0.前言
说到第一次接触无刷新改变url,是在一次应聘的过程中遇到的,面试我的正是我现在所在公司的JAVA架构师。说实话,我还真的没有接触过这种需求,所以当时提的这个需求立马把我整懵逼了(/笑哭)。 最近突然想起来了这回事,所以大发兴致的研究了研究,感觉还是有些东西可以分享一下的。 这篇文章篇幅较长,大概分为下面几部分
- 无刷新改变url的应用场景
- History API的解释,实际上是对MDN文档上讲的不清楚的部分的解释
- 多页面应用中无刷新改变url的演示
- 单页面中无刷新改变url的演示
- vue-router中对History API的使用
1.无刷新改变url的应用场景
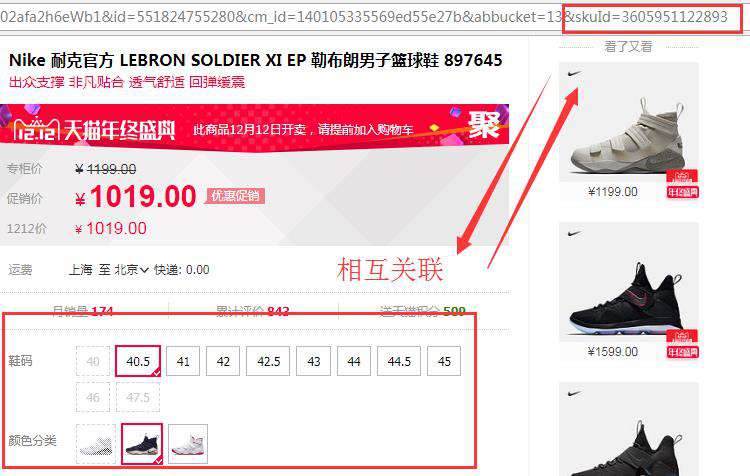
在我目前看来,这种方式的应用场景主要是为了利用url来存储我们需要的信息:一种是我们自己需要一个临时的数据暂存区,比如说SPA的分页/查询功能,我们将查询参数拼接到url中临时储存起来;另一种是我们在做分享类的内容时,让用户复制url时能够同时保存下来用户的操作内容,很典型的例子就是淘宝的商品页。我们选择的很多sku(商品属性)内容,都会被挂到url中,分享给好友时,他们无需任何操作就能知道我们选择了那些内容。
2.Window.History API
我们从控制台上可以很清楚的看到History对象的属性和方法,
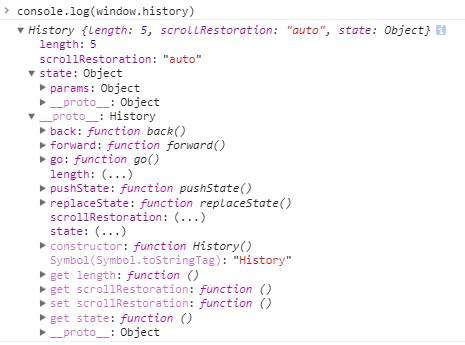
| 属性/方法 | 功能 | length | 表示当前页面的浏览历史长度,刚打开的页面length=1 | scrollRestoration | 设置滚动恢复行为 | state | 当浏览器的url中有参数时,在state中可以查到 | back | 页面回退(回退至最后一个历史时,无效果,不报错) | forward | 页面前进(前进至第一个时,无效果,不报错) | go(number) | 可以跳跃到指定的浏览历史,number为正,向前跳跃,反之,向后跳跃 | pushState | 向浏览器中写入一个历史记录,但浏览器不会加载这个地址 | replaceState | 替换一条历史记录 | popState | 浏览记录发生改变时触发的事件 |
|---|
