之前跟大家说过使用python可以进行图片下载,后来,小伙伴们亲自实践以后,纷纷表示可以实现图片的下载,但是随之而来的又有新的问题,就是关于下载后的图片不知道怎么去保存,但是有些较为聪明的小伙伴已经寻求到方法了,对此,小编还是给大家整理一番。
1.导入的包
l time包,用来设置间隔时间,防止把网页爬崩(要是真的爬崩了我估计要倒大霉喽)
l requess包,当然是用来获取网页的源代码和处理相应的啦
l BeautifulSoup包,用来对网页内容进行准确的抓取,具体的使用方法以后我会写道
l os包,文件处理最重要最常用的包,用来创建文件名等
2. 抓取网页的源代
3. 对网页进行解析,从中获取自己想要的图片链接
4. 保存下载的图片
代码演示:
#保存图片,思路:将所有的图片保存在本地的一个文件夹下,用图片的url链接的后缀名来命名
dir_name = 'teacherImage' #设置文件夹的名字
if not os.path.exists(dir_name): #os模块判断并创建
os.mkdir(dir_name)
for img_url in urlInfo:
time.sleep(1) #设置间隔时间,防止把网页爬崩
picture_name = img_url.split('/')[-1] #提取图片url后缀
reponse = requests.get(img_url)
with open(dir_name+'/'+picture_name,'wb') as f:
f.write(reponse.content)5.实现结果
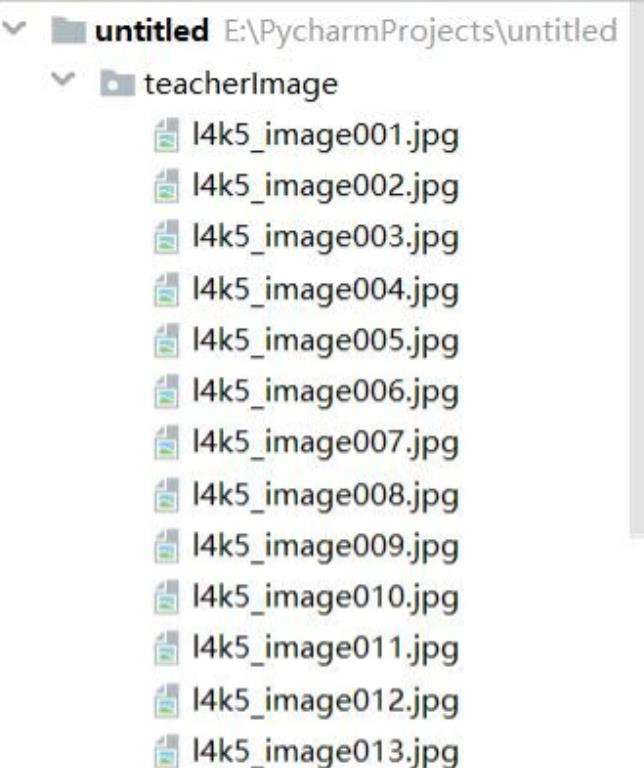
好啦,小伙伴们可以根据上篇文章内容,先下载出图片,然后根据下面保存方式,进行图片保存,一套完美的下载保存图片就呈现给大家啦~
常见问题FAQ
- 免费下载或者VIP会员专享资源能否直接商用?
- 本站所有资源版权均属于原作者所有,这里所提供资源均只能用于参考学习用,请勿直接商用。若由于商用引起版权纠纷,一切责任均由使用者承担。更多说明请参考 VIP介绍。
- 提示下载完但解压或打开不了?
- 找不到素材资源介绍文章里的示例图片?
- 模板不会安装或需要功能定制以及二次开发?





发表评论
还没有评论,快来抢沙发吧!