
用爬虫来实现自动签到算是爬虫里一种比较简单的应用,但不妨碍它很实用。
有哪些应用场景
自动签到的应用场景非常多,比如贴吧签到、论坛签到、网站打卡,甚至于我接下来会使用到的应用场景:健身房打卡。
由于疫情影响,我平常去的那家健身房停业了近3个月,于是推出了一个算是比较苛刻的补偿措施或者说是活动,连续在网站打卡4个月可以额外赠送4个月时长。
也算是过滤一下平常就不怎么去健身的人吧,但是对大部分经常去的人就很不友好,本来就忙还得天天惦记着给他打卡。作为一只程序猿能让这点小事难住了?
什么是selenium
selenium 是一个用于Web应用程序测试的工具。Selenium测试直接运行在浏览器中,就像真正的用户在操作一样。
支持的浏览器包括IE(7, 8, 9, 10, 11),Mozilla Firefox,Safari,Google Chrome,Opera等。selenium 是一套完整的web应用程序测试系统,包含了测试的录制(selenium IDE),编写及运行(Selenium Remote Control)和测试的并行处理(Selenium Grid)。
selenium可以模拟真实浏览器,自动化测试工具,支持多种浏览器,爬虫中主要用来解决JavaScript渲染问题
简单来说,selenium是一个可以让你用代码来模拟操作浏览器的工具。先附上一段代码体验一下
from selenium import webdriver#导入库 browser = webdriver.Chrome()#声明浏览器 url = 'https:www.baidu.com' browser.get(url)#打开浏览器预设网址 print(browser.page_source)#打印网页源代码 browser.close()#关闭浏览器
上述代码运行后,会自动打开Chrome浏览器,并登陆百度打印百度首页的源代码,然后关闭浏览器。是不是简单明了。
安装也非常简单,跟安装其他Python库一样
pip install selenium
网页分析
写爬虫避不开的一步就是分析页面,先附上要爬的网页链接
这是一个手机端的web页面,并没有做针对电脑端的优化,这也是我首先会选择用selenium实现的其中一个原因。
1、首先就是网页登录
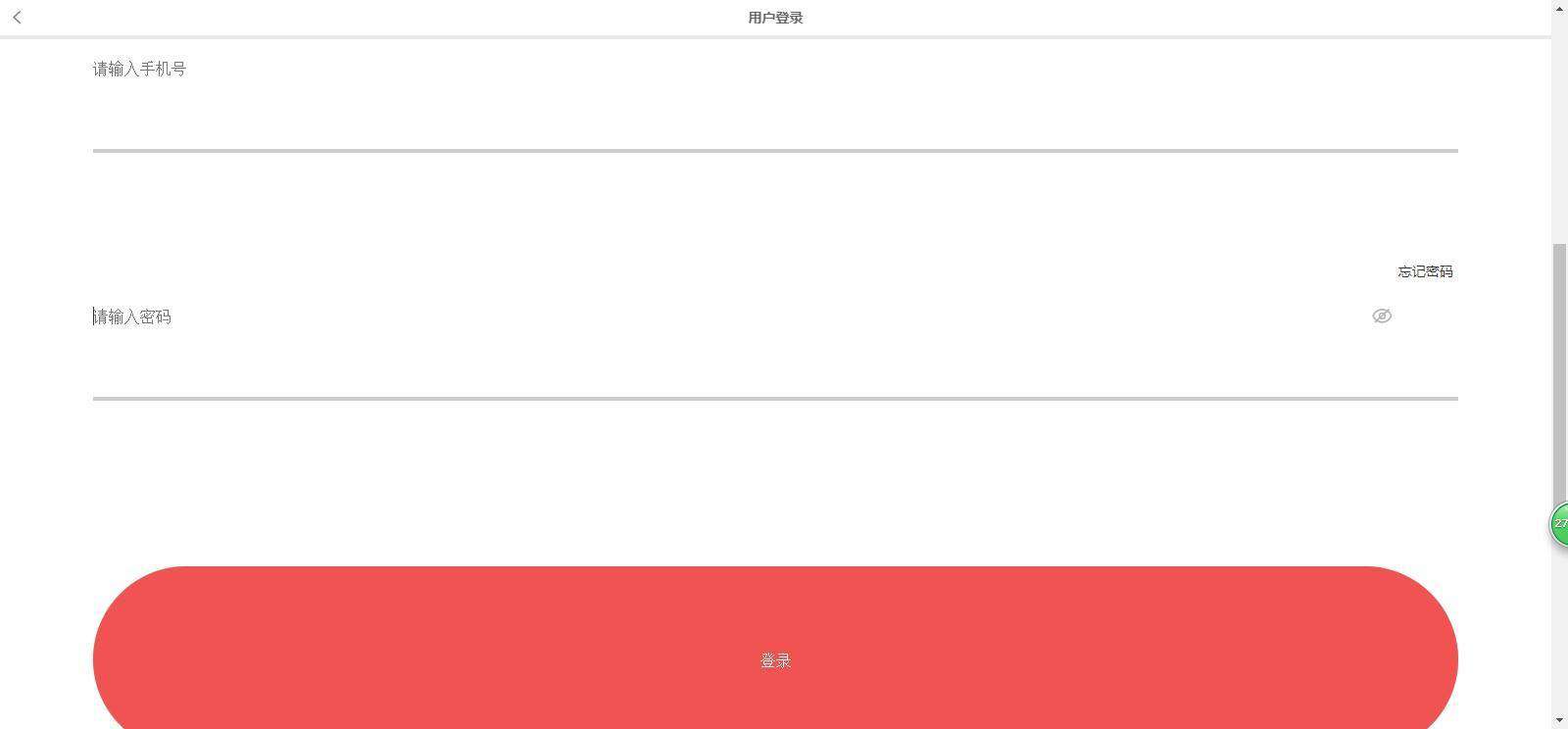
两个输入框加一个按钮总共三行代码就能搞定
# 这里是找到输入框,发送要输入的用户名和密码,模拟登陆
browser.find_element_by_xpath('//*[@id="login_box"]/ul/li[1]/div/input').send_keys(username)
browser.find_element_by_xpath('//*[@id="login_box"]/ul/li[2]/div/input').send_keys(password)
