
爬虫又称为网页蜘蛛,是一种程序或脚本。
但重点在于,它能够按照一定的规则,自动获取网页信息。
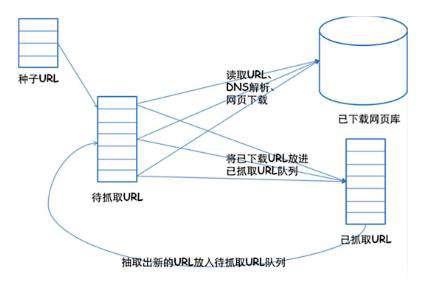
爬虫的基本原理——通用框架
1.挑选种子URL;
2.讲这些URL放入带抓取的URL列队;
3.取出带抓取的URL,下载并存储进已下载网页库中。此外,讲这些URL放入带抓取URL列队,进入下一循环。
4.分析已抓取列队中的URL,并且将URL放入带抓取URL列队,从而进去下一循环。
爬虫获取网页信息和人工获取信息,其实原理是一致的。
如我们要获取电影的“评分”信息

人工操作步骤:
1.获取电影信息的网页;
2.定位(找到)要评分信息的位置;
3.复制、保存我们想要的评分数据。
爬虫操作步骤:
1.请求并下载电影页面信息;
2.解析并定位评分信息;
3.保存评分数据。
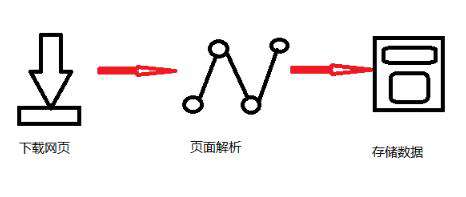
爬虫的基本流程
简单来说,我们向服务器发送请求后,会得到返回的页面,通过解析页面后,我们可以抽取我们想要的那部分信息,并存储在指定文档或数据库中,这样,我们想要的信息会被我们“爬”下来了。
python中用于爬虫的包很多,如bs4,urllib,requests等等。这里我们用requests+xpath的方式,因为简单易学,像BeautifulSoup还是有点难的。
下面我们就使用requests和xpath来爬取豆瓣电影中的“电影名”、“导演”、“演员”、“评分”等信息。
安装requests和lxml库:
pip install requests pip install lxml
一、导入模块
#-*- coding:utf-8 -*- import requests from lxml import etree import time #这里导入时间模块,以免豆瓣封你IP
二、获取豆瓣电影目标网页并解析
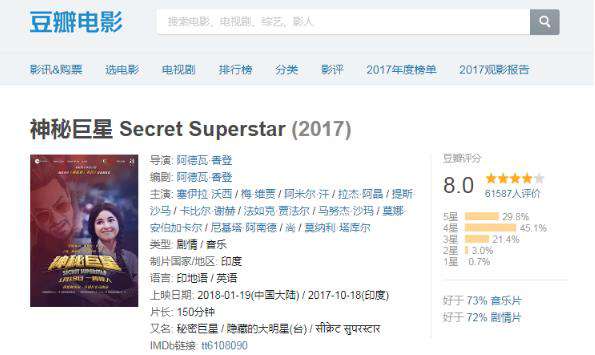
爬取豆瓣电影《神秘巨星》上的一些信息,地址
https://movie.douban.com/subject/26942674/?from=showing
#-*- coding:utf-8 -*- import requests from lxml import etree import time url = 'https://movie.douban.com/subject/26942674/' data = requests.get(url).text s=etree.HTML(data) #给定url并用requests.get()方法来获取页面的text,用etree.HTML() #来解析下载的页面数据“data”。
1.获取电影名称。
获取电影的xpath信息并获得文本
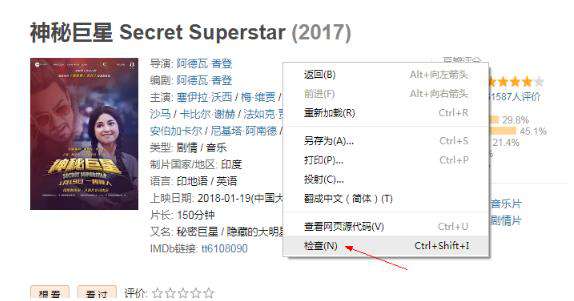
s.xpath('元素的xpath信息/text()')这里的xpath信息要手动获取,获取方式如下:
1.如果你是用谷歌浏览器的话,鼠标“右键”–>“检查元素”;
2.Ctrl+Shift+C将鼠标定位到标题;
3.“右键”–>“Copy”–>“Copy Xpath”就可以复制xpath。
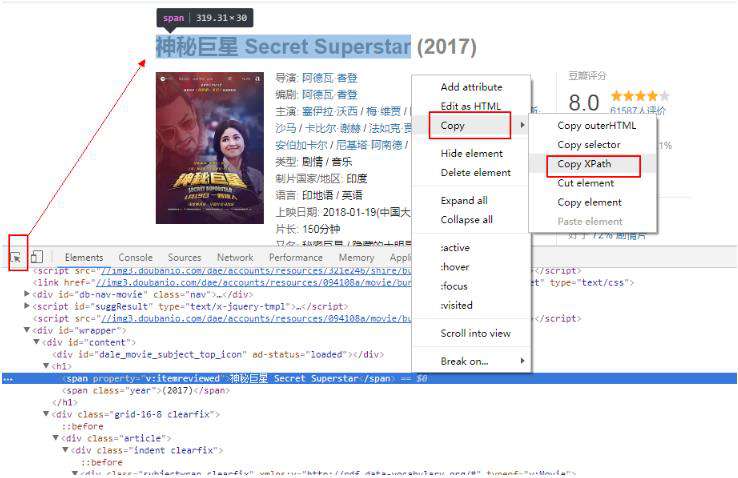
这样,我们就把电影标题的xpath信息复制下来了。
//*[@id="content"]/h1/span[1]
放到代码中并打印信息
#-*- coding:utf-8 -*-
import requests
from lxml import etree
import time
url = 'https://movie.douban.com/subject/26942674/'
data = requests.get(url).text
s=etree.HTML(data)
film_name = s.xpath('//*[@id="content"]/h1/span[1]/text()')
print("电影名:",film_name)这样,我们爬取豆瓣电影中《神秘巨星》的“电影名称”信息的代码已经完成了,可以在eclipse中运行代码。
得到如下结果:
电影名: ['神秘巨星 Secret Superstar']
OK,迈出了第一步,我们继续抓取导演、主演、评分;
film_name=s.xpath('//*[@id="content"]/h1/span[1]/text()')#电影名
director=s.xpath('//*[@id="info"]/span[1]/span[2]/a/text()')#编剧