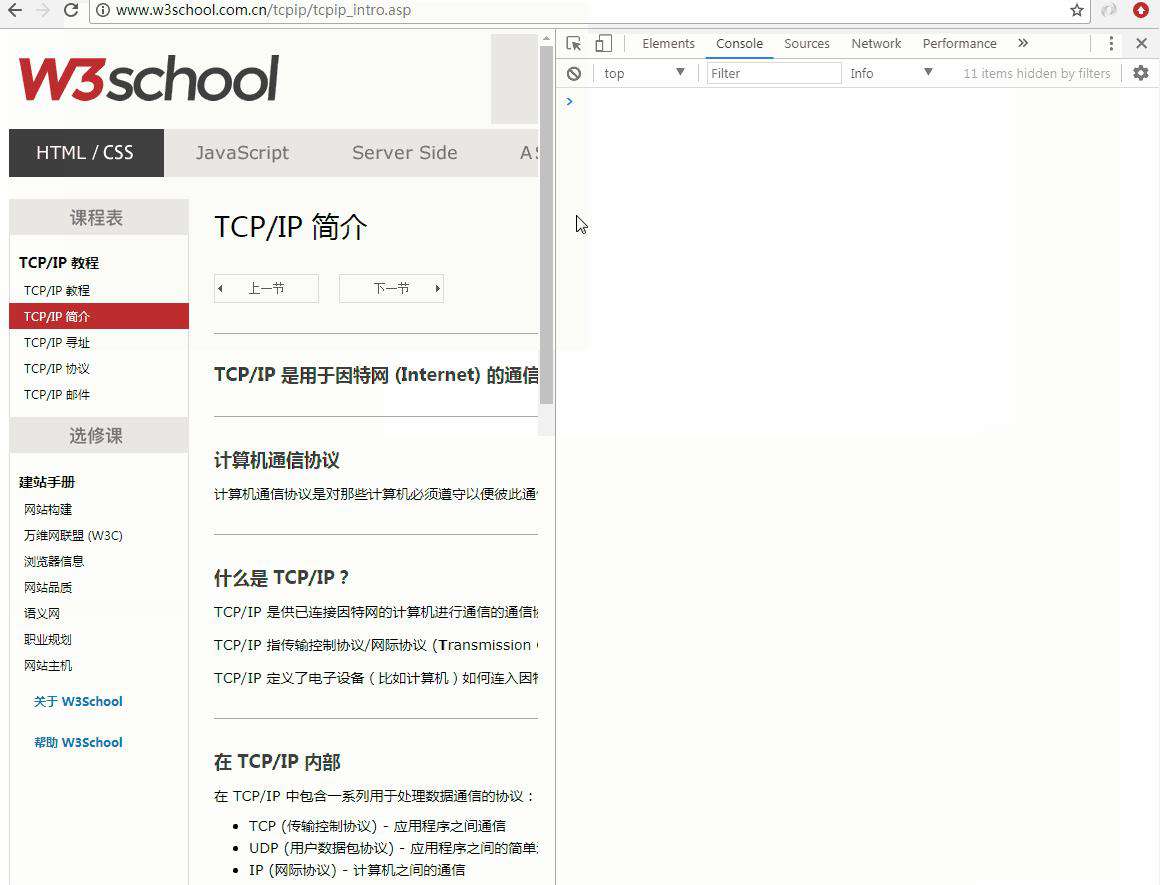
- scrollRestoration 设置滚动恢复行为
通俗的来讲就是,当我们从当前页面跳转到a页面,随后又从a页面回退过来的时候,我们的页面是否应该自动滚动到我们之前浏览的位置。
scrollRestoration默认值是auto,默认滚动恢复。另外一个值是manual,表示不会默认恢复,我们可以选择手动滚动页面。
下面这个图片应该能够更直观的显现出来
 2.pushState/replaceState
在说这两个方法之前,我们先来唠一下History的state属性,state属性表示的是当前历史下的状态值,可以从中读取到当前的状态信息。我们可以将state理解为一个栈,当网页历史增加时,浏览器会往这个栈中推入一个状态信息,我们的state也指向这个最顶部的状态信息;当我们回退时,state就会进行出栈操作,前一个历史的状态信息就成为了这个栈的顶部。
这样解释的话,pushState就更加容易理解了,就是往state中推入一个新的历史。
pushState的语法很简单:
2.pushState/replaceState
在说这两个方法之前,我们先来唠一下History的state属性,state属性表示的是当前历史下的状态值,可以从中读取到当前的状态信息。我们可以将state理解为一个栈,当网页历史增加时,浏览器会往这个栈中推入一个状态信息,我们的state也指向这个最顶部的状态信息;当我们回退时,state就会进行出栈操作,前一个历史的状态信息就成为了这个栈的顶部。
这样解释的话,pushState就更加容易理解了,就是往state中推入一个新的历史。
pushState的语法很简单:
history.pushState(state, title, url);
@ state:与历史纪录相关的一个对象,在后面讲到的popState中会体现出来其作用。
要注意的一点是,这个对象一定要是一个可以进行序列化的对象,如果我们传一个DOM对象进去,会报错。
@ title:具体作用不祥,而且大多数浏览区忽略了这个参数,个人习惯用传入""
@ url:新历史记录的url值,在地址栏会有体现,但是不会加载这个url的资源。
这也是我们实现无刷新改变url的关键点,但是一定要注意,新旧url一定是同源的,否则会报错。