# 在输入用户名和密码之后,点击登陆按钮
browser.find_element_by_xpath('//*[@id="login_box"]/div[2]/button[1]').click()我用的是xpath的方式定位页面元素,除此之外selenium支持很多种方式定位元素,比如
browser.find_element_by_class_name() browser.find_element_by_css_selector() browser.find_element_by_id() browser.find_element_by_name()
但不得不说,xpath+Chrome的组合实在是太香了。
再之后的操作就没有什么难度了,无非是继续选择元素,点击,跳转,点击。需要注意的一点就是要合理的运用selenium的等待来使网页的点击和跳转之间更加平滑。
selenium的三种等待方式
1、强制等待
第一种是最简单也是最粗暴的方式——强制等待。time.sleep(2) 不管浏览器有没有加载完,都要等3秒。
刚开始可以先用这种方式让程序先跑起来,之后再优化。
2、隐性等待
第二种方式叫隐性等待,implicitly_wait(xx)
隐形等待是设置了一个最长等待时间,如果在规定时间内网页加载完成,则执行下一步,否则一直等到时间截止,然后执行下一步。
注意这里有一个弊端,那就是程序会一直等待整个页面加载完成,也就是一般情况下你看到浏览器标签栏那个小圈不再转,
才会执行下一步,但有时候页面想要的元素早就在加载完成了,
但是因为个别js之类的东西特别慢,我仍得等到页面全部完成才能执行下一步,我想等我要的元素出来之后就下一步怎么办?有办法,这就要看selenium提供的另一种等待方式——显性等待了。
3、显性等待
第三种办法就是显性等待,WebDriverWait,配合该类的until()和until_not()方法,
就能够根据判断条件而进行灵活地等待了。它主要的意思就是:程序每隔xx秒看一眼,如果条件成立了,则执行下一步,否则继续等待,直到超过设置的最长时间,然后抛出TimeoutException。
具体应用到代码中如下:
from selenium.webdriver.support import expected_conditions as EC locator = (By.XPATH, '//*[@id="login_box"]/ul/li[1]/div/input') WebDriverWait(browser, 3, 0.3).until(EC.presence_of_element_located(locator))
WebDriverWait类长这样:
class WebDriverWait(object):
def __init__(self, driver, timeout, poll_frequency=POLL_FREQUENCY, ignored_exceptions=None):
"""Constructor, takes a WebDriver instance and timeout in seconds.
