
这个方法里需要看两个逻辑
prepareFreshStack(root, lanes);
...
workLoopSync();
我们先走prepareFreshStack的流程,等它走完了,再进入workLoopSync的遍历流程。
prepareFreshStack源码地址
prepareFreshStack的作用是重置一个新的堆栈环境,我们也只需要关注一个逻辑
workInProgress = createWorkInProgress(root.current, null);
createWorkInProgress是一个比较重要的方法,我们详细看一下。
createWorkInProgress
精简后的源码如下,源码地址
// 这里入参中的 current 传入的是现有树结构中的 rootFiber 对象
function createWorkInProgress(current, pendingProps) {
var workInProgress = current.alternate;
// ReactDOM.render 触发的首屏渲染将进入这个逻辑
if (workInProgress === null) {
// 这是需要你关注的第一个点,workInProgress 是 createFiber 方法的返回值
workInProgress = createFiber(current.tag, pendingProps, current.key, current.mode);
workInProgress.elementType = current.elementType;
workInProgress.type = current.type;
workInProgress.stateNode = current.stateNode;
// 这是需要你关注的第二个点,workInProgress 的 alternate 将指向 current
workInProgress.alternate = current;
// 这是需要你关注的第三个点,current 的 alternate 将反过来指向 workInProgress
current.alternate = workInProgress;
} else {
// else 的逻辑此处先不用关注
}
// 以下省略大量 workInProgress 对象的属性处理逻辑
// 返回 workInProgress 节点
return workInProgress;
}
这里事先说明一下,入参current就是之前的fiberRoot对象下的current对象。
总结一下createWorkInProgress方法做的事情
- 1.调用
createFiber,workInProgress是createFiber方法的返回值 - 2.把
workInProgress的alternate将指向current - 3.把
current的alternate将反过来指向workInProgress - 4.最终返回一个
workInProgress节点
这里的createFiber方法,顾名思义,就是用来创建一个Fiber节点的方法。入参都是current的值,所以,workInProgress节点其实就是current节点的副本。这时候整颗树的结构应该如下所示:

workInProgress树顶点创建完成了,现在运行之前renderRootSync方法里第二个关键逻辑workLoopSync。
workLoopSync
这个方法很简单,就是个遍历的功能
function workLoopSync() {
// 若 workInProgress 不为空
while (workInProgress !== null) {
// 针对它执行 performUnitOfWork 方法
performUnitOfWork(workInProgress);
}
}
因为后面列出的方法,都是workLoopSync中不断遍历的,所以在解析performUnitOfWork方法及其子方法之前,我要先对整个遍历的流程做一个大致的总结,有了一个大致的了解之后再去分析里面的方法。
workLoopSync做的事情就是通过while循环反复判断workInProgress是否为空,并在不为空的情况下针对它执行performUnitOfWork函数。而 performUnitOfWork函数将触发beginWork的调用,创建新的Fiber节点。若beginWork所创建的Fiber节点不为空,则performUniOfWork会用这个新的Fiber节点来更新workInProgress的值,为下一次循环做准备。
当workInProgress为空时,意味着已经完成对整棵Fiber树的构建。
在这个过程中,每一个被创建出来的新Fiber节点,都会挂载为之前的workInProgress树的后代节点。我们一步步来看一下。
performUnitOfWork
源码地址
next = beginWork(current, unitOfWork, subtreeRenderLanes);
if (next === null) {
// If this doesn't spawn new work, complete the current work.
completeUnitOfWork(unitOfWork);
} else {
workInProgress = next;
}
performUnitOfWork里其实存在有两个流程,一个是beginWork流程(创建新的Fiber节点),还有一个completeWork流程(当beginWork遍历到当前分支的叶子节点时,next === null,运行completeWork流程),来负责处理Fiber节点到DOM节点的映射逻辑。
我们先来看beginWork流程
beginWork
beginWork代码有400多行,实在太多了,只取一些关键逻辑。源码地址
function beginWork(current, workInProgress, renderLanes) {
......
// current 节点不为空的情况下,会加一道辨识,看看是否有更新逻辑要处理
if (current !== null) {
// 获取新旧 props
var oldProps = current.memoizedProps;
var newProps = workInProgress.pendingProps;
// 若 props 更新或者上下文改变,则认为需要"接受更新"
if (oldProps !== newProps || hasContextChanged() || (
workInProgress.type !== current.type )) {
// 打个更新标
didReceiveUpdate = true;
} else if (xxx) {
// 不需要更新的情况 A
return A
} else {
if (需要更新的情况 B) {
didReceiveUpdate = true;
} else {
// 不需要更新的其他情况,这里我们的首次渲染就将执行到这一行的逻辑
didReceiveUpdate = false;
}
}
} else {
didReceiveUpdate = false;
}
......