另外补充一点,pushState方法在一种情况下是和window.localtion有着一样的效果,即我们期望改变url的哈希值。我们都知道,浏览器是不会加载#后面的内容的,所以在这种情况下,才出现了location与history.pushState效果一致的现象。
3.popState
在浏览器历史变更时触发,触发该事件时,浏览器会对state对象进行一个拷贝,姑且称之为copyState。如果是新增历史,那么就会在copyState顶部推入一个新的状态信息,如果是后退历史,那么就会移除copyState顶部的状态信息。
虽然个人在实际场景用没有使用过这个方法,但是感觉还是很有操作空间的,比如说下面的一些小套路:
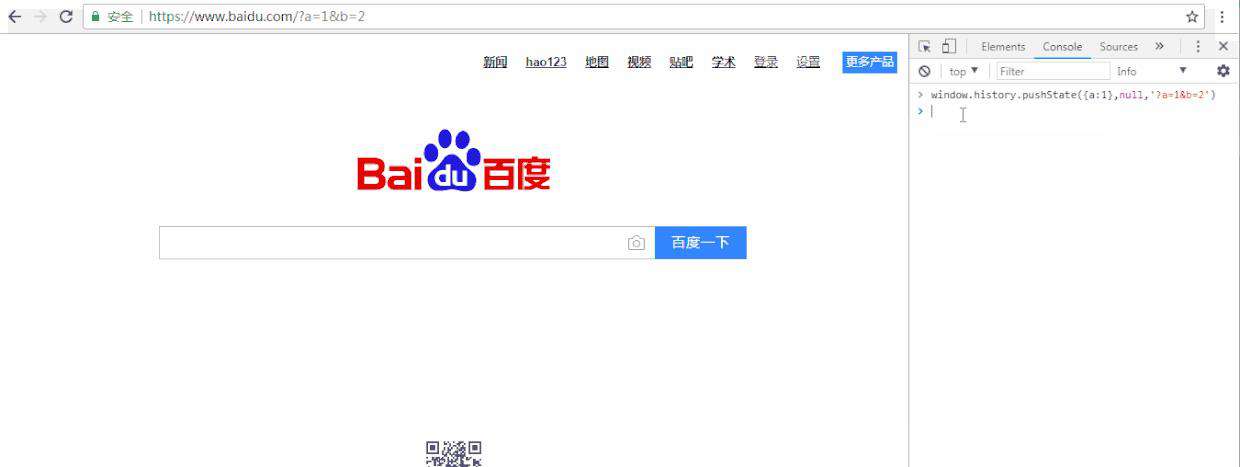
这里要注意的是,popstate触发的必须条件一是两条历史必须同源,如果是非同源历史,那么这个事件就会无反应;二是历史记录必须是有pushState或replaceState创建
3.多页面应用中的实现
只要阅读了上面的内容,相信你们应该都已经大概想到了实现方式。 通过利用pushState/replaceState这两个API,来控制浏览器的历史记录,如果需要记录历史呢,就选择pushState API,如果需要替换记录,就选择replaceState。这里要注意,不合理的使用pushState,会导致浏览器的回退按钮一直回退一些乱七八糟的历史噢。
具体代码不贴了,简单的一匹,估计你们也就敲两下键盘就出来了。这里也有一个小小的坑,就是一定要在服务器环境下测试,如果地址栏中的url是你本地文件的路径的话,会送给你一个鲜红的错误警告~。(如果没有线上服务器的条件的的话,HBuilder的内置服务器也是可以的)
有人可能到现在也不是很清楚具体的应用场景。
这样,我们可以假定一个应用场景:这周末,你准备与朋友准备去海底捞聚餐,在选择分店的页面中你挑选了一个自己认为比较合适的,然后将这个网址分享给了朋友,想参考一下他们的意见。 哎,这样你分享出去的链接就不能是你刚刚进入的选择分店的网址了,因为那样,朋友在点开这个网址的时候,仍需要重复刚刚我们选择分店的这个过程,所以我们分享的这个链接中应该包含了将我们选择的一些关键的信息。 看下面的模拟程序:
// 假定 newState 是需要保存在url中的关键信息
let newState = {
timeStamp: new Date().getTime(), //分享n长时间后,链接失效
address: '北京市朝阳区',
areaCode:'011011',
shopName:'海底捞XX店',
shopCode:'0125'
}
// 获取请求字段字符串
function getQueryString(obj) {
let newQuery = []
if (obj instanceof Object != true) return ''
if (Object.keys(obj).length == 0) return ''
for (let x in obj) {
newQuery.push(`${x}=${obj[x]}`)
}
return `?${newQuery.join('&')}`
}
// 原url和queryStrng 进行拼接,组合成新的url 并进行历史记录的替换
function changeUrl(obj) {
let newUrl = window.location.pathname + getQueryString(obj)
window.history.replaceState(newState, null, 'a.html');
}
ok,在上面的代码中,我们粗糙的实现了一个在url中无刷新添加参数的例子。通过在用户在页面中的某些动作,比如点击查询按钮,或者下拉框触发change事件等,来触发我们的changeUrl,实现某些用户操作的保存。
###4.在单页面应用中的实现 原本只是打算着写一个在SPA中利用路由实现的方法(以Vue为例),但是后来想了想,又觉得不妥,感觉还是要把路由中的具体实现写一下比较好。可能在插件中的实现原理,才是大家希望看到的东西,那样也算是授人以渔吧。
所以这里先将方法码出来,后面再分析一下Vue中的vue-router是如何利用History的这些API的。
下面先上一张演示图片,大家感受一下:
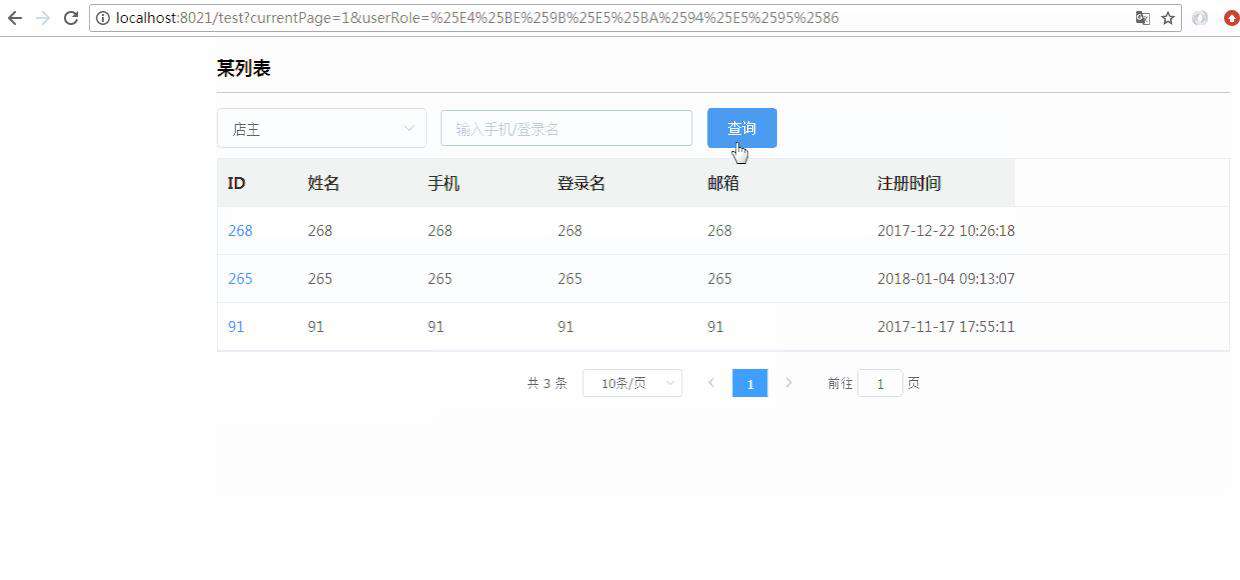
简述:
上面演示的这部分内容,主要就是在利用url中的search字段,来达到保存操作记录的目的。为什么要采用这种模式呢?
