分析与思路
今天爬取的页面是http://www.ikanmv.com/k/39050.html。底下一共有10集。
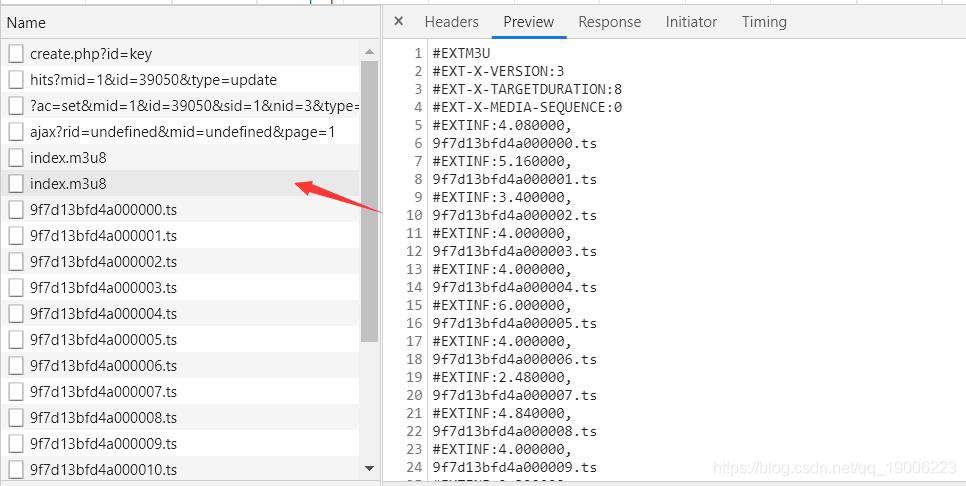
我们随便打开一集,点击network,发现视频是m3u8格式的。有两个m3u8格式文件,第一个是一些限制条件,真正的m3u8列表。后面就是列表中逐条下载的ts文件。
 我们的目标是,把一集的所有ts文件下载下来,通过
我们的目标是,把一集的所有ts文件下载下来,通过ffmpeg软件进行拼接、转化,最终生成一个.mp4文件。ffmpeg从官网下载较慢,如有需要请戳下面连接(windows10版本)。
链接: pan.baidu.com/s/1_1htbaRQ… 提取码: wivw
其实直接用ffmpeg也可以根据m3u8列表连接直接下载,但是速度较慢,咱们代码中使用多进程,加速下载。
不过还有个问题,经过测试,ffmpeg合并ts文件,一次性最多合并4、5百个(每集ts文件大概在1500~2000个之间),再多就会报错,所以我们先以300个ts文件为1组,将他们合并一下,得到几个大个的ts文件,再将这几个大个的ts文件合并成一集一个整个的ts文件,再转化mp4。
所以我们的代码流程为:==下载某集所有ts文件->合并成几个大个的ts文件->合并成一个ts文件->转化成mp4->删除没用的ts文件==
代码实现
首先创建一个文件夹D:\ts用于存放ts文件。
根据上节的代码流程,我们可以写出主函数,几个方法逐步实现:
if __name__ == '__main__':
urls = [
'https://zy.kubozy-youku-163-aiqi.com/20190710/13975_9273f090/1000k/hls/index.m3u8',
'https://zy.kubozy-youku-163-aiqi.com/20190717/14563_0eca69d7/1000k/hls/index.m3u8',
'https://zy.kubozy-youku-163-aiqi.com/20190724/15218_7487f9e5/1000k/hls/index.m3u8'
]
# 开始的集数
index = 4
for url in urls:
# 获取某集需要下载的ts列表
get_list = get_m3u8(url)
# 下载ts文件到本地
download('D:\\ts', get_list, url[0:-10])
# 合并
merge_ts('D:\\ts', str(index)+'.mp4')
# 删除没用的 ts
delete_ts('D:\\ts')
# 下一集
index = index + 1
我们模拟下载4~6集(由于没找到规律,需要手动获取几集的第二个m3u8请求连接)
随便点击两个ts连接就会发现,某一集的ts文件请求前面都是一样的,最后拼接上xxxxx00x.ts,然后get请求就可以得到某个ts视频资源了。首先获取某集所有ts文件后缀,就是==xxxxx00x.ts部分==,实现一下get_m3u8方法
# 获取某集需要下载的ts列表
def get_m3u8(url):
result = requests.get(url)
lines = result.text.split('\n')
all_ts = []
for line in lines:
if line.endswith('.ts'):
all_ts.append(line)
return all_ts
然后下载到本地
# 下载一个ts文件
def download_ts(ts, root, url):
res = requests.get(url+ts)
with open(root+"\\" + ts, 'ab') as f:
f.write(res.content)
f.flush()
print(ts+'下载完毕!')