// 这坨 switch 是 beginWork 中的核心逻辑,原有的代码量相当大
switch (workInProgress.tag) {
......
// 这里省略掉大量形如"case: xxx"的逻辑
// 根节点将进入这个逻辑
case HostRoot:
return updateHostRoot(current, workInProgress, renderLanes)
// dom 标签对应的节点将进入这个逻辑
case HostComponent:
return updateHostComponent(current, workInProgress, renderLanes)
// 文本节点将进入这个逻辑
case HostText:
return updateHostText(current, workInProgress)
......
// 这里省略掉大量形如"case: xxx"的逻辑
}
}
beginWork的核心逻辑是根据fiber节点(workInProgress树下的节点)的tag属性(代表当前fiber属于什么类型的标签)的不同,调用不同的节点创建函数。
这些节点创建函数,最终都会通过调用reconcileChildren方法,生成当前节点的子节点。
reconcileChildren(beginWork流程)
这个方法也比较简单
function reconcileChildren(current, workInProgress, nextChildren, renderLanes) {
// 判断 current 是否为 null
if (current === null) {
// 若 current 为 null,则进入 mountChildFibers 的逻辑
workInProgress.child = mountChildFibers(workInProgress, null, nextChildren, renderLanes);
} else {
// 若 current 不为 null,则进入 reconcileChildFibers 的逻辑
workInProgress.child = reconcileChildFibers(workInProgress, current.child, nextChildren, renderLanes);
}
}
上面的两个方法,我们也可以找到赋值的地方
var reconcileChildFibers = ChildReconciler(true);
var mountChildFibers = ChildReconciler(false);
这两个方法都是通过ChildReconciler方法创建出来的,只是入参有所区别
ChildReconciler(beginWork流程)
ChildReconciler的代码量也很大,代码就不放了,源码地址。
这个方法里包含了很多关于Fiber节点的创建、增加、删除、修改等操作的函数,用来给其他函数调用。返回值是一个名为reconcileChildFibers的函数,这个函数是一个逻辑分发器,它将根据入参的不同,执行不同的Fiber节点操作,最终返回不同的目标Fiber节点。
还有一个很重要的逻辑,这个方法会根据入参shouldTrackSideEffects来决定“是否需要追踪副作用”,reconcileChildFibers和mountChildFibers的不同,主要在于对副作用的处理不同。shouldTrackSideEffects为true的话,会给新创建的这个Fiber节点添加一个flags属性(17版本之前,这个属性名是effectTag),并赋值一个常量。
如果是根节点,会赋值一个Placement常量,这是一个二进制常量,目的是在渲染真实DOM的时候告诉渲染器,处理这个fiber节点时是需要新增DOM节点的。
这种类型的常量还有很多,源码地址。
这里先给一个demo,后续的编译都会以这个demo来实现。
function App() {
return (
<div className="App">
<div className="container">
<h1>我是标题</h1>
<p>我是第一段话</p>
<p>我是第二段话</p>
</div>
</div>
);
}
const rootElement = document.getElementById("root");
ReactDOM.render(<App />, rootElement);