-
如果在类似的列表页中,不对搜索条件进行记录的话,我们在点击其中一条ID查看详情,路由就会相应的切换到详情页面,这里是ok的。但当我们浏览完毕,从详情页返回的时候,列表页会重新加载,我们就得重新输入搜索条件。这样的体验是相当的糟糕,尤其是在选项繁多的时候。
-
Vue中自带
keep-alive的组件缓存功能,能够帮我们解决上面这个问题。但聪明的我发现,在使用keep-alive以后,确实能够保证组件不会重新渲染,但是在其他页面做的一些修改,并不能及时的体现在我们的列表页上。因为页面上的数据还是上一次请求的旧数据,这可能会让用户产生误解。 -
同文章前面提到的淘宝页面,用户在分享我们的url链接时,被分享者不需要任何的附加操作。
######实现:
先来一张酷丑酷丑的流程图
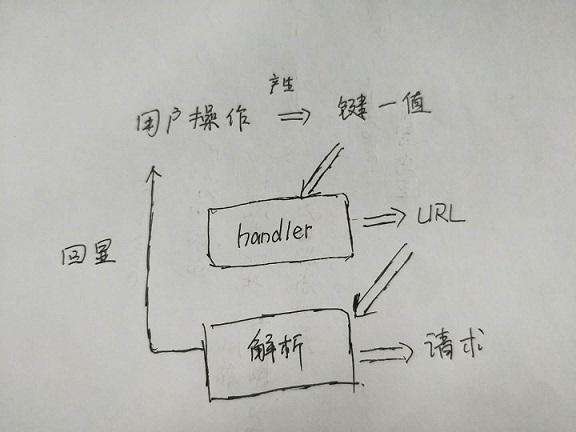 ######ps:没有银弹!下列代码仅限于参考,应根据实际场景进行相应的修改。
######1.用户操作产生参数:key-value
上面的实例中,每次有效的操作,都会通过key=value这种形式保存下来。So,上例中规定:用户角色=userRoles,搜索内容=content,当前页码=currentPage。
######ps:没有银弹!下列代码仅限于参考,应根据实际场景进行相应的修改。
######1.用户操作产生参数:key-value
上面的实例中,每次有效的操作,都会通过key=value这种形式保存下来。So,上例中规定:用户角色=userRoles,搜索内容=content,当前页码=currentPage。
2.Handler
定义一个Handler,目的就是处理key-value与url参数的转化。示例代码:
import router from '@/router'
import store from '@/store'
//创建临时存储区
let temporary = {}
export function createTemporary(){
temporary = getRouteQuery()
}
/**
* setTemporary url缓存数据暂存区
* @param key 扩展属性名
* @param value 扩展属性值
*/
export function setTemporary(key, value) {
temporary[key] = encodeURI(value)
}
/**
* getRouteQuery 获取路由query对象
* key-point:一定要是深拷贝
*/
function getRouteQuery() {
return JSON.parse(JSON.stringify(router.currentRoute.query))
}
/**
* extendQuery 在原来query对象基础上 进行暂存区数据的扩展
* @param temporary 扩展属性集合
*/
export function extendQuery() {
let query = getRouteQuery()
for (let key in temporary) {
query[key] = temporary[key]
}
router.replace({
query: query
})
}
/**
* directExtendQuery 立即写入query,针对页码等不需要使用暂存的数据
*/
export function directExtendQuery(key, value) {
let query = getRouteQuery()
query[key] = value
router.replace({
query: query
})
}
我们规定改变url的操作叫写入操作。
- 定义一个暂存器
temporary,用于暂存用户操作,在触发写入操作时,将暂存器中数据写入url。 - 获取路由对象中的参数部分,在router.currentRoute.query中即可获取。这里有一个坑,就是一定要将路由对象深拷贝,否则你接下来的操作相当于直接操作原query对象,结局很美,切记!暂存器的内容转化成query对象。在浏览器中,添加到url里的汉字会被自动解码,所以,涉及到汉字的我们都需要多进行一步解码工作。
- 改变路由,通过调用vue-router的replace方法来实现(这里不需要记录历史,所以不采用push方法),在实际操作中,发现改变路由有两种需求:
1.操作=>等待触发。如用户在页面中进行条件选择,选择完成后,等待点击查询按钮来触发选择条件。所以,在选择条件时,我们先将数据放入暂存器,点击查询按钮时,将数据从缓存器中取出。 2.操作=>立即触发。如改变当前页码,需要立即改变url中的currentPage
3.解析URL
示例代码:
/**
* @function getUrlQuery
* @description 接收外部传来的字段,从url的query中获取字段对应的值
* @argument norClass 需要直接取值的字段集合
* @argument speClass 需要decodeURI取值的字段集合
*/
export function getUrlQuery(norClass, speClass, norDefault = '', speDefault = '') {
return Object.assign({}, loopFetch(norClass, directQuery, norDefault), loopFetch(speClass, decodeQuery, speDefault))
}
/**
* 循环取值,传入待取值对象和取值方式
* @param { Object } object
* @param { Function } fn
* @param { string } default
*/
function loopFetch(object, fn, defaults) {
if (!object) {
return {}
}
let o = {}
for (let i in object) {
o[i] = fn(object[i], defaults)
}
return o
}
/**
* directQuery/decodeQuery 缓存字段获取
*/
export function directQuery(key, defaults = '') {
return router.currentRoute.query[key] ? router.currentRoute.query[key] : defaults
}
export function decodeQuery(key, defaults = '') {
return router.currentRoute.query[key] ? decodeURI(decodeURI(router.currentRoute.query[key])) : defaults
}
上面的流程图中,解析url的目的有两个,所以我们需要暴露出两种接口来满足需求。
- 控制页面回显的
directQuery/decodeQuery函数,之所以定义两个函数,是为了处理value中包含汉字的情况,转码的时候进行了两遍encode,所以解码的时候也需要两边decode。 - 在
directQuery/decodeQuery函数的基础上扩展的getUrlQuery函数,用于获取发送请求的参数。
在使用url存储数据后,在请求参数的获取上也需要进行相应的调整:涉及到使用url的字段,都应该改为从url中获取。
getUrlQuery函数针对不同的字段,分别采用directQuery/decodeQuery函数,返回一个参数的字典对象。
4.回显
import * as routeFn from '@/util/route-query'
//...其他代码省略
methods:{
...,
//从url中拉取信息
_initQuerys() {
this.pagination.current = +routeFn.directQuery('currentPage', 1)
this.content= routeFn.decodeQuery('content')
this.userRole = routeFn.decodeQuery('userRole')
},
...
}
created() {
//初始化暂存器
routeFn.createTemporary()
this._initQuerys()
}
代码很明显,不多赘述。
5.请求
前面提到了,请求参数中凡是涉及到url的,都改为从url中获取。所以,我们请求的方法就需要做一定的调整了。
import * as routeFn from '@/util/route-query'
...
