
pyspider 框架介绍
pyspider 是由国人 binux 编写的强大的网络爬虫系统,其 GitHub 地址为 https://github.com/binux/pyspider,官方文档地址为 http://docs.pyspider.org/。
pyspider 带有强大的 WebUI、脚本编辑器、任务监控器、项目管理器以及结果处理器,它支持多种数据库后端、多种消息队列、JavaScript 渲染页面的爬取,使用起来非常方便。
1. pyspider 基本功能
我们总结了一下,PySpider 的功能有如下几点。
提供方便易用的 WebUI 系统,可以可视化地编写和调试爬虫。
提供爬取进度监控、爬取结果查看、爬虫项目管理等功能。
支持多种后端数据库,如 MySQL、MongoDB、Redis、SQLite、Elasticsearch、PostgreSQL。
支持多种消息队列,如 RabbitMQ、Beanstalk、Redis、Kombu。
提供优先级控制、失败重试、定时抓取等功能。
对接了 PhantomJS,可以抓取 JavaScript 渲染的页面。
支持单机和分布式部署,支持 Docker 部署。
如果想要快速方便地实现一个页面的抓取,使用 pyspider 不失为一个好的选择。
2. 与 Scrapy 的比较
后面会介绍另外一个爬虫框架 Scrapy,我们学习完 Scrapy 之后会更容易理解此部分内容。我们先了解一下 pyspider 与 Scrapy 的区别。
pyspider 提供了 WebUI,爬虫的编写、调试都是在 WebUI 中进行的,而 Scrapy 原生是不具备这个功能的,采用的是代码和命令行操作,但可以通过对接 Portia 实现可视化配置。
pyspider 调试非常方便,WebUI 操作便捷直观,在 Scrapy 中则是使用 parse 命令进行调试,论方便程度不及 pyspider。
pyspider 支持 PhantomJS 来进行 JavaScript 渲染页面的采集,在 Scrapy 中可以对接 ScrapySplash 组件,需要额外配置。
PySpide r 中内置了 PyQuery 作为选择器,在 Scrapy 中对接了 XPath、CSS 选择器和正则匹配。
pyspider 的可扩展程度不足,可配制化程度不高,在 Scrapy 中可以通过对接 Middleware、Pipeline、Extension 等组件实现非常强大的功能,模块之间的耦合程度低,可扩展程度极高。
如果要快速实现一个页面的抓取,推荐使用 pyspider,开发更加便捷,如快速抓取某个普通新闻网站的新闻内容。如果要应对反爬程度很强、超大规模的抓取,推荐使用 Scrapy,如抓取封 IP、封账号、高频验证的网站的大规模数据采集。
3. pyspider 的架构
pyspider 的架构主要分为 Scheduler(调度器)、Fetcher(抓取器)、Processer(处理器)三个部分,整个爬取过程受到 Monitor(监控器)的监控,抓取的结果被 Result Worker(结果处理器)处理,如图 12-1 所示。
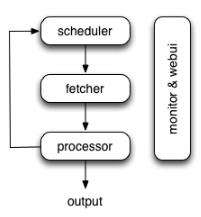
图 12-1 pyspider 架构图
Scheduler 发起任务调度,Fetcher 负责抓取网页内容,Processer 负责解析网页内容,然后将新生成的 Request 发给 Scheduler 进行调度,将生成的提取结果输出保存。
pyspider 的任务执行流程的逻辑很清晰,具体过程如下所示。
每个 pyspider 的项目对应一个 Python 脚本,该脚本中定义了一个 Handler 类,它有一个 on_start() 方法。爬取首先调用 on_start() 方法生成最初的抓取任务,然后发送给 Scheduler 进行调度。
Scheduler 将抓取任务分发给 Fetcher 进行抓取,Fetcher 执行并得到响应,随后将响应发送给 Processer。
Processer 处理响应并提取出新的 URL 生成新的抓取任务,然后通过消息队列的方式通知 Schduler 当前抓取任务执行情况,并将新生成的抓取任务发送给 Scheduler。如果生成了新的提取结果,则将其发送到结果队列等待 Result Worker 处理。
Scheduler 接收到新的抓取任务,然后查询数据库,判断其如果是新的抓取任务或者是需要重试的任务就继续进行调度,然后将其发送回 Fetcher 进行抓取。
不断重复以上工作,直到所有的任务都执行完毕,抓取结束。
抓取结束后,程序会回调 on_finished() 方法,这里可以定义后处理过程。
4. 结语
本节我们主要了解了 pyspider 的基本功能和架构。接下来我们会用实例来体验一下 pyspider 的抓取操作,然后总结它的各种用法。
python学习网,大量的免费python视频教程,欢迎在线学习!
本文转自:https://cuiqingcai.com/8309.html
常见问题FAQ
- 免费下载或者VIP会员专享资源能否直接商用?
- 本站所有资源版权均属于原作者所有,这里所提供资源均只能用于参考学习用,请勿直接商用。若由于商用引起版权纠纷,一切责任均由使用者承担。更多说明请参考 VIP介绍。
- 提示下载完但解压或打开不了?
- 找不到素材资源介绍文章里的示例图片?
- 模板不会安装或需要功能定制以及二次开发?





发表评论
还没有评论,快来抢沙发吧!