回到我们刚才的渲染链路中来,因为本次循环是第一次,处理的是current树和workInProgress树的顶部节点,所以current是存在的,会进入reconcileChildFibers方法中,它是允许追踪副作用的。因为当前的workInProgress是顶部节点,它是没有一个确切的ReactElement与之映射,所以它会作为是JSX中根组件的父节点,就是这个App组件的父节点。然后会基于App组件的ReactElement(jsx编译后的虚拟DOM)对象信息,创建其对应的FiberNode,并给它打上Placement(新增)的副作用标记, 返回给workInProgress.child。
这样就将JSX根组件的Fiber与之前创建的Fiber树顶点关联起来了,如下图。

这样,第一次循环完成,因为App还有子元素,所以beginWork中返回的workInProgress不为null(workInProgress其实就是这些jsx节点编译之后的fiber节点),workLoopSync还会继续循环。最终的树结构如下

我们来看看这些标签的fiber节点对象。
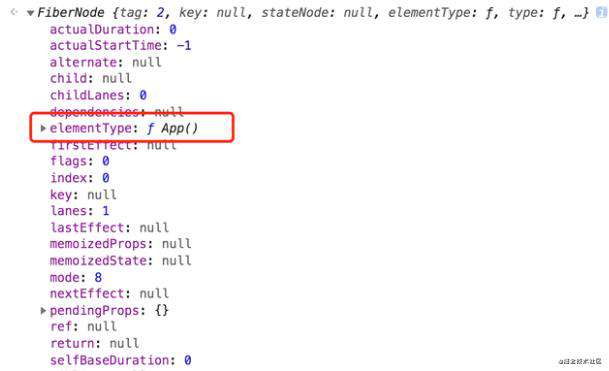
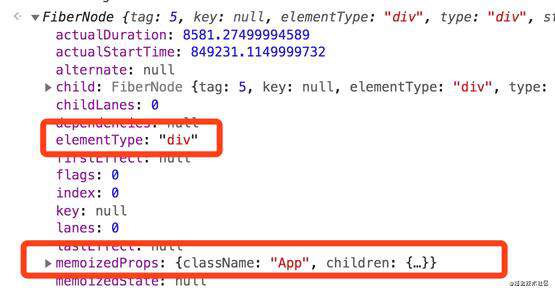
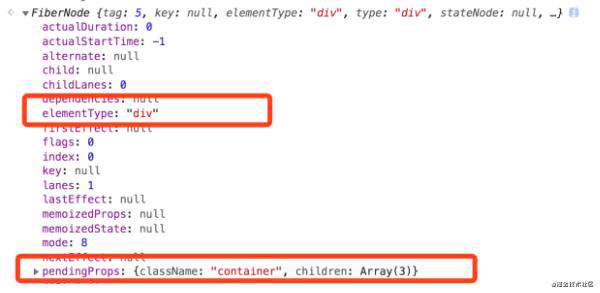
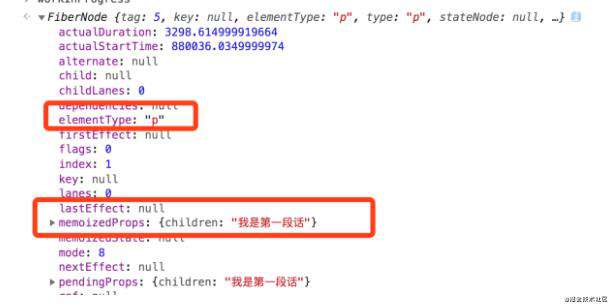
上图分别是App节点,两个div子节点,以及p标签的节点。可以看到,每一个非文本类型的ReactElement都有了它对应的Fiber节点。
这些节点之间都是相互有联系的,它们是通过child、return、sibling这 3 个属性建立关系,其中 child、return记录的是父子节点关系,而sibling记录的则是兄弟节点关系(sibling 指向的是当前节点的第 1 个兄弟节点)。
具体看下图:

以上便是workInProgress Fiber树的最终形态了。从图中可以看出,虽然人们习惯上仍然将眼前的这个产物称为Fiber树,但它的数据结构本质其实已经从树变成了链表。
下面来看另一个completeWork流程。
completeUnitOfWork(completeWork流程)
上文曾经说过,performUnitOfWork中在beginWork流程遍历到叶子节点之后,next就会变成null,当次beginWork流程结束,进入相对应的``completeWork`流程。
重新引用一下上面用到的performUnitOfWork方法里的代码
next = beginWork(current, unitOfWork, subtreeRenderLanes);
if (next === null) {
// If this doesn't spawn new work, complete the current work.
completeUnitOfWork(unitOfWork);
} else {
workInProgress = next;
}
completeUnitOfWork是一个遍历循环的方法,将会遍历循环下面几件事
- 1.调用
completeWork方法 - 2.将当前节点的副作用链(
EffectList)插入到其父节点的副作用链(EffectList)中 - 3.以当前节点为起点,循环遍历其兄弟节点及其父节点。当遍历到兄弟节点时,将
return掉当前调用,触发兄弟节点对应的performUnitOfWork逻辑;而遍历到父节点时,则会直接进入下一轮循环,也就是重复 1、2 的逻辑
我们先来看completeWork方法。
completeWork(completeWork流程)
completeWork源码地址
completeWork也是一个体量比较大的函数,我们只抽离关键的逻辑
function completeWork(current, workInProgress, renderLanes) {
// 取出 Fiber 节点的属性值,存储在 newProps 里
var newProps = workInProgress.pendingProps;
// 根据 workInProgress 节点的 tag 属性的不同,决定要进入哪段逻辑
switch (workInProgress.tag) {
......
