
在学习了python爬虫模块后,小编对于获取数据的方法仿佛打开了新的思路。方法之间没有哪种可以不局限于所有的使用环境,小编在每次写的时候都会注明使用,小伙伴们看的时候需要留意,不然运行后弄出乌龙就尴尬了。下面我们一起来看看xpath是如何在python爬虫中抓取信息的吧。
我们使用xpath语法来提取我们所需的信息。 不熟悉xpath语法的自行学习一下,很快就能上手,难度不高。 首先我们在chrome浏览器里进入豆瓣电影TOP250页面并按F12打开开发者工具。
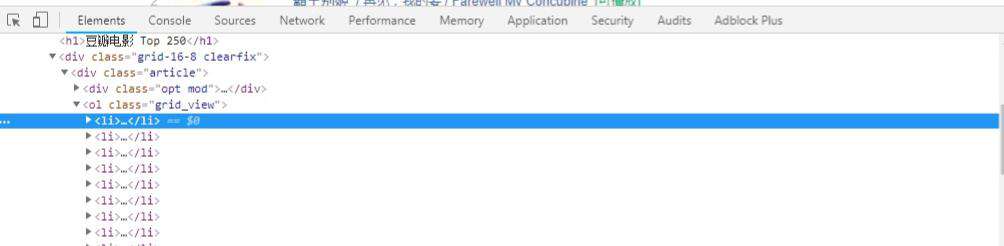
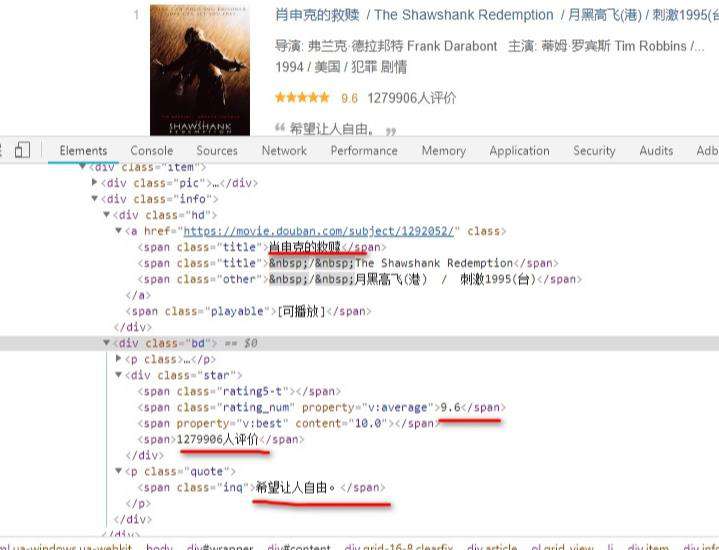
我们可以看到每一部电影的信息都在一个<li>...<li>里,打开后可以找到我们想要的全部信息,其中spider中初始的request是通过调用 start_requests() 来获取的。 start_requests() 读取 start_urls 中的URL, 并以 parse 为回调函数生成 Request。看一下代码:
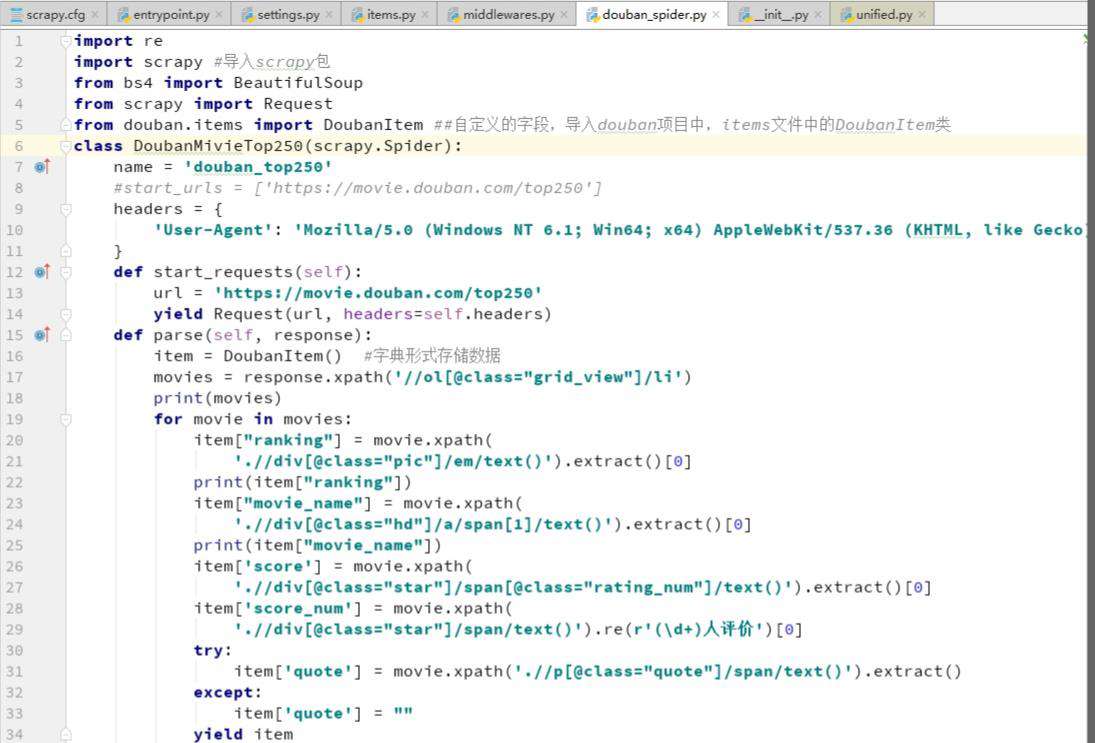
以上就是xpath语言在python爬虫中抓取信息的方法了,没想到小小的语法还有这么多的作用吧。更多Python学习推荐:起源地模板网教学中心。
常见问题FAQ
- 免费下载或者VIP会员专享资源能否直接商用?
- 本站所有资源版权均属于原作者所有,这里所提供资源均只能用于参考学习用,请勿直接商用。若由于商用引起版权纠纷,一切责任均由使用者承担。更多说明请参考 VIP介绍。
- 提示下载完但解压或打开不了?
- 找不到素材资源介绍文章里的示例图片?
- 模板不会安装或需要功能定制以及二次开发?





发表评论
还没有评论,快来抢沙发吧!