:Args:
- driver - Instance of WebDriver (Ie, Firefox, Chrome or Remote)
- timeout - Number of seconds before timing out
- poll_frequency - sleep interval between calls
By default, it is 0.5 second.
- ignored_exceptions - iterable structure of exception classes ignored during calls.
By default, it contains NoSuchElementException only.
Example:
from selenium.webdriver.support.ui import WebDriverWait \n
element = WebDriverWait(driver, 10).until(lambda x: x.find_element_by_id("someId")) \n
is_disappeared = WebDriverWait(driver, 30, 1, (ElementNotVisibleException)).\ \n
until_not(lambda x: x.find_element_by_id("someId").is_displayed())
"""until
method: 在等待期间,每隔一段时间调用这个传入的方法,直到返回值不是False
message: 如果超时,抛出TimeoutException,将message传入异常
until_not
与until相反,until是当某元素出现或什么条件成立则继续执行,
until_not是当某元素消失或什么条件不成立则继续执行,参数也相同,不再赘述。
最终实现
知道了上面那些,就可以把我们的代码优化一下,用显性等待替换掉time模块。最终代码如下:
# username = "xxxxxx"
# password = "xxxxxx"
# 模拟浏览器打开网站
def AutoSign(username, password):
chrome_options = Options()
# 使用无界面浏览器
chrome_options.add_argument('--headless')
browser = webdriver.Chrome(options=chrome_options)
browser.get(url)
locator = (By.XPATH, '//*[@id="login_box"]/ul/li[1]/div/input')
# 延时2秒,以便网页加载所有元素,避免之后找不到对应的元素
# time.sleep(2)
WebDriverWait(browser, 3, 0.3).until(EC.presence_of_element_located(locator))
# 这里是找到输入框,发送要输入的用户名和密码,模拟登陆
browser.find_element_by_xpath('//*[@id="login_box"]/ul/li[1]/div/input').send_keys(username)
browser.find_element_by_xpath('//*[@id="login_box"]/ul/li[2]/div/input').send_keys(password)
# 在输入用户名和密码之后,点击登陆按钮
browser.find_element_by_xpath('//*[@id="login_box"]/div[2]/button[1]').click()
WebDriverWait(browser, 3, 0.3).until(EC.visibility_of_element_located((By.ID, 'name-a')))
time.sleep(0.5)
browser.execute_script("window.scrollTo(0,1000);")
# 点击登陆后的页面中的签到,跳转到签到页面
browser.find_element_by_xpath('//*[@id="member"]/div[6]/div/div[2]/div[1]/div/div/h3').click()
# time.sleep(1)
# browser.execute_script("window.scrollTo(0,1000);")
# time.sleep(1)
browser.find_element_by_xpath('//*[@id="member"]/div[6]/div/div[2]/div[2]/div/div/a[1]/div').click()
# time.sleep(2)
WebDriverWait(browser, 2, 0.3).until(
EC.presence_of_element_located((By.XPATH, '//*[@id="sign"]/div[3]/div')))
# 点击签到,实现功能
browser.find_element_by_xpath('//*[@id="sign"]/div[3]/div').click()
time.sleep(0.5)
# 这个print其实没什么用,如果真的要测试脚本是否运行成功,可以用try来抛出异常
print("签到成功")
# 脚本运行成功,退出浏览器
browser.quit()上面代码中所有的condition和poll_frequency需要根据实际网页加载情况包括网络状况灵活调整,以便找到最优解。
更多Python知识,请关注Python视频教程!!
常见问题FAQ
- 免费下载或者VIP会员专享资源能否直接商用?
- 本站所有资源版权均属于原作者所有,这里所提供资源均只能用于参考学习用,请勿直接商用。若由于商用引起版权纠纷,一切责任均由使用者承担。更多说明请参考 VIP介绍。
- 提示下载完但解压或打开不了?
- 找不到素材资源介绍文章里的示例图片?
- 模板不会安装或需要功能定制以及二次开发?





发表评论
还没有评论,快来抢沙发吧!