// h1 节点的类型属于 HostComponent,因此这里为你讲解的是这段逻辑
case HostComponent:
{
popHostContext(workInProgress);
var rootContainerInstance = getRootHostContainer();
var type = workInProgress.type;
// 判断 current 节点是否存在,因为目前是挂载阶段,因此 current 节点是不存在的
if (current !== null && workInProgress.stateNode != null) {
updateHostComponent$1(current, workInProgress, type, newProps, rootContainerInstance);
if (current.ref !== workInProgress.ref) {
markRef(workInProgress);
}
} else {
// 针对异常情况进行 return 处理
......
// 接下来就为 DOM 节点的创建做准备了
var currentHostContext = getHostContext();
// _wasHydrated 是一个与服务端渲染有关的值,这里不用关注
var _wasHydrated = popHydrationState(workInProgress);
// 判断是否是服务端渲染
if (_wasHydrated) {
......
} else {
// 这一步很关键, createInstance 的作用是创建 DOM 节点
var instance = createInstance(type, newProps, rootContainerInstance, currentHostContext, workInProgress);
// appendAllChildren 会尝试把上一步创建好的 DOM 节点挂载到 DOM 树上去
appendAllChildren(instance, workInProgress, false, false);
// stateNode 用于存储当前 Fiber 节点对应的 DOM 节点
workInProgress.stateNode = instance;
// finalizeInitialChildren 用来为 DOM 节点设置属性
if (finalizeInitialChildren(instance, type, newProps, rootContainerInstance)) {
markUpdate(workInProgress);
}
}
......
}
return null;
}
case HostText:
{
......
}
case SuspenseComponent:
{
......
}
case HostPortal:
......
return null;
case ContextProvider:
......
return null;
......
}
}
首先我们需要知道,进入这个completeWork的参数是什么,我们知道只有当beginWork结束,也就是遍历到第一个叶子节点的时候,才会进入completeWork方法。所以,第一次运行的时候的参数,其实是demo中的h1标签相对应的fiber节点对象。这也是completeWork的一个特点,是严格自底向上运行的。
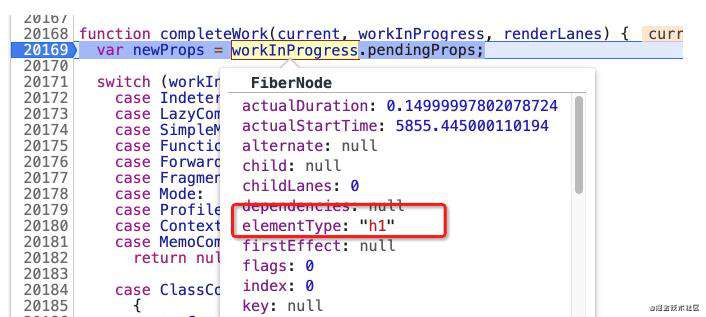
然后我们再来看completeWork方法几个功能要点
- 1.
completeWork的核心逻辑是一段体量巨大的switch语句,在这段switch语句中,completeWork将根据workInProgress节点的tag属性的不同,进入不同的DOM节点的创建、处理逻辑。 - 2.在
Demo示例中,h1节点的tag属性对应的类型应该是HostComponent,也就是原生DOM元素类型。 - 3.
completeWork中的current、workInProgress就是之前说的current树和workInProgress树上面的节点。
其中workInProgress树代表的是“当前正在render中的树”,而current树则代表“已经存在的树”。
workInProgress节点和current节点之间用alternate属性相互连接。在组件的挂载阶段,current树只有一个顶部节点,并没有其他内容。因此h1这个workInProgress节点对应的current节点是null。
带着这个前提,我们再来看看completeWork方法,我们可以总结出
completeWork其实就是负责处理Fiber节点到DOM节点的映射逻辑。通过三个步骤
- 1.创建
DOM节点(CreateInstance) - 2.将
DOM节点插入到 DOM 树中(AppendAllChildren),赋值给workInProgress节点的stateNode属性(而且当前节点运行AppendAllChildren时,会逐个向下查找自己的后代子 Fiber 节点,并把所对应的 DOM 节点挂载到其父 Fiber 节点所对应的 DOM 节点里去,所以最上级的节点里的stateNode属性,就是一个完整的dom树) - 3.为
DOM节点设置属性(FinalizeInitialChildren)

completeUnitOfWork第2,3步(completeWork流程)
先来看第三步的代码实现
以当前节点为起点,循环遍历其兄弟节点及其父节点。当遍历到兄弟节点时,将return掉当前调用,触发兄弟节点对应的performUnitOfWork逻辑;而遍历到父节点时,则会直接进入下一轮循环,也就是重复 1、2 的逻辑
do {
......
