
pyspider 用法详解
前面我们了解了 pyspider 的基本用法,我们通过非常少的代码和便捷的可视化操作就完成了一个爬虫的编写,本节我们来总结一下它的详细用法。
1. 命令行
上面的实例通过如下命令启动 pyspider:
pyspider all
命令行还有很多可配制参数,完整的命令行结构如下所示:
pyspider [OPTIONS] COMMAND [ARGS]
其中,OPTIONS 为可选参数,它可以指定如下参数。
Options: -c, --config FILENAME 指定配置文件名称 --logging-config TEXT 日志配置文件名称,默认: pyspider/pyspider/logging.conf --debug 开启调试模式 --queue-maxsize INTEGER 队列的最大长度 --taskdb TEXT taskdb 的数据库连接字符串,默认: sqlite --projectdb TEXT projectdb 的数据库连接字符串,默认: sqlite --resultdb TEXT resultdb 的数据库连接字符串,默认: sqlite --message-queue TEXT 消息队列连接字符串,默认: multiprocessing.Queue --phantomjs-proxy TEXT PhantomJS 使用的代理,ip:port 的形式 --data-path TEXT 数据库存放的路径 --version pyspider 的版本 --help 显示帮助信息
例如,-c 可以指定配置文件的名称,这是一个常用的配置,配置文件的样例结构如下所示:
{
"taskdb": "mysql+taskdb://username:password@host:port/taskdb",
"projectdb": "mysql+projectdb://username:password@host:port/projectdb",
"resultdb": "mysql+resultdb://username:password@host:port/resultdb",
"message_queue": "amqp://username:password@host:port/%2F",
"webui": {
"username": "some_name",
"password": "some_passwd",
"need-auth": true
}
}如果要配置 pyspider WebUI 的访问认证,可以新建一个 pyspider.json,内容如下所示:
{
"webui": {
"username": "root",
"password": "123456",
"need-auth": true
}
}这样我们通过在启动时指定配置文件来配置 pyspider WebUI 的访问认证,用户名为 root,密码为 123456,命令如下所示:
pyspider -c pyspider.json all
运行之后打开:http://localhost:5000/,页面如 12-26 所示:
图 12-26 运行页面
也可以单独运行 pyspider 的某一个组件。
运行 Scheduler 的命令如下所示:
pyspider scheduler [OPTIONS]
运行时也可以指定各种配置,参数如下所示:
Options: --xmlrpc /--no-xmlrpc --xmlrpc-host TEXT --xmlrpc-port INTEGER --inqueue-limit INTEGER 任务队列的最大长度,如果满了则新的任务会被忽略 --delete-time INTEGER 设置为 delete 标记之前的删除时间 --active-tasks INTEGER 当前活跃任务数量配置 --loop-limit INTEGER 单轮最多调度的任务数量 --scheduler-cls TEXT Scheduler 使用的类 --help 显示帮助信息
运行 Fetcher 的命令如下所示:
pyspider fetcher [OPTIONS]
参数配置如下所示:
Options: --xmlrpc /--no-xmlrpc --xmlrpc-host TEXT --xmlrpc-port INTEGER --poolsize INTEGER 同时请求的个数 --proxy TEXT 使用的代理 --user-agent TEXT 使用的 User-Agent --timeout TEXT 超时时间 --fetcher-cls TEXT Fetcher 使用的类 --help 显示帮助信息
运行 Processer 的命令如下所示:
pyspider processor [OPTIONS]
参数配置如下所示:
Options: --processor-cls TEXT Processor 使用的类 --help 显示帮助信息
运行 WebUI 的命令如下所示:
pyspider webui [OPTIONS]
参数配置如下所示:
Options: --host TEXT 运行地址 --port INTEGER 运行端口 --cdn TEXT JS 和 CSS 的 CDN 服务器 --scheduler-rpc TEXT Scheduler 的 xmlrpc 路径 --fetcher-rpc TEXT Fetcher 的 xmlrpc 路径 --max-rate FLOAT 每个项目最大的 rate 值 --max-burst FLOAT 每个项目最大的 burst 值 --username TEXT Auth 验证的用户名 --password TEXT Auth 验证的密码 --need-auth 是否需要验证 --webui-instance TEXT 运行时使用的 Flask 应用 --help 显示帮助信息
这里的配置和前面提到的配置文件参数是相同的。如果想要改变 WebUI 的端口为 5001,单独运行如下命令:
pyspider webui --port 5001
或者可以将端口配置到 JSON 文件中,配置如下所示:
{
"webui": {"port": 5001}
}使用如下命令启动同样可以达到相同的效果:
pyspider -c pyspider.json webui
这样就可以在 5001 端口上运行 WebUI 了。
2. crawl() 方法
在前面的例子中,我们使用 crawl() 方法实现了新请求的生成,但是只指定了 URL 和 Callback。这里将详细介绍一下 crawl() 方法的参数配置。
url
url 是爬取时的 URL,可以定义为单个 URL 字符串,也可以定义成 URL 列表。
callback
callback 是回调函数,指定了该 URL 对应的响应内容用哪个方法来解析,如下所示:
def on_start(self):
self.crawl('http://scrapy.org/', callback=self.index_page)这里指定了 callback 为 index_page,就代表爬取 http://scrapy.org/ 链接得到的响应会用 index_page() 方法来解析。
index_page() 方法的第一个参数是响应对象,如下所示:
def index_page(self, response): pass
方法中的 response 参数就是请求上述 URL 得到的响应对象,我们可以直接在 index_page() 方法中实现页面的解析。
age
age 是任务的有效时间。如果某个任务在有效时间内且已经被执行,则它不会重复执行,如下所示:
def on_start(self):
self.crawl('http://www.example.org/', callback=self.callback,
age=10*24*60*60)或者可以这样设置:
@config(age=10 * 24 * 60 * 60) def callback(self): pass
默认的有效时间为 10 天。
priority
priority 是爬取任务的优先级,其值默认是 0,priority 的数值越大,对应的请求会越优先被调度,如下所示:
def index_page(self):
self.crawl('http://www.example.org/page.html', callback=self.index_page)
self.crawl('http://www.example.org/233.html', callback=self.detail_page,
priority=1)第二个任务会优先调用,233.html 这个链接优先爬取。
exetime
exetime 参数可以设置定时任务,其值是时间戳,默认是 0,即代表立即执行,如下所示:
import time
def on_start(self):
self.crawl('http://www.example.org/', callback=self.callback,
exetime=time.time()+30*60)这样该任务会在 30 分钟之后执行。
retries
retries 可以定义重试次数,其值默认是 3。
itag
itag 参数设置判定网页是否发生变化的节点值,在爬取时会判定次当前节点是否和上次爬取到的节点相同。如果节点相同,则证明页面没有更新,就不会重复爬取,如下所示:
def index_page(self, response):
for item in response.doc('.item').items():
self.crawl(item.find('a').attr.url, callback=self.detail_page,
itag=item.find('.update-time').text())在这里设置了更新时间这个节点的值为 itag,在下次爬取时就会首先检测这个值有没有发生变化,如果没有变化,则不再重复爬取,否则执行爬取。
auto_recrawl
当开启时,爬取任务在过期后会重新执行,循环时间即定义的 age 时间长度,如下所示:
def on_start(self):
self.crawl('http://www.example.org/', callback=self.callback,
age=5*60*60, auto_recrawl=True)这里定义了 age 有效期为 5 小时,设置了 auto_recrawl 为 True,这样任务就会每 5 小时执行一次。
method
method 是 HTTP 请求方式,它默认是 GET。如果想发起 POST 请求,可以将 method 设置为 POST。
