
在跟一群小伙伴探讨完乱码的问题后,小编发现了各式各样的获取方法,当然乱码的问题也是蜂拥而来,都让小编觉得出错比找数据不要太容易了。小编近期一直在收集大家的问题,不断地更新整理后分享给大家,希望更多的小伙伴看到后都知道该如何去解决,今天就python爬虫乱码是文字方块的解决办法。
在解析网页时,时常可以看到如下情景:

这种情况下,我们需要的仅仅是数字,则需要找到相应的字体对应规则。
首先,转码,将字符串转为bytes类型:
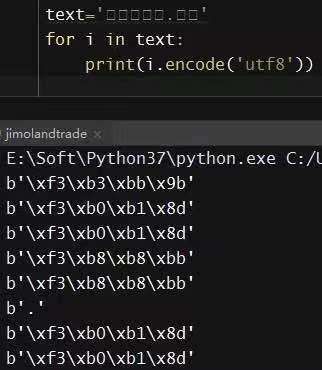
然后,根据0~9各个字符的bytes类型编码,建立对应词典,示例中这个网站的网页载入有点贱嘻嘻,弄了三套对应的转换模式,现在也不知道是否每天还会更新,反正人肉分别将30个bytes类型编码与字符串做对应,用数组或者字典皆可。
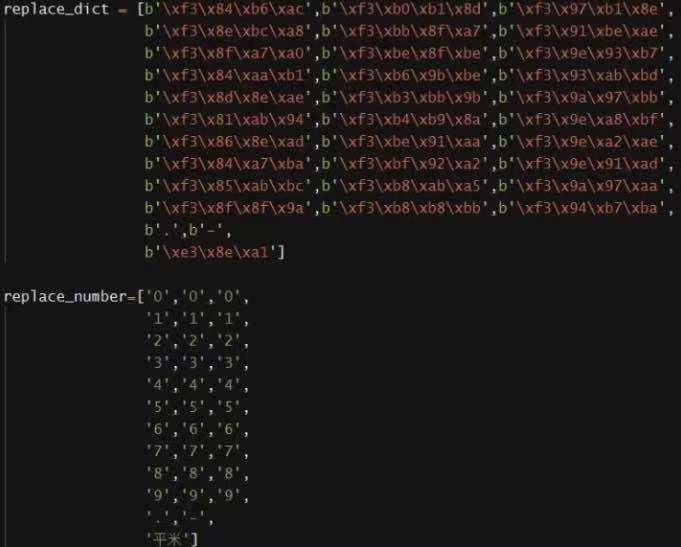
最后就可以根据内容来进行转码了。
上面说到这是有限的解决方案,原因在于,如果网站实行动态加密,那可能就要去看具体的js内容了,再就是有的可能是图片,可能需要OCR来进行辅助。
在爬相应的网站的时候,友好起见,我使用了selenium+chromedriver,载入后,再刷新一次,效果更好,说的好像刷新一次以后,就不是机器人了一样哈哈。
小伙伴们看完也可以试试小编这种办法,如果是出现其他类型的乱码现象,也可以去往期的文章找一找。更多Python学习推荐:起源地模板网教学中心。
常见问题FAQ
- 免费下载或者VIP会员专享资源能否直接商用?
- 本站所有资源版权均属于原作者所有,这里所提供资源均只能用于参考学习用,请勿直接商用。若由于商用引起版权纠纷,一切责任均由使用者承担。更多说明请参考 VIP介绍。
- 提示下载完但解压或打开不了?
- 找不到素材资源介绍文章里的示例图片?
- 模板不会安装或需要功能定制以及二次开发?





发表评论
还没有评论,快来抢沙发吧!