
无论是py2还是py3,都使用unicode作为内存编码,简称内码。保存在python解释器内存中的文本,输出到屏幕、编辑器,或者保存成文件的时候,都要将内码转换成utf8或者gbk等编码格式;同样,python解释器从输入设备接收文本,或者从文件读取文本的时候,都要将utf8或者gbk等编码转换成unicode编码格式。
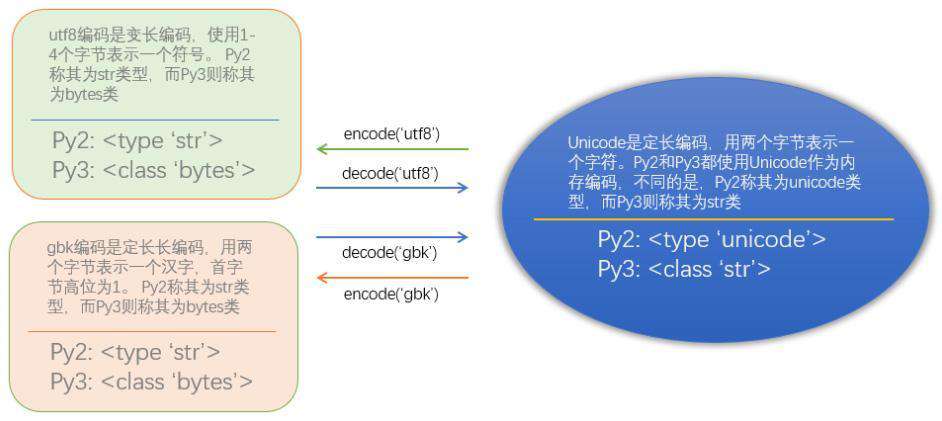
因此,无论是py2还是py3,想要在unicode、utf8、gbk等编码格式之间转换的话,下图是通用的:
我们之所以会产生困惑,是因为py2和py3给这些编码格式指定了令人困惑的名字。
py2的字符串有两种类型:unicode类型和str类型。
py2的unicode类型就是unicode编码,py2的str类型泛指除unicode编码之外的所有编码,包括ascii编码、utf8编码、gbk编码、cp936编码等。
py3的字符串也有两种类型:bytes类型和str类型。py3的str类型就是unicode编码,py3的bytes类型泛指除unicode编码之外的所有编码,包括ascii编码、utf8编码、gbk编码、cp936编码等。
同样是str类型,在py2和py3中完全颠倒了!下图稍微补充了一点内容,更有助于理解编码问题。
接下来,我们实战演练一下。
>>> s = 'abc天圆地方'
>>> type(s)
<class 'str'>
>>> len(s)
7
>>> s
'abc天圆地方'
>>> print(s)
abc天圆地方
>>> s.encode('unicode-escape')
b'abc\\u5929\\u5706\\u5730\\u65b9'不管是否在字符串前面加了u,只要不在字符串前面使用b,在IDLE中定义的字符串都是unicode编码,也就是py3的<class ‘str’>,其长度就是字符数量,不是字节数。我们把unicode字符串’abc天圆地方’转成utf8编码:
>>> s_utf8 = s.encode('utf8')
>>> type(s_utf8)
<class 'bytes'>
>>> len(s_utf8)
15
>>> s_utf8
b'abc\xe5\xa4\xa9\xe5\x9c\x86\xe5\x9c\xb0\xe6\x96\xb9'
>>> print(s_utf8)
b'abc\xe5\xa4\xa9\xe5\x9c\x86\xe5\x9c\xb0\xe6\x96\xb9'
>>> s_utf8.decode('utf8')
'abc天圆地方'utf8编码就是bytes类型(字节码),长度就是字节数量。我们把unicode字符串’abc天圆地方’转成gbk编码:
>>> s_gbk= s.encode('gbk')
>>> type(s_gbk)
<class 'bytes'>
>>> len(s_gbk)
11
>>> s_gbk
b'abc\xcc\xec\xd4\xb2\xb5\xd8\xb7\xbd'
>>> print(s_gbk)
b'abc\xcc\xec\xd4\xb2\xb5\xd8\xb7\xbd'
>>> s_gbk.decode('s_gbk')
'abc天圆地方'gbk编码也是bytes类型(字节码),长度也是字节数量。我们再来看看,不同编码的字节码能否连接:
>>> ss = s_utf8 + s_gbk
>>> ss
b'abc\xe5\xa4\xa9\xe5\x9c\x86\xe5\x9c\xb0\xe6\x96\xb9abc\xcc\xec\xd4\xb2\xb5\xd8\xb7\xbd'
>>> ss.decode('utf8')
Traceback (most recent call last):
File "<pyshell#64>", line 1, in <module>
ss.decode('utf8')
UnicodeDecodeError: 'utf-8' codec can't decode byte 0xcc in position 18: invalid continuation byte
>>> ss.decode('gbk')
'abc澶╁渾鍦版柟abc天圆地方'
>>> ss.decode('utf8', 'ignore')
'abc天圆地方abcԲط'
>>> ss.decode('gbk', 'ignore')
'abc澶╁渾鍦版柟abc天圆地方'看以看出,不同编码的字节码可以连接,但一般不能解码成unicode(字符串),除非使用ignore参数。
python学习网,免费的在线学习python平台,欢迎关注!
常见问题FAQ
- 免费下载或者VIP会员专享资源能否直接商用?
- 本站所有资源版权均属于原作者所有,这里所提供资源均只能用于参考学习用,请勿直接商用。若由于商用引起版权纠纷,一切责任均由使用者承担。更多说明请参考 VIP介绍。
- 提示下载完但解压或打开不了?
- 找不到素材资源介绍文章里的示例图片?
- 模板不会安装或需要功能定制以及二次开发?





发表评论
还没有评论,快来抢沙发吧!