
我们平时都是看到网页打开的样子,那么有没有小伙伴见过网页最本来的样子?其实最开始网页诞生的时候只是一些源码,我们上网页浏览的时候是不会看到的。看到的都是网页制作者想让我们看到的样子。今天我们回归本源,一起来看一下网页的源码是什么样子,在操作方法上会使用Python爬虫的知识。
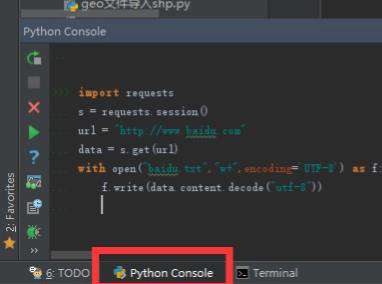
直接上代码:
import requests
s = requests.session()
url = "http://www.baidu.com"
data = s.get(url)
with open("baidu.txt","w+",encoding='UTF-8') as f:
f.write(data.content.decode("utf-8"))import requests 把这个工具箱拿过来。
s = requests.session() 其中的一个工具取个短名,就叫s。
url = "http://www.baidu.com" 这是我们要测试的地址,主要http://不能省。用双引号包起来说明是个字符串。
data = s.get(url) s.get(url)就是让程序去访问网站,拿到源码了,拿到的源码命名为data。
with open("baidu.txt","w+",encoding='UTF-8') as f:源码拿到了我们又看不见,很抽象,很难受,我当时是喜欢把它们写到文档里再研究;所以创建个baidu.txt(用完整的路径也行)的文档,w+模式打开,文件编码是UTF-8,告诉程序这个文件里面写的是中文,不是俄语。as f,让这个文件打开后代号为f,对f的操作就是对文件的操作。
f.write(data.content.decode("utf-8")) 对f执行write操作,写入的内容是获取的源码data中的content;
data是requests.Session.get返回的一整坨东西,是一个结构体,不是能写入文本文件的字符串,所以要用里面的content。.decode("utf-8") 意思是把鸟语翻译成格式为”utf-8”中文再写进去。
这些代码可以直接复制到Python Console回车就可以执行;会再py文件所在路径或者你自己设定的baidu.txt的路径生成一个baidu.txt的文件;打开就可以看到源码。
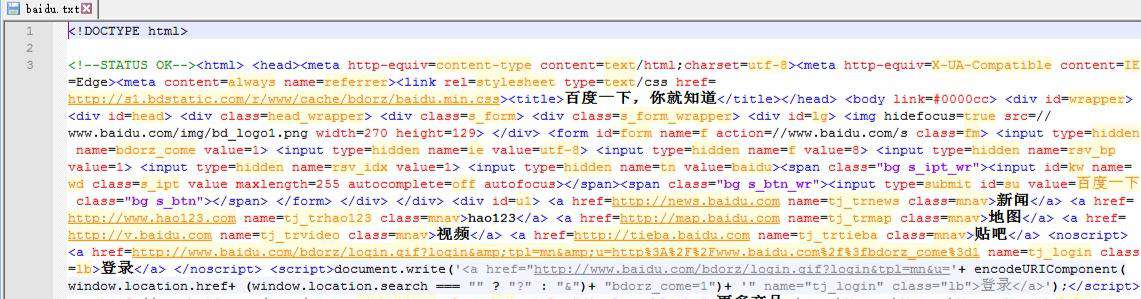
看起来挤在一起有点难受,不过源码的结果就是这样。相信看着这个图片,小伙伴们对源码又有了直观的了解。更多Python学习推荐:起源地模板网教学中心。
常见问题FAQ
- 免费下载或者VIP会员专享资源能否直接商用?
- 本站所有资源版权均属于原作者所有,这里所提供资源均只能用于参考学习用,请勿直接商用。若由于商用引起版权纠纷,一切责任均由使用者承担。更多说明请参考 VIP介绍。
- 提示下载完但解压或打开不了?
- 找不到素材资源介绍文章里的示例图片?
- 模板不会安装或需要功能定制以及二次开发?





发表评论
还没有评论,快来抢沙发吧!