actor1=s.xpath('//*[@id="info"]/span[3]/span[2]/a[1]/text()')#主演1
actor2=s.xpath('//*[@id="info"]/span[3]/span[2]/a[2]/text()')#主演2
actor3=s.xpath('//*[@id="info"]/span[3]/span[2]/a[3]/text()')#主演3
actor4=s.xpath('//*[@id="info"]/span[3]/span[2]/a[4]/text()')#主演4
movie_time=s.xpath('//*[@id="info"]/span[13]/text()')#片长观察上面的代码,发现获取不同主演时,区别只在于“a[x]”中“x”的值不同。实际上,要一次性获取所有主演信息时,用不加数字的“a”即可获取。
如下:
actors = s.xpath('//*[@id="info"]/span[3]/span[2]/a/text()')#所有主演所以我们修改好的完整代码如下:
#-*- coding:utf-8 -*-
import requests
from lxml import etree
import time
url1 = 'https://movie.douban.com/subject/26942674/'
data = requests.get(url1).text
s=etree.HTML(data)
film_name=s.xpath('//*[@id="content"]/h1/span[1]/text()')#电影名
director=s.xpath('//*[@id="info"]/span[1]/span[2]/a/text()')#编剧
actor=s.xpath('//*[@id="info"]/span[3]/span[2]/a/text()')#主演
movie_time=s.xpath('//*[@id="info"]/span[13]/text()')#片长
#由于导演有时候不止一个人,所以我这里以列表的形式输出
ds = []
for d in director:
ds.append(d)
#由于演员不止一个人,所以我这里以列表的形式输出
acs = []
for a in actor:
acs.append(a)
print ('电影名:',film_name)
print ('导演:',ds)
print ('主演:',acs)
print ('片长:',movie_time)结果输出:
电影名: ['神秘巨星 Secret Superstar'] 导演: ['阿德瓦·香登'] 主演: ['塞伊拉·沃西', '梅·维贾', '阿米尔·汗', '拉杰·阿晶', '提斯·沙马', '卡比尔·谢赫', '法如克·贾法尔', '马努杰·沙玛', '莫娜·安伯加卡尔', '尼基塔·阿南德', '尚', '莫纳利·塔库尔'] 片长: ['150分钟']
怎么样,是不是很简单啊。赶快去试试吧~~~
这里顺便补充点基础知识:
Requests常用的七种方法:
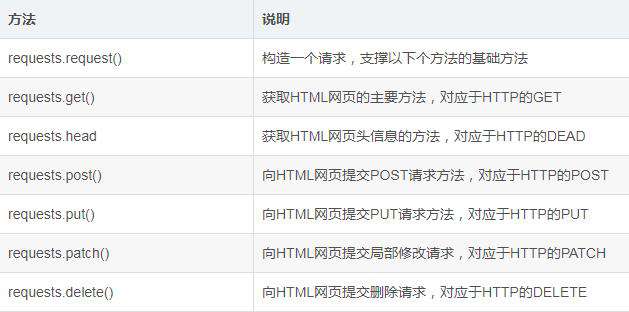
目前,我们只需要掌握最常用的requests.get()方法就好了。
requests.get()的使用方法
import requests url = 'https://www.baidu.com' data = requests.get(url)#使用get方法发送请求,返回汗网页数据的Response并存储到对象data 中
Repsonse对象的属性:
data.status_code:http请求的返回状态,200表示连接成功;
data.text:返回对象的文本内容;
data.content:猜测返回对象的二进制形式;
data.encoding:返回对象的编码方式;
data.apparent_encoding:响应内容编码方式。
众多python培训视频,尽在python学习网,欢迎在线学习!
本文转自:https://blog.csdn.net/mtbaby/article/details/79165890
常见问题FAQ
- 免费下载或者VIP会员专享资源能否直接商用?
- 本站所有资源版权均属于原作者所有,这里所提供资源均只能用于参考学习用,请勿直接商用。若由于商用引起版权纠纷,一切责任均由使用者承担。更多说明请参考 VIP介绍。
- 提示下载完但解压或打开不了?
- 找不到素材资源介绍文章里的示例图片?
- 模板不会安装或需要功能定制以及二次开发?





发表评论
还没有评论,快来抢沙发吧!