getParam() { //获取optional对象
let param = {
mobileName: 'content',
userRole: 'userRole'
}
return routeFn.getUrlQuery({}, param,this.$route.query)
},
// 由于当前项目前后台对于列表页传参的约束,请求方法对比常规请求略有不同。
// 在此,只需要关注params部分即可
sendRes() {
let params = {
apiPath: userList, //请求API地址
currentPage: routeFn.directQuery('currentPage', 1,this.$route.query),
pageSize: this.pageSize,
optional: Object.assign({}, this.getParam(), {
roleList: isNeed(this.roleOptions)
})
}
sendInfo(params).then((res) => {
if (res.data.code == 200) {
this.pagination.total = res.data.userCount;
this.tableData = res.data.userListInfoList || [];
}
})
}
当前接口限制,api,currentPage,pageSize为必传内容,其他内容为非必传,所以 采用一个optional字段来统一控制选传内容。 在处理参数时,采用多个对象合并的方案:即默认的空对象(作为缺省值)、通过url获取的的参数对象、其他参数组成的对象,这样的方法能够涵盖所有的参数。 ###5.单页面路由中是History API具体应用 国内的Vue用户数量还是相当的嗯哼的,所以就vue-router为例吧。相信Vue用户也大都阅读过vue-router的文档,对vue-router的使用也应该是66的,so,这里就省略了对vue-router的介绍(此处省略200字....-_-)。我在看vue-router源码的时候,感觉跟History联系最紧密的,应该是vue-router提供的编程式导航的方法和内部模拟浏览器滚动的处理了,所以这里就针对这两个简单的分析一下。
1.编程式导航(history.pushState和history.replaceState)
先来摘出来文档上的部分内容:
跟 router.push 很像,唯一的不同就是,它不会向 history 添加新记录,而是跟它的方法名一样 —— 替换掉当前的 history 记录。
这个方法的参数是一个整数,意思是在 history 记录中向前或者后退多少步,类似 window.history.go(n)。
怎么样,看到push/replace/go这些方法是不是特别的熟悉 ╮(╯▽╰)╭ ? Yes,这些方法不就是Histroy pushState/replaceState/go 方法的简写吗.... vue-router中会首先进行浏览器的兼容性判断
export const supportsPushState = inBrowser && (function () {
const ua = window.navigator.userAgent
if (
(ua.indexOf('Android 2.') !== -1 || ua.indexOf('Android 4.0') !== -1) &&
ua.indexOf('Mobile Safari') !== -1 &&
ua.indexOf('Chrome') === -1 &&
ua.indexOf('Windows Phone') === -1
) {
return false
}
return window.history && 'pushState' in window.history
})()
如果是安卓2.x或者安卓4.0的window Phone手机(同时不是移动端safari和chrome) 都返回false 表示不支持pushState ,防止在调用window.history.xx方法时报错。 下面是调用history api的代码
export function pushState (url?: string, replace?: boolean) {
saveScrollPosition() //保存当前页面滚动位置
const history = window.history
try {
if (replace) {
history.replaceState({ key: _key }, '', url)
} else {
_key = genKey()
history.pushState({ key: _key }, '', url)
}
} catch (e) {
window.location[replace ? 'replace' : 'assign'](url)
}
}
export function replaceState (url?: string) {
pushState(url, true)
}
暴露出来两个同名方法pushState/replaceState,在基础的histroy.pushState/replaceState方法上进行了一层包装来带代替原生的方法。看源码中的解释,意思是Safari中会限制pushState调用不能超过100次,超过这个限制将会抛出一个编号18的DOM异常错误。(实测确实存在这个问题)所以通过try catch 来绕过pushState API在Safari中的调用,报错以后,使用location的assign/replace方法来代替处理。同时也将原来需要传入3个参数,变成了只需传入一个目标地址。 这里将处理过程都放在了pushState中,根据布尔类型的replace字段来判断是push还是replace。里面有一个getKey和saveScrollPosition方法,这个是用来记录浏览器当前位置,后面的内容会分析到。 如果对上面的异常有兴趣,可以在Safari中运行这段代码检查结果:
let i = 0;
setInterval(()=>{history.pushState("",null,Date.now());console.log(i++)},200)
router.push/replace的实现其实就是相当于给pushState/replaceState套了一个壳子,调用的际上还是pushState/replaceState。这个壳子的作用就是将这个两个方法加到了vue-router创建的History类上,并且暴露了用户。
router的另外几个方法:go/back/forward利用的则是history.go
go (n: number) {
this.history.go(n)
}
back () {
this.go(-1)
}
forward () {
this.go(1)
}
2.滚动行为(history.popstate 和 history.scrollRestoration)
可能很多人都没有用过vue-router提供的这个滚动行为,所以我这里先解释一下
首先,滚动行为的目的是让你在切换路由时候,控制页面是否滚动或者页面到底该怎么滚动。
vue-router提供一个scrollBehavior方法,其效果类似于scrollTo(x,y)
const router = new VueRouter({
routes: [...],
scrollBehavior (to, from, savedPosition) {
// return 期望滚动到哪个的位置
//方式1 滚动到某一个具体的坐标
return { x: 0, y: 0 }
// 方式2 滚动到某个元素(string是元素名),或者滚动到某个元素附近(有偏移量)
return { selector: string, offset? : { x: number, y: number }}
//方式3
if (savedPosition)
{ return savedPosition
} else {
return { x: 0, y: 0 }
}
}
})
上面的示例代码中演示了三种操作,
第一种表示路由切换时,页面总是会滚动到顶部;
第二种表示切换路由时,可以滚动到某个元素。由于vue在获取元素的时候,使用的document.querySelector,所以这里的string传入元素选择器名。offset参数为非必填项,若存在则表示在这个元素的基础上增加的滚动的距离。
第三种方式是在模拟多页面应用中浏览器的行为,即新打开页面时(增加histroy记录),页面总是滚动到顶部。在后退时,自动退到上次浏览的位置(savedPosition是上次浏览记录的位置信息,新打开页面时等于null)。
接下来就是分析vue-router中的实现方式了。
scrollBehavior是如何工作的?
