
在不断学习python的过程中,想必大家也在各种论坛之类的地方看过了python大神。虽然我们暂时还不能像他们那么厉害,但是模仿和学习的过程总是不会停止的。作为一颗也有八卦心理的小编,特别想知道厉害的编程大神都喜欢用哪些头像,所以想借助python来收集一下他们的头像,感兴趣的小伙伴也可以一下看看。
一:请求头(headers)
每个网站的请求头都会不一样,但爬取得网站,都有例子,大家在不初期,跟着选就行
Authorization:HTTP授权的授权证书
User-Agent:代表你用哪种浏览器
X-UDID:一串验证码
二:真实的urls
异步加载中,真实的url并非https://www.zhihu.com/people/feifeimao/followers,真正的url需要我们通过抓包获取,流程如图:
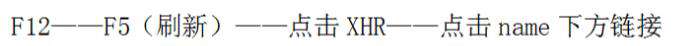
所以我们得出真实url:
https://www.zhihu.com/api/v4/members/feifeimao/followers?include=data%5B*%5D.answer_count%2Carticles_count%2Cgender%2Cfollower_count%2Cis_followed%2Cis_following%2Cbadge%5B%3F(type%3Dbest_answerer)%5D.topics&offset=20&limit=20
通过加载更多,我们发现url中start随之同步变化,变化的间隔为20,即offset=20(第一页),start=40(第二页),以此类推,所以我们得出.format(i*20),大家可以对比第三篇的翻页。
三:img_url
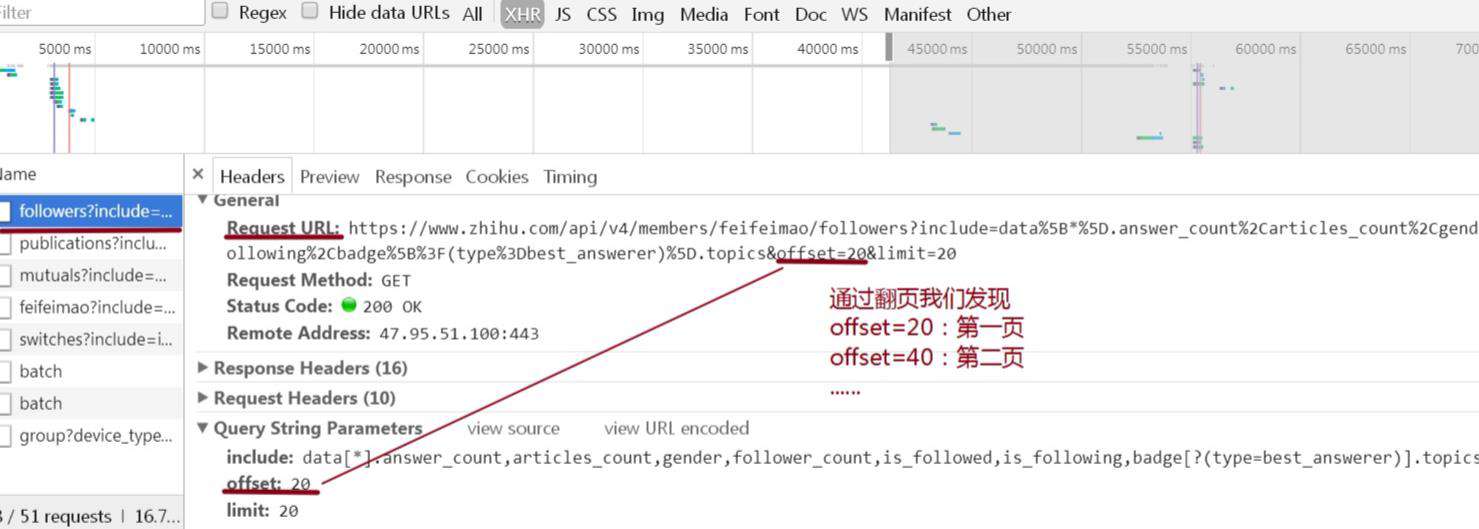
我们抓取的img的url需要有序的排列,即采用append函数,依次把他们放入img_url。
四:json
之前我们用得.text是需要网页返回文本的信息,而这里返回的是json文件,所以用.json
json结构很清晰,大家一层一层选取就好了
取出字典中的值,需要在方括号中指明值对应的键
以下为全部代码:
# -*- coding: utf-8 -*-
import requests
import json
from urllib.request import urlretrieve
headers = {'authorization':'Bearer Mi4xQXN3S0F3QUFBQUFBUUVJSjdTempDaGNBQUFCaEFsVk5BQzRmV3dDVVJzeU9NOWxNU0pZT1BNdFJ5bTlrSzk3MU1B|1513218048|1e03f7e7f26825482a72e4a629ef80292847548e',
'User-Agent':'Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/55.0.2883.87 Safari/537.36',
'x-udid':'AEBCCe0s4wqPToZZF6LV3roAjT8uEikZF1k=',
} #请求头
urls = ['https://www.zhihu.com/api/v4/members/feifeimao/followers?include=data%5B*%5D.answer_count%2Carticles_count%2Cgender%2Cfollower_count%2Cis_' \
'followed%2Cis_following%2Cbadge%5B%3F(type%3Dbest_answerer)%5D.topics&offset={}&limit=20'.format(i*20) for i in range (0,5)]
img_urls = [] #用来存所有的img_url
for url in urls:
datas = requests.get(url,headers = headers).json()['data'] #获取json文件下的data
for it in datas:
img_url = it['avatar_url'] #获取头像url
img_urls.append(img_url) #把获取的url依次放入img_urls
i = 0 #计数
for it in img_urls:
urlretrieve(it,'D://%s.jpg' % i) #通过url,依次下载头像,并保存于D盘
i = i+1 #i依次累加看完前面分析爬虫收集头像思路的小伙伴,就可以动手尝试结尾的代码啦。我们不光要学会写代码,在对处理问题的解决思路上也同样要有独立的思考能力哦~更多Python学习推荐:起源地模板网教学中心。
常见问题FAQ
- 免费下载或者VIP会员专享资源能否直接商用?
- 本站所有资源版权均属于原作者所有,这里所提供资源均只能用于参考学习用,请勿直接商用。若由于商用引起版权纠纷,一切责任均由使用者承担。更多说明请参考 VIP介绍。
- 提示下载完但解压或打开不了?
- 找不到素材资源介绍文章里的示例图片?
- 模板不会安装或需要功能定制以及二次开发?





发表评论
还没有评论,快来抢沙发吧!