// 这里省略步骤 1 和步骤 2 的逻辑
// 获取当前节点的兄弟节点
var siblingFiber = completedWork.sibling;
// 若兄弟节点存在
if (siblingFiber !== null) {
// 将 workInProgress 赋值为当前节点的兄弟节点
workInProgress = siblingFiber;
// 将正在进行的 completeUnitOfWork 逻辑 return 掉
return;
}
// 若兄弟节点不存在,completeWork 会被赋值为 returnFiber,也就是当前节点的父节点
completedWork = returnFiber;
// 这一步与上一步是相辅相成的,上下文中要求 workInProgress 与 completedWork 保持一致
workInProgress = completedWork;
} while (completedWork !== null);
功能比较简单,按demo来说,因为beginWork流程是一个深度优先遍历,当遍历到h1标签时,遍历中断,开始执行completedWork流程。h1的兄弟节点p标签,其实连beginWork流程还没有运行过,所以需要重新调用performUnitOfWork逻辑。
我们再来说一下第二步
将当前节点的副作用链(EffectList)插入到其父节点的副作用链(EffectList)中。
这一步的目标其实就是找出界面中需要处理的更新。因为在实际的操作中,并不是所有的节点上都会产生需要处理的更新。比如在挂载阶段,对整棵workInProgress树递归完毕后,React会发现实际只需要对App节点执行一个挂载操作就可以了;而在更新阶段,这种现象更为明显。
怎样做才能让渲染器又快又好地定位到那些真正需要更新的节点呢?这就是副作用链(effectList)的功能。
每个Fiber节点都维护着一个属于它自己的effectList,effectList在数据结构上以链表的形式存在,链表内的每一个元素都是一个Fiber节点。这些Fiber节点需要满足两个共性:
- 都是当前
Fiber节点的后代节点(并非它自身的更新,而是其需要更新的后代节点) - 都有待处理的副作用
这个effectList链表在Fiber节点中是通过firstEffect和lastEffect来维护。firstEffect表示effectList的第一个节点,而lastEffect则记录最后一个节点。
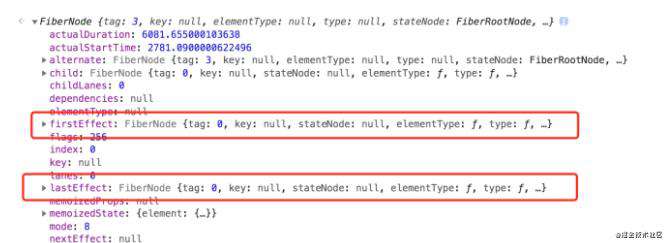
因为completeWork是自底向上执行的,所以在顶部节点上可以拿到一个存储了当前Fiber树所有effect Fiber。
按demo来说,只有顶部的节点才会存在副作用链(App组件的fiber节点),对于App组件内的所有子节点都不存在副作用链。当首次渲染或者更新的时候,渲染器只会去处理副作用链上的App fiber节点(App作为一个最小的更新组件,已经包含了内部子元素的dom节点)。当然如果App里面还引用了其他组件,App组件的fiber中也会包含该组件的副作用链。
commit阶段
commit会在performSyncWorkOnRoot中被调用,它是一个绝对同步的过程。
commitRoot(root);
源码地址
从流程上来说,commi共分为 3 个阶段:before mutation、mutation、layout。
-
before mutation阶段,这个阶段DOM节点还没有被渲染到界面上去,过程中会触发getSnapshotBeforeUpdate,也会处理useEffect钩子相关的调度逻辑。 -
mutation,这个阶段负责DOM节点的渲染。在渲染过程中,会遍历effectList,根据flags(effectTag)的不同,执行不同的DOM操作。 -
layout,这个阶段处理DOM渲染完毕之后的收尾逻辑。比如调用componentDidMount/componentDidUpdate,调用useLayoutEffect钩子函数的回调等。除了这些之外,它还会把fiberRoot的current指针指向workInProgress Fiber树。
感谢
如果本文对你有所帮助,请帮忙点个赞,感谢!
常见问题FAQ
- 免费下载或者VIP会员专享资源能否直接商用?
- 本站所有资源版权均属于原作者所有,这里所提供资源均只能用于参考学习用,请勿直接商用。若由于商用引起版权纠纷,一切责任均由使用者承担。更多说明请参考 VIP介绍。
- 提示下载完但解压或打开不了?
- 找不到素材资源介绍文章里的示例图片?
- 模板不会安装或需要功能定制以及二次开发?





发表评论
还没有评论,快来抢沙发吧!