params
我们可以方便地使用 params 来定义 GET 请求参数,如下所示:
def on_start(self):
self.crawl('http://httpbin.org/get', callback=self.callback,
params={'a': 123, 'b': 'c'})
self.crawl('http://httpbin.org/get?a=123&b=c', callback=self.callback)这里两个爬取任务是等价的。
data
data 是 POST 表单数据。当请求方式为 POST 时,我们可以通过此参数传递表单数据,如下所示:
def on_start(self):
self.crawl('http://httpbin.org/post', callback=self.callback,
method='POST', data={'a': 123, 'b': 'c'})files
files 是上传的文件,需要指定文件名,如下所示:
def on_start(self):
self.crawl('http://httpbin.org/post', callback=self.callback,
method='POST', files={field: {filename: 'content'}})user_agent
user_agent 是爬取使用的 User-Agent。
headers
headers 是爬取时使用的 Headers,即 Request Headers。
cookies
cookies 是爬取时使用的 Cookies,为字典格式。
connect_timeout
connect_timeout 是在初始化连接时的最长等待时间,它默认是 20 秒。
timeout
timeout 是抓取网页时的最长等待时间,它默认是 120 秒。
allow_redirects
allow_redirects 确定是否自动处理重定向,它默认是 True。
validate_cert
validate_cert 确定是否验证证书,此选项对 HTTPS 请求有效,默认是 True。
proxy
proxy 是爬取时使用的代理,它支持用户名密码的配置,格式为 username:password@hostname:port,如下所示:
def on_start(self):
self.crawl('http://httpbin.org/get', callback=self.callback, proxy='127.0.0.1:9743')也可以设置 craw_config 来实现全局配置,如下所示:
class Handler(BaseHandler):
crawl_config = {'proxy': '127.0.0.1:9743'}fetch_type
fetch_type 开启 PhantomJS 渲染。如果遇到 JavaScript 渲染的页面,指定此字段即可实现 PhantomJS 的对接,pyspider 将会使用 PhantomJS 进行网页的抓取,如下所示:
def on_start(self):
self.crawl('https://www.taobao.com', callback=self.index_page, fetch_type='js')这样我们就可以实现淘宝页面的抓取了,得到的结果就是浏览器中看到的效果。
js_script
js_script 是页面加载完毕后执行的 JavaScript 脚本,如下所示:
def on_start(self):
self.crawl('http://www.example.org/', callback=self.callback,
fetch_type='js', js_script='''
function() {window.scrollTo(0,document.body.scrollHeight);
return 123;
}
''')页面加载成功后将执行页面混动的 JavaScript 代码,页面会下拉到最底部。
js_run_at
js_run_at 代表 JavaScript 脚本运行的位置,是在页面节点开头还是结尾,默认是结尾,即 document-end。
js_viewport_width/js_viewport_height
js_viewport_width/js_viewport_height 是 JavaScript 渲染页面时的窗口大小。
load_images
load_images 在加载 JavaScript 页面时确定是否加载图片,它默认是否。
save
save 参数非常有用,可以在不同的方法之间传递参数,如下所示:
def on_start(self):
self.crawl('http://www.example.org/', callback=self.callback,
save={'page': 1})
def callback(self, response):
return response.save['page']这样,在 on_start() 方法中生成 Request 并传递额外的参数 page,在回调函数里可以通过 response 变量的 save 字段接收到这些参数值。
cancel
