最近上新了不少新电影,也不知道哪一个电影好看,我们可以使用python爬虫获取数据来分析一下。这里我们把整体获取的流程分为需求分析和代码部分,下面小伙伴们就一起来看看怎样使用python爬虫获取电影票房数据吧。
1.简单需求分析
一边觉得可以把验证码取下来填上去获取cookies,另一边觉得可以先登录再取cookies,当然他们都成功了。
唯独用selenium去登录取cookies的爬下来是乱码。
2.代码实现
import requests
import re
from lxml import etree
import random
from concurrent.futures import ThreadPoolExecutor
import time
user_agent=[
# 请自己放上十几个头
]
#下面的cookie自己加,建议加多个
cookie=[]
list_urls=[]
def geturl(page):
headers={
'Cookie':random.choice(cookie),
'User-Agent':random.choice(user_agent)
}
time.sleep(1)
page = requests.get("http://58921.com/alltime?page={}".format(int(page)),headers=headers)
html = page.content.decode(encoding='utf-8')
with open("test.html",'wb') as f:
f.write(html.encode())
xpath_data=etree.HTML(page.content)
list_urls_raw=xpath_data.xpath('//*[@id="content"]/div[3]/table/tbody/tr/td[3]/a/@href')
# print(list_urls_raw)
for url in list_urls_raw:
list_urls.append(url)
return list_urls
def get_number(url_half):
headers={
'User-Agent':random.choice(user_agent)
}
Html=requests.get("http://58921.com"+url_half+"/boxoffice",headers).content.decode("utf-8")
# print(Html)
pattern_number = re.compile(r'\(最新票房 (.+?)\)')
pattern_name=re.compile(r'<h3>(.*)票房统计\(.*\)</h3>')
# print(pattern)
number=pattern_number.findall(Html)[0]
name=pattern_name.findall(Html)[0]
print(number,name)
return number,name
with ThreadPoolExecutor(max_workers=2) as executor_first:
for i in range(1,30): # 要几页自己调
executor_first.submit(geturl,i)
print(list_urls)
print(len(list_urls))
with ThreadPoolExecutor(max_workers=2) as executor_second:
executor_second.map(get_number,list_urls)成果
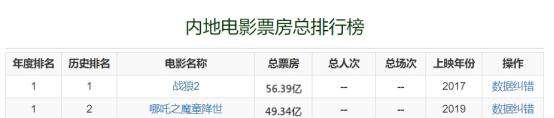
以上就是python爬虫获取电影票房数据的办法,感兴趣的小伙伴也可以跟着小编的流程试一试。本文来源于网络,如有雷同联系作者修改。
常见问题FAQ
- 免费下载或者VIP会员专享资源能否直接商用?
- 本站所有资源版权均属于原作者所有,这里所提供资源均只能用于参考学习用,请勿直接商用。若由于商用引起版权纠纷,一切责任均由使用者承担。更多说明请参考 VIP介绍。
- 提示下载完但解压或打开不了?
- 找不到素材资源介绍文章里的示例图片?
- 模板不会安装或需要功能定制以及二次开发?





发表评论
还没有评论,快来抢沙发吧!