在浏览器发生新增历史记录(push/replace)或者切换历史记录的时候,vue-router内部会判断用户是否是正确使用了scrollBehavior,若用户没有使用这个方法,那么将不会做任何处理,这就是为什么我们在打开一个新的路由的时候,网页的滚动条还是停留在当前位置。
确定用户正确的使用了scrollBehavior以后,会继续判断是否为popstate触发,如果是,那么就会从浏览器的历史记录中,将当前历史的位置信息取出来,赋值给savePosition,否则就将savePosition置为null。
最后,会对用户设置的scrollBehavior进行判断,用户传入具体坐标,那么就会直接调用window.scrollTo(),若用户希望滚动到某个元素上,那么就会调用元素位置的相关计算规则,来拿到需要滚动的距离并调用window.scrollTo()
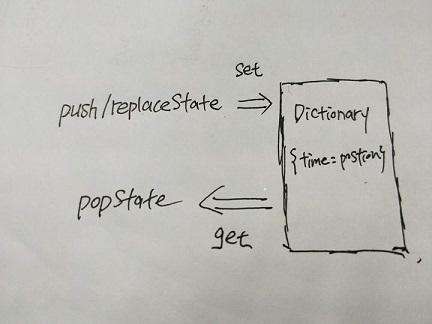
######对页面浏览器历史记录的滚动位置是如何处理的? router里定义了一个字典对象(Dictionary)来记录用户的位置信息。当我们触发路由变化时,router会向字典里面写入一条位置记录。字典key值就是触发路由变化的时间,这样就能用时间来保证key的唯一性,value则是一个记录这位置坐标的对象。所以,字典对象在运行的时候是这样的:
//key用时间戳表示
//value储存x,y坐标
dictionary:{
'1516964694736':{ x: 0, y: 0 },
'1516964698142':{ x: 0, y: 100 },
'1516964722214':{ x: 130, y: 361 },
}
//源码中对时间戳进行了toFixed(3)处理,所以真实的key应该是这样'1516964694736.000'
怎么触发写入行为?
对于新增/替换历史记录,vue-router定义了在pushState和replaceState时,向保存位置的对象中,写入一条数据,key=‘当前时间’,value=当前位置信息。
history.pushState({ key: _key }, '', url) //为了查找和更新,将时间写入state中
前面介绍Histroy时已经说了浏览器访问已经存在的历史页面时,将会触发popstate事件。所以,针对切换历史记录,vue-router在实例化时就添加了一个对popstate事件的监听,如果触发popstate事件,就会更新浏览器历史记录中的位置信息,利用state中的key。
6.结语
不知不觉就码了将近5000字了,仍然感觉有很大一部分想说,但是零零碎碎的怎么下嘴。后面我会重新组织一下,然后尝试着继续往这篇文章中再补充一部分内容。无奈文笔不佳,如果有想学习,但是看不太明白的地方,欢迎你们留言。 (๑¯◡¯๑)
常见问题FAQ
- 免费下载或者VIP会员专享资源能否直接商用?
- 本站所有资源版权均属于原作者所有,这里所提供资源均只能用于参考学习用,请勿直接商用。若由于商用引起版权纠纷,一切责任均由使用者承担。更多说明请参考 VIP介绍。
- 提示下载完但解压或打开不了?
- 找不到素材资源介绍文章里的示例图片?
- 模板不会安装或需要功能定制以及二次开发?





发表评论
还没有评论,快来抢沙发吧!