
Scrapy是Python开发的一个快速、高层次的web数据抓取框架,用于抓取web站点并从页面中提取结构化的数据。Scrapy用途广泛,可以用于数据挖掘和监测。
Scrapy吸引人的地方在于它是一个框架,任何人都可以根据需求方便的修改。它也提供了多种类型爬虫的基类,如BaseSpider、sitemap爬虫等。
Scrapy算得上是Python世界中最常用的爬虫框架了,同时它也是我掌握的几种流行语言中最好的爬虫框架,没有之一!我认为它也是最难学习的框架,同样没有之一。很多初学Scarpy的经常向我抱怨完全不清楚Scrapy该怎样入手,即使看的是中文的文档,也感到很难理解。我当初接触Scrapy时也有这样的感觉。之所以感到Scrapy难学,究其原因,是其官方文档实在太过凌乱,又缺少实用的代码例子,让人看得云里雾里,不知其所已然。虽然其文档不良,但却没有遮挡住它的光辉,它依然是Python世界中目前最好用的爬虫框架。其架构的思路、蜘蛛执行的效能,还有可扩展的能力都非常出众,再配以Python语言的简洁轻巧,使得爬虫的开发事半功倍。
相关推荐:《Python基础教程》
Scrapy的优点:
(1)提供了内置的HTTP缓存,以加速本地开发。
(2)提供了自动节演调节机制,而且具有遵守robots.txt的设置的能力。
(3)可以定义爬行深度的限制,以避免爬虫进入死循环链接。
(4)会自动保留会话。
(5)执行自动HTTP基本认证。不需要明确保存状态。
(6)可以自动填写登录表单。
(7)Scrapy有一个内置的中间件,可以自动设置请求中的引用(referrer)头。
(8)支持通过3xx响应重定向,也可以通过HTML元刷新。
(9)避免被网站使用的meta重定向困住,以检测没有JS支持的页面。
(10)默认使用CSS选择器或XPath编写解析器。
(11)可以通过Splash或任何其他技术(如Selenium)呈现JavaScript页面。
(12)拥有强大的社区支持和丰富的插件和扩展来扩展其功能。
(13)提供了通用的蜘蛛来抓取常见的格式:站点地图、CSV和XML。
(14)内置支持以多种格式(JSON、CSV、XML、JSON-lines)导出收集的数据并将其存在多个后端(FTP、S3、本地文件系统)中。
Scrapy框架原理
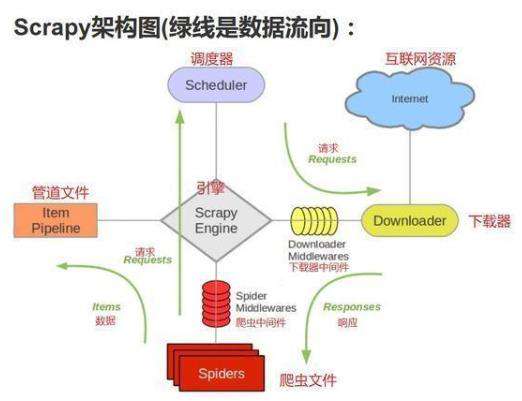
Scrapy Engine(引擎):负责Spider、ItemPipeline、Downloader、Scheduler中间的通讯,信号、数据传递等。
Scheduler(调度器):负责接收引擎发送过来的Request请求,并按照一定的方式进行整理排列,入队,当引擎需要时,交还给引擎。
Downloader(下载器):负责下载Scrapy Engine(引擎)发送的所有Requests请求,并将其获取到的Responses交还给Scrapy Engine(引擎),由引擎交给Spider来处理,
Spider(爬虫):负责处理所有Responses,从中分析提取数据,获取Item字段需要的数据,并将需要跟进的URL提交给引擎,再次进入Scheduler(调度器),
Item Pipeline(管道):负责处理Spider中获取到的Item,并进行进行后期处理(详细分析、过滤、存储等)的地方.
Downloader Middlewares(下载中间件):你可以当作是一个可以自定义扩展下载功能的组件。
Spider Middlewares(Spider中间件):你可以理解为是一个可以自定扩展和操作引擎和Spider中间通信的功能组件(比如进入Spider的Responses;和从Spider出去的Requests)
Scrapy各个组件介绍
·Scrapy Engine:
引擎负责控制数据流在系统中所有组件中流动,并在相应动作发生时触发事件。它也是程序的入口,可以通过scrapy指令方式在命令行启动,或普通编程方式实例化后调用start方法启动。
·调度器(Scheduler)
调度器从引擎接收爬取请求(Request)并将它们入队,以便之后引擎请求它们时提供给引擎。一般来说,我们并不需要直接对调度器进行编程,它是由Scrapy主进程进行自动控制的。
·下载器(Down-loader)
下载器负责获取页面数据并提供给引擎,而后将网站的响应结果对象提供给蜘蛛(Spider)。具体点说,下载器负责处理产生最终发出的请求对象 Request 并将返回的响应生成 Response对象传递给蜘蛛。
·蜘蛛——Spiders
Spider是用户编写用于分析响应(Response)结果并从中提取Item(即获取的Item)或额外跟进的URL的类。每个Spider负责处理一个特定(或一些)网站。
·数据管道——Item Pipeline
Item Pipeline 负责处理被 Spider 提取出来的 Item。 典型的处理有清理、验证及持久化(例如,存取到数据库中)。
·下载器中间件(Downloader middle-wares)
下载器中间件是在引擎及下载器之间的特定钩子(specific hook),处理Downloader传递给引擎的Response。其提供了一个简便的机制,通过插入自定义代码来扩展Scrapy的功能。
·Spider中间件(Spider middle-wares)
Spider 中间件是在引擎及 Spider 之间的特定钩子(specific hook),处理 Spider 的输入(Response)和输出(Items及Requests)。其提供了一个简便的机制,通过插入自定义代码来扩展Scrapy的功能。
从Scrapy的系统架构可见,它将整个爬网过程进行了非常具体的细分,并接管了绝大多数复杂的工作,例如,产生请求和响应对象、控制爬虫的并发等。
常见问题FAQ
- 免费下载或者VIP会员专享资源能否直接商用?
- 本站所有资源版权均属于原作者所有,这里所提供资源均只能用于参考学习用,请勿直接商用。若由于商用引起版权纠纷,一切责任均由使用者承担。更多说明请参考 VIP介绍。
- 提示下载完但解压或打开不了?
- 找不到素材资源介绍文章里的示例图片?
- 模板不会安装或需要功能定制以及二次开发?





发表评论
还没有评论,快来抢沙发吧!