# 下载ts文件到本地
def download(root, get_list, url):
# 已经下载过的文件
had_list = []
# 还有没下载完的就继续
while len(list(set(get_list).difference(set(had_list)))) > 0:
had_list = os.listdir(root)
# 还需要下载的
needs = list(set(get_list).difference(set(had_list)))
print('还需要下载个数为:'+str(len(needs)))
pool = Pool(10)
group = ([ts for ts in needs])
pool.map(partial(download_ts, root=root, url=url), group)
pool.close()
pool.join()
download方法,即主函数中使用的方法。第一个参数root是ts视频下载的地址,第二个参数get_list是某集所有ts文件后缀(==xxxxx00x.ts部分==),第三个参数url是某个ts请求前缀。首先这里用到了多进程,往期博客介绍过,这里照抄就好。
值得一提的时,这边有个while循环。因为多进程下载某集所有ts文件过程中,我发现可能会造成某些ts文件的丢失未下载,所以每次下载完成,我们获取已下载完成的文件名称(文件名称就是ts后缀),和某集所有的ts文件后缀,做差集。继续下载这些丢失的,知道差集为空,就证明全部下载完毕。
接下来需要合并。
# 合并ts,由于一次无法合并那么多,合并两次
def merge_ts(root, name):
os.chdir(root)
all_ts = os.listdir(root)
# 计数器
counter = 0
big_list = []
per_list = []
# 将多个ts文件名,300为一组拼接在一起
for ts in all_ts:
if counter > 300:
counter = 0
big_list.append('+'.join(per_list))
per_list = []
else:
counter = counter+1
per_list.append(ts)
batch = 0
batch_ts = []
for big in big_list:
batch = batch + 1
batch_ts.append(str(batch)+'.ts')
os.system('copy /b ' + big + f' batch{batch}.ts')
shell_str = '+'.join(batch_ts)
# 第二次拼接
os.system('copy /b '+shell_str+' '+name)
这里需要两次合并,第二次合并和转mp4格式是一个脚本操作。这里使用os.system调用系统方法,由于我们的ffmpeg已经放入到环境变量中,所以这里就是直接操作ffmpeg软件了。
生成某集的mp4文件之后,我们需要删除根目录下所有的.ts文件,一来节约硬盘空间,二来为下一集下载.ts文件清除干扰。
def delete_ts(root):
os.chdir(root)
all_file = os.listdir(root)
for file in all_file:
if file.endswith('.ts'):
os.remove(root+'\\'+file)
以上我们就可以下载到喜欢看的视频了。喜欢的小伙伴快去试试吧~
常见问题FAQ
- 免费下载或者VIP会员专享资源能否直接商用?
- 本站所有资源版权均属于原作者所有,这里所提供资源均只能用于参考学习用,请勿直接商用。若由于商用引起版权纠纷,一切责任均由使用者承担。更多说明请参考 VIP介绍。
- 提示下载完但解压或打开不了?
- 找不到素材资源介绍文章里的示例图片?
- 模板不会安装或需要功能定制以及二次开发?



发表评论
还没有评论,快来抢沙发吧!