
1.简介
XPath是一门在 XML 文档中查找信息的语言。XPath 用于在 XML 文档中通过元素和属性进行导航。
相比于BeautifulSoup,Xpath在提取数据时会更加的方便。
2. 安装
在Python中很多库都有提供Xpath的功能,但是最基本的还是lxml这个库,效率最高。在之前BeautifulSoup章节中我们也介绍到了lxml是如何安装的。
pip install lxml
3. 语法
XPath 使用路径表达式在 XML 文档中选取节点。节点是通过沿着路径或者 step 来选取的。
我们将用以下的HTML文档来进行演示:
html_doc = '''<html><head></head><body> <bookstore> <book category="COOKING"> <title lang="en">Everyday Italian</title> <author>Giada De Laurentiis</author> <year>2005</year> <price>30.00</price> </book> <book category="CHILDREN"> <title lang="en">Harry Potter</title> <author>J K. Rowling</author> <year>2005</year> <price>29.99</price> </book> <book category="WEB"> <title lang="en">XQuery Kick Start</title> <author>James McGovern</author> <author>Per Bothner</author> <author>Kurt Cagle</author> <author>James Linn</author> <author>Vaidyanathan Nagarajan</author> <year>2003</year> <price>49.99</price> </book> <book category="WEB"> <title lang="en">Learning XML</title> <author>Erik T. Ray</author> <year>2003</year> <price>39.95</price> </book> </bookstore></body></html>'''
导入语句,并生成HTML的DOM树:
from lxml import etree page = etree.HTML(html_doc)
3.1. 路径查找
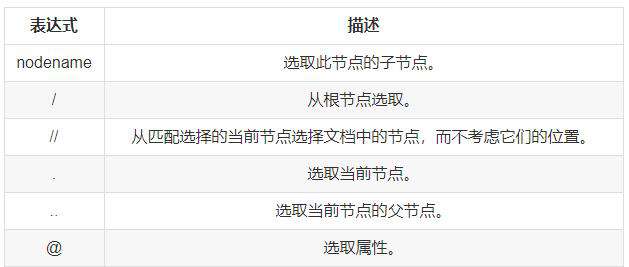
查找当前节点的子节点
In [1]: page.xpath('head')
Out[1]: [<Element head at 0x111c74c48>]从根节点进行查找
In [2]: page.xpath('/html')
Out[2]: [<Element html at 0x11208be88>]从整个文档中所有节点查找
In [3]: page.xpath('//book')
Out[3]:
[<Element book at 0x1128c02c8>, <Element book at 0x111c74108>, <Element book at 0x111fd2288>, <Element book at
0x1128da348>]选取当前节点的父节点
In [4]: page.xpath('//book')[0].xpath('..')
Out[4]: [<Element bookstore at 0x1128c0ac8>]选取属性
In [5]: page.xpath('//book')[0].xpath('@category')
Out[5]: ['COOKING']3.2. 节点查找

nodename[1]
选取第一个元素。
nodename[last()]
选取最后一个元素。
nodename[last()-1]
选取倒数第二个元素。
nodename[position()<3]
选取前两个子元素。
nodename[@lang]
选取拥有名为 lang 的属性的元素。
nodename[@lang='eng']
选取拥有lang属性,且值为 eng 的元素。
选取第二个book元素
In [1]: page.xpath('//book[2]/@category')
Out[1]: ['CHILDREN']选取倒数第三个book元素
In [2]: page.xpath('//book[last()-2]/@category')
Out[2]: ['CHILDREN']选取第二个元素开始的所有元素
In [3]: page.xpath('//book[position() > 1]/@category')
Out[3]: ['CHILDREN', 'WEB', 'WEB']选取category属性为WEB的的元素
In [4]: page.xpath('//book[@category="WEB"]/@category')
Out[4]: ['WEB', 'WEB']3.3. 未知节点

匹配第一个book元素下的所有元素
In [1]: page.xpath('//book[1]/*')
Out[1]:
[<Element title at 0x111f76788>,
<Element author at 0x111f76188>,
<Element year at 0x1128c1a88>,
<Element price at 0x1128c1cc8>]3.4. 获取节点中的文本
用text()获取某个节点下的文本
In [1]: page.xpath('//book[1]/author/text()')
Out[1]: ['Giada De Laurentiis']如果这个节点下有多个文本,则只能取到一段。
用string()获取某个节点下所有的文本
In [2]: page.xpath('string(//book[1])')
Out[2]: '\n Everyday Italian\n Giada De Laurentiis\n3.5. 选取多个路径
通过在路径表达式中使用“|”运算符,您可以选取若干个路径。
In [1]: page.xpath('//book[1]/title/text() | //book[1]/author/text()')
Out[1]: ['Everyday Italian', 'Giada De Laurentiis']
常见问题FAQ
- 免费下载或者VIP会员专享资源能否直接商用?
- 本站所有资源版权均属于原作者所有,这里所提供资源均只能用于参考学习用,请勿直接商用。若由于商用引起版权纠纷,一切责任均由使用者承担。更多说明请参考 VIP介绍。
- 提示下载完但解压或打开不了?
- 找不到素材资源介绍文章里的示例图片?
- 模板不会安装或需要功能定制以及二次开发?





发表评论
还没有评论,快来抢沙发吧!