cancel 是取消任务,如果一个任务是 ACTIVE 状态的,则需要将 force_update 设置为 True。
force_update
即使任务处于 ACTIVE 状态,那也会强制更新状态。
以上便是 crawl() 方法的参数介绍,更加详细的描述可以参考:http://docs.pyspider.org/en/latest/apis/self.crawl/。
3. 任务区分
在 pyspider 判断两个任务是否是重复的是使用的是该任务对应的 URL 的 MD5 值作为任务的唯一 ID,如果 ID 相同,那么两个任务就会判定为相同,其中一个就不会爬取了。很多情况下请求的链接可能是同一个,但是 POST 的参数不同。这时可以重写 task_id() 方法,改变这个 ID 的计算方式来实现不同任务的区分,如下所示:
import json
from pyspider.libs.utils import md5string
def get_taskid(self, task):
return md5string(task['url']+json.dumps(task['fetch'].get('data', '')))这里重写了 get_taskid() 方法,利用 URL 和 POST 的参数来生成 ID。这样一来,即使 URL 相同,但是 POST 的参数不同,两个任务的 ID 就不同,它们就不会被识别成重复任务。
4. 全局配置
pyspider 可以使用 crawl_config 来指定全局的配置,配置中的参数会和 crawl() 方法创建任务时的参数合并。如要全局配置一个 Headers,可以定义如下代码:
class Handler(BaseHandler):
crawl_config = {
'headers': {'User-Agent': 'GoogleBot',}
}5. 定时爬取
我们可以通过 every 属性来设置爬取的时间间隔,如下所示:
@every(minutes=24 * 60) def on_start(self): for url in urllist: self.crawl(url, callback=self.index_page)
这里设置了每天执行一次爬取。
在上文中我们提到了任务的有效时间,在有效时间内爬取不会重复。所以要把有效时间设置得比重复时间更短,这样才可以实现定时爬取。
例如,下面的代码就无法做到每天爬取:
@every(minutes=24 * 60)
def on_start(self):
self.crawl('http://www.example.org/', callback=self.index_page)
@config(age=10 * 24 * 60 * 60)
def index_page(self):
pass这里任务的过期时间为 10 天,而自动爬取的时间间隔为 1 天。当第二次尝试重新爬取的时候,pyspider 会监测到此任务尚未过期,便不会执行爬取,所以我们需要将 age 设置得小于定时时间。
6. 项目状态
每个项目都有 6 个状态,分别是 TODO、STOP、CHECKING、DEBUG、RUNNING、PAUSE。
TODO:它是项目刚刚被创建还未实现时的状态。
STOP:如果想停止某项目的抓取,可以将项目的状态设置为 STOP。
CHECKING:正在运行的项目被修改后就会变成 CHECKING 状态,项目在中途出错需要调整的时候会遇到这种情况。
DEBUG/RUNNING:这两个状态对项目的运行没有影响,状态设置为任意一个,项目都可以运行,但是可以用二者来区分项目是否已经测试通过。
PAUSE:当爬取过程中出现连续多次错误时,项目会自动设置为 PAUSE 状态,并等待一定时间后继续爬取。
7. 抓取进度
在抓取时,可以看到抓取的进度,progress 部分会显示 4 个进度条,如图 12-27 所示。
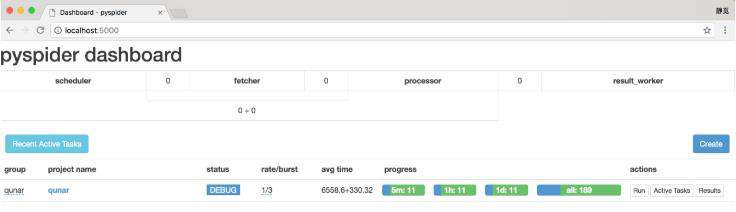
图 12-27 抓取进度
progress 中的 5m、1h、1d 指的是最近 5 分、1 小时、1 天内的请求情况,all 代表所有的请求情况。
蓝色的请求代表等待被执行的任务,绿色的代表成功的任务,黄色的代表请求失败后等待重试的任务,红色的代表失败次数过多而被忽略的任务,从这里我们可以直观看到爬取的进度和请求情况。
8. 删除项目
pyspider 中没有直接删除项目的选项。如要删除任务,那么将项目的状态设置为 STOP,将分组的名称设置为 delete,等待 24 小时,则项目会自动删除。
9. 结语
以上内容便是 pyspider 的常用用法。如要了解更多,可以参考 pyspider 的官方文档:http://docs.pyspider.org/。
众多python培训视频,尽在python学习网,欢迎在线学习!
本文转自:https://cuiqingcai.com/8320.html
常见问题FAQ
- 免费下载或者VIP会员专享资源能否直接商用?
- 本站所有资源版权均属于原作者所有,这里所提供资源均只能用于参考学习用,请勿直接商用。若由于商用引起版权纠纷,一切责任均由使用者承担。更多说明请参考 VIP介绍。
- 提示下载完但解压或打开不了?
- 找不到素材资源介绍文章里的示例图片?
- 模板不会安装或需要功能定制以及二次开发?





发表评论
还没有评论,